
Welcome to “How to Tuesday” in the VRO Heroes Den. To kick off the month of March we will be highlighting a “How to series” for getting started and leveraging Veeam Recovery Orchestrator! Everyone is welcome to participate - so if you have a “how to tutorial” that you would like to share on VRO feel free to post here on Tuesday’s! Winners will get a badge and some Kudos from
In this VRO How to series – we will explore how to get started with Veeam Recovery Orchestrator for designing business continuity and disaster recovery strategies. There are four parts of this series starting with Part 1; with how to prep your environment before installation.
What is Veeam Recovery Orchestrator?
Before we start deploying Veeam Recovery Orchestrator we need to have a base understanding of what it is and the components running behind the scenes as well as the workloads we are going to be protecting. Veeam Recovery Orchestrator (VRO) is part of the Veeam Data Platform – Premium Edition. It compliments Veeam Backup & Replication by automating the recovery process and validating that the SLA’s a business designed will be valid during a recovery attempt. You can build different recovery plans based off data protection strategies for CDP Replication, VM replication, Storage Replication, and Recovery from backups for VMs, Windows, and Linux Agents. There are reporting templates included in Orchestrator that will dynamically update once a recovery plan is created. These reports can be saved, emailed, and shared as PDF or Word. The benefit of having Orchestrator is not only for the extensive documentation it can create for recovery plans but the ability to test these recovery plans to validate that they will work when you need them the most. Let’s begin with the VRO core architecture components.
Architecture: Veeam Recovery Orchestrator runs on a separate Windows domain joined (a workgroup in v7) machine that can be virtual or physical. This is beneficial as you can design for recovery and ensure that your orchestration server is well protected on a separate site limiting the chance of failure due to the production site being unavailable. The setup account used must be a domain user with local administrator permissions on the target machine. On this machine all orchestrator components can be installed which are:
- Veeam Orchestrator Server Service — is responsible for managing orchestration plans and administering user roles and permissions.
- Veeam Orchestrator Web UI — is a web-based user interface that allows users to interact with the Veeam Orchestrator Server Service, and to perform various configuration and administration actions. In the Orchestrator UI, orchestration plans are designed, checked, tested, and executed.
- Veeam Backup & Replication Server — is installed with the Orchestrator server to supply Veeam PowerShell libraries and support certain disaster recovery scenarios. It is referred to as an "embedded" server.
- Veeam ONE Server — handles the Veeam ONE Business View engine to gather inventory. It is referred to as an "embedded" server.
- SQL Server — is used to host configuration data. Microsoft SQL Server Enterprise edition is recommended due to sizing limitations with SQL Express, which may be a remote server.
For typical connection settings on the machine using the embedded Veeam Backup & Replication Server and VeeamONE you can refer to this port list in the user guide -> Ports (Important note, the server must be able to access/connect to vCenter)
- Orchestrator Agent – the agent will allow us to have access to previously configured Veeam Backup & Replication server’s protection policies and its machines. It will trigger orchestration commands on the remote server for the protected machines. You can add the Veeam Backup & Replication server specifically or by Veeam Enterprise Manager server for multiple server deployment.
To delegate control within Orchestrator there are three roles that can be assigned via Windows Active Directory and user groups to allow specific actions. These roles are put in place to help larger organizations to assign user responsibility to different data recovery tasks.
- Administrator — can perform all administration actions and can also act as a Plan Author and Plan Operator.
- Plan Author — can enable, disable, reset, create, edit and test plans.
- Plan Operator — can perform readiness checks, test, schedule, and run plans that are enabled.
Deployment and Data Protection Scenarios
Now that we know what pre-requisites and components are needed to install Orchestrator, we need to think about the type of DR we want to plan for. Orchestrator supports multiple types of deployment scenarios, but for this series we are only going to focus on the four that can be found in help center documentation. If your goal is to achieve the lowest Recovery Point Objective (RPO) and Recovery Time Objective (RTO) scenario 1 will be a great fit. Keep in mind these scenarios are not limited to only one, as you can use them in conjunction with each other depending on the DR event.
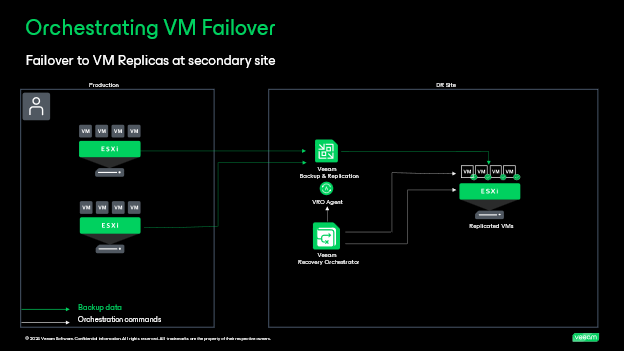
Scenario 1: Orchestrating recovery based on vSphere VM replicas created by Veeam Backup & Replication. In this scenario, virtual machines running in production are replicated to a secondary site in a ready to start state. The type of replication utilized can be either Continuous Data Protection (CDP) Replication or VM snapshot-based replication. With CDP replica’s a near-zero recovery point objective (RPO) can be reached as no snapshots are being utilized. Instead, CDP constantly replicates I/O operations performed on VMs using vSphere APIs for I/O filtering (VAIO) to process and read the data. If an RPO of seconds is not needed, you can leverage VM snapshot-based replication for an RPO of hours. Veeam Backup & Replication will instruct VMware vSphere to create a snapshot and copy the data to a target host creating a replica stored decompressed in its native format. Both replication techniques are great to use if your disaster recovery plan calls for short term fast recovery, think of natural disasters, hardware failures, application issues, etc. In most cases, organizations are replicating and keeping restore points anywhere from seconds to days creating a lower RPO replication chain to failover to which can be considered a tier 0 or 1 SLA. In Orchestrator, you can take these replica’s and create a failover plan for management, testing, and execution that is fully documented. You can initiate the failover and failback for some or all VMs while performing application steps and verification tests to ensure successful recovery.
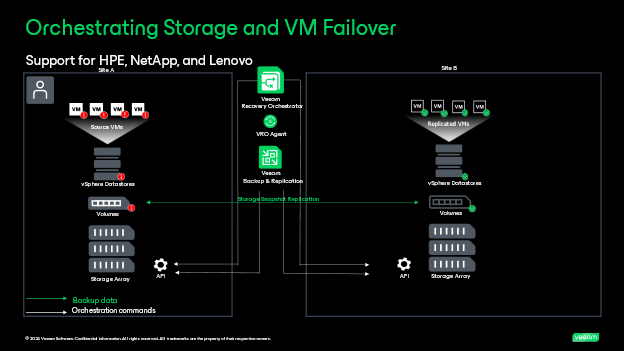
Scenario 2: Orchestrating recovery based on replicated storage snapshots containing vSphere VMs: In this scenario, vSphere VMs are replicated by the storage arrays between site A and site B. Veeam Backup & Replication will initiate an application-aware storage snapshot, where the VMs are processed via the storage arrays. The replication chains can consist of short- or long-term retention based on your organization preference. Orchestrator provides automation for failover of storage volumes, and the re-registration of VMs at the destination site along with the same documentation for planning, testing, and execution. The storage systems that are supported in this scenario and may need additional user account permissions are:
- HPE 3PAR 3.3.1, 3.3.2 MU1
- HPE Primera 4.2-4.5
- HPE Alletra 9000
- NetApp ONTAP 9.3- 9.13
- Lenovo DM: 9.3-9.11
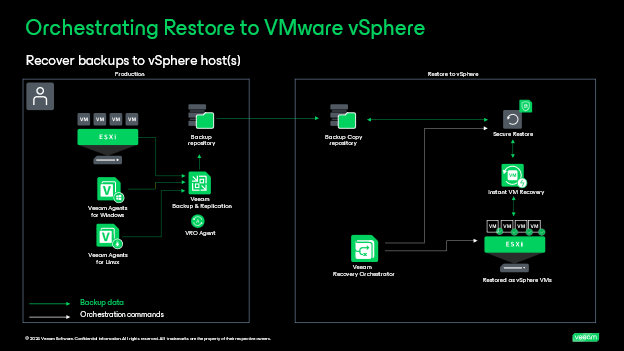
Scenario 3: Orchestrating restores to VMware vSphere from vSphere and agent backups: In this scenario, Orchestrator leverages backups taken by Veeam Backup & Replication to recover as vSphere VMs to the original or new VMware environment. This will be lower RPO and RTO vs replication scenarios of 1 and 2 because it is building a new VM from a compressed and deduplicated backup file. However, this can be particularly useful for those that do not have a secondary DR site to use VM replication like scenario 1. Here they can still build full site recovery protection plans from the backups if they ever need to rebuild a site or set of applications. Organizations can use this as another layer for data protection strategy for any workloads that don’t need a tier 0 or 1 SLA but would still need to be recovered in an outage. This is also a great strategy for recovering against malware as part of the restore process can have a signature scan and a YARA scan to ensure clean recovery.
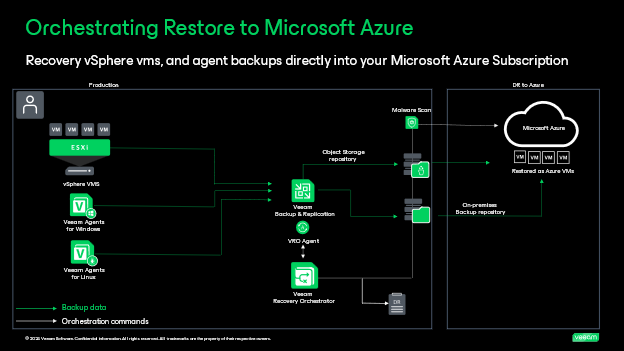
Scenario 4: Orchestrating restores to Microsoft Azure from vSphere and agent backups. In this scenario, Orchestrator will leverage backups taken of protected virtual and physical machines to recover as Microsoft Azure Cloud virtual machines. Very similar to the scenario above, but this performs a conversion of the original backup files to Azure VMs. In version 7, you can customize this recovery by adding your own custom PowerShell scripts that can be injected into the Azure VMs. Support for on-premises and object storage repositories is possible, however archive tier is not. I recommend if you do plan to leverage a cloud based repository for recovery, or if you want to test out this functionality check out this Blog from my colleague
In all scenarios a runbook is created and consistently updated, arming your organization with the ability to audit any changes that are happening in production and can potentially cause a failure while recovering after disaster.
Workload Assessments
Next, we must understand what workloads we want to protect and how. Building workload assessments can be a daunting task that requires many eyes and ears to be able to determine what type of strategy an organization needs to use. Since we are just getting started, here are some important items to think about from both a business and technical perspective while performing a workload assessment
- Resources Utilized: How do the workload(s) consume CPU, RAM, Storage – how much of that is needed when replicating or restoring to a new location to size the recovery environment.
- Integration Dependencies: Are there workloads requiring others to be running before it can work? If so, how do we map out the dependencies, get the expected boot times to ensure we are meeting business SLA’s? There are tools out there that offer free trials for 30 days as well as open source to gather this info.
- Security: What type of data does this workload hold? Do we need to be concerned with data privacy regulations (PCI, HIPPA, GDPR) and where this data is stored? How often can we update/patch for vulnerabilities?
- Future Growth: Do we expect this application/workload to significantly grow? If so, by how much and how often?
- Cost: How much does it cost to run on-premises vs public cloud? Would it be cheaper to keep at a co-location, managed service provider, or public cloud?
- Business impact: How is the business affected if this workload or application was unavailable? How long can services not be running before it begins to impact the business negatively?
These are just a sample of questions all organizations should be thinking about when building out an effective strategy for business continuity and disaster recovery, but it is not all of them.
Identifying the machines
Now that we have our questions ready for the workload assessment, we need to capture the workloads themselves. Fortunately, Veeam has a tool that can assist with gathering this data. Let’s start with what is part of the Veeam Data Platform, VeeamONE. A real-time monitoring and reporting tool that can help with identifying the VMs in the environment and be proactive to ensure machines won’t run into potential issues when we start protecting them with Veeam. As described earlier, Veeam Recovery Orchestrator comes with a version of this installed automatically. This helps to collect tags assigned to objects on the vCenter side and categorize them. In VeeamONE the following reports can be helpful in identifying workloads:
- vSphere Overview - VM configuration: The Details table provides information for every VM, including data on VM location, computer name, guest OS type, number of vCPUs, amount of allocated memory resources, amount of allocated and used storage resources.
- vSphere Infrastructure Assessment – VM configuration: This report helps you to assess VMs readiness for performing backup with Veeam Backup & Replication. The report analyzes the configuration of VMs in your virtual environment and shows potential issues and possible limitations that could cause backup processes to fail or prevent VMs from being properly backed up.
- vSphere capacity planning – How many VMs can be provisioned The report evaluates total capacity of your infrastructure and provides estimation of how many sample VMs of a certain profile can be added without causing the specified resource utilization threshold to be breached. The calculation of additional VM sets is based on the predicted future performance of the sample VM and the predicted virtual infrastructure capacities.
If you don’t have VeeamONE installed, you can still get information about the workloads through other third-party means. For instance, for raw data exports in Excel format you can leverage RVTools which is a Windows .NET application that uses VMware vSphere Management SDK 8.0 and CIS REST API to display information about your virtual environment. This info can include virtual machine name, CPU, memory, disks, snapshots, and much more.
From here we can start leveraging vSphere tags to help us with categorizing the applications. For example, in my lab I tagged my VM’s with “Tier 1” and created a backup policy that gathers all the VM’s associated to this tag as part of a daily backup job. This is helpful since the embedded VeeamONE server will begin to collect the data and categorize it when it is added to the Orchestration server. I will go over this in more detail in the next blog, but it is important before we start data collection, we have defined categories that will make it easier to create policies for our applications leveraging vSphere tags like the “Tier 1” example above. If you are not familiar with vSphere tags and how they work you can check out this VMware Doc and see
Now that we are finished with our planning, we can proceed to the next step which is installing Veeam Recovery Orchestrator. Check out the next blog to see how we can install and configure Orchestrator to strengthen our BC/DR posture.


