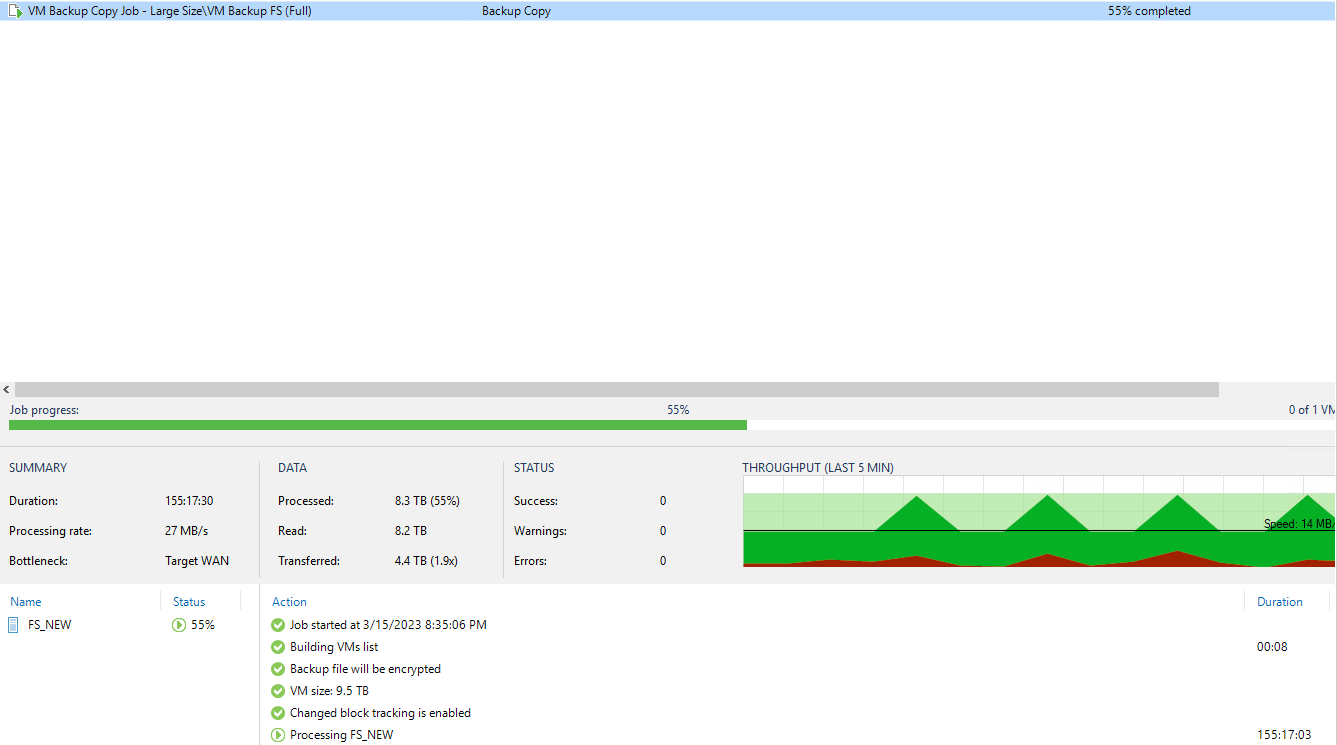
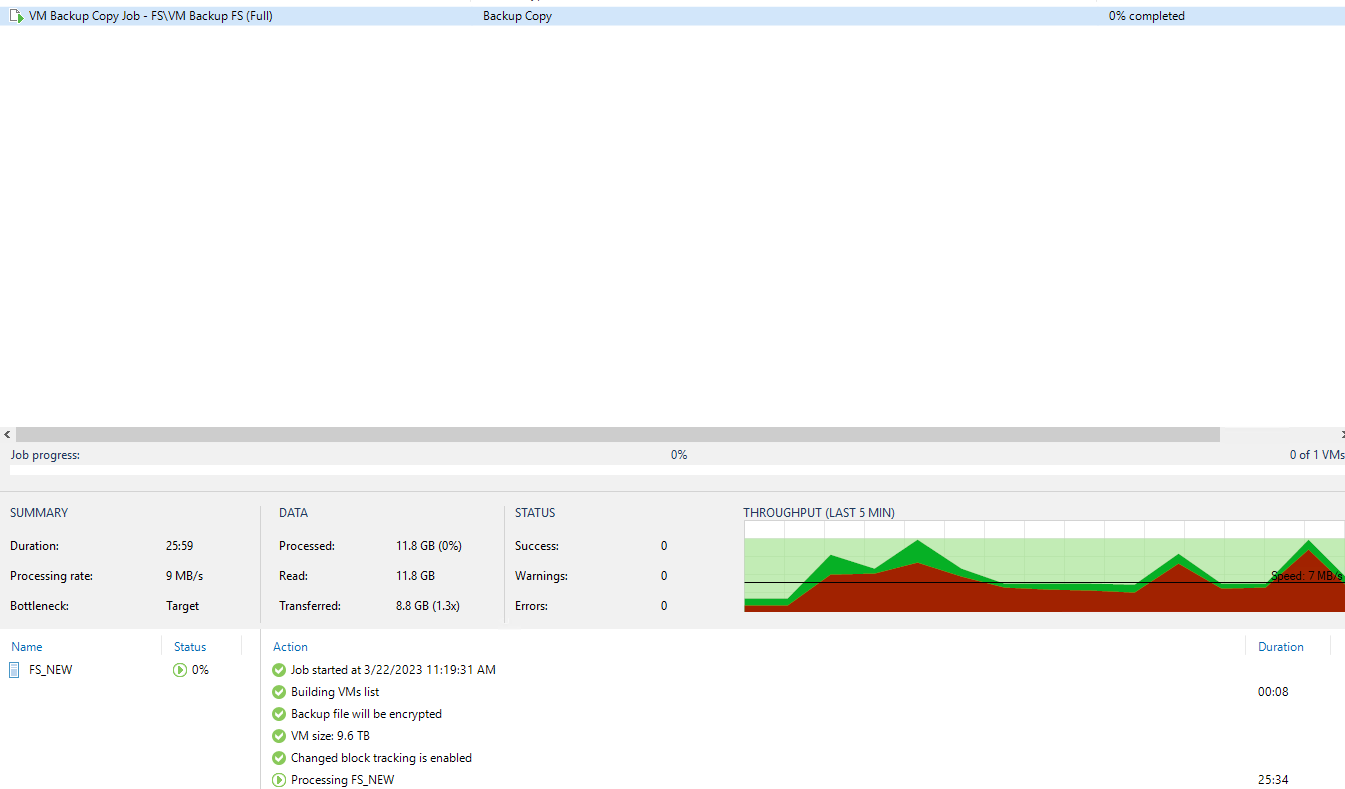
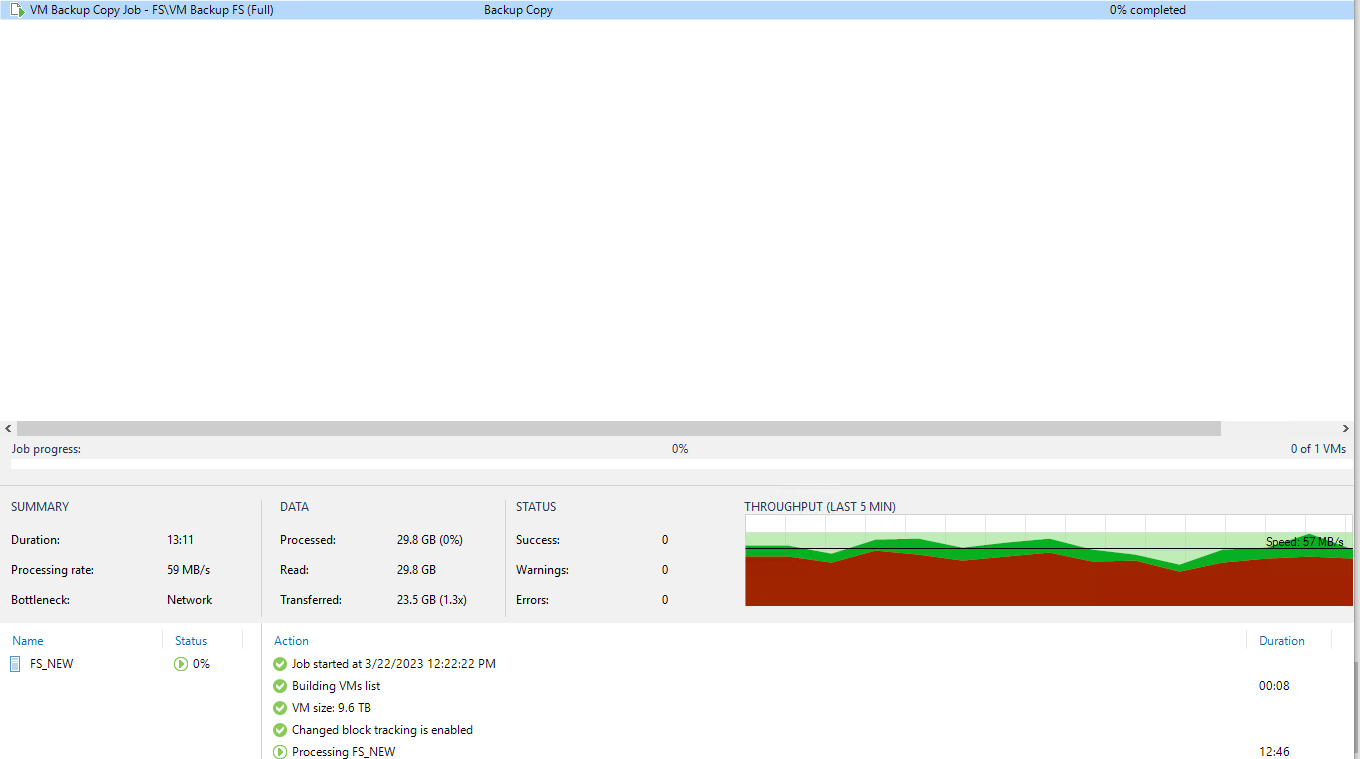
Your data flow is currently as follows then:
Source Synology NAS → Source Gateway Server (Likely VBR server) → Destination Gateway Server (Also VBR server so just loopback traffic) → Destination Synology NAS.
Which looks simple enough, but the issue occurs with IO requests, as the VBR server is having to manipulate a large backup file on the destination Synology NAS with reads and writes both traversing the WAN.
If you swap it to:
Source Synology NAS → Source Gateway Server (Likely VBR Server) → Destination Gateway Server (within Destination site) → Destination Synology NAS.
Then the WAN is only being used to shift blocks from source to destination gateway servers that need to be committed, and the gateway server is handling the IO read/writes to Synology at LAN speed.