

Resilient Data Protection using Scality ARTESCA and Veeam Backup & Replication
Welcome to the 2nd and final blog co-authored with Pierre Gueant, Director of Solution Partners at Scality. In this blog we will discuss how Scality’s ARTESCA product can provide you the confidence that your backup data is protected and available when you need it.
The object storage journey for Veeam Backup & Replication (VBR) really took off when VBR v9.5.4 was released in early 2019. It was in VBR v9.5.4 that we saw the addition of the Capacity Tier to the already proven Scale-out Backup Repository (SOBR) which was introduced in version 9.0 towards the end of 2015.
What is a SOBR?
The SOBR revolutionised the use of file based backup repositories. A SOBR aggregates multiple repositories, called extents, into a single logical repository. It is the ability to add extents that enables the SOBR to grow and expand to meet your backup workload demands.
A SOBR typically consists of two tiers. The Performance Tier and Capacity Tier. The Performance Tier is where your backup job will initially send the backed up data to. This tier is typically comprised of fast and performative storage so that the backups finish quicker and also so that restores can be completed as soon as possible. The Capacity Tier is typically comprised of storage that is slower and less expensive compared to the Performance Tier. The Capacity Tier is also usually in a secondary site so if the site containing the Performance Tier is lost, you can recover your data from the Capacity Tier.
A typical SOBR configuration can look like this:
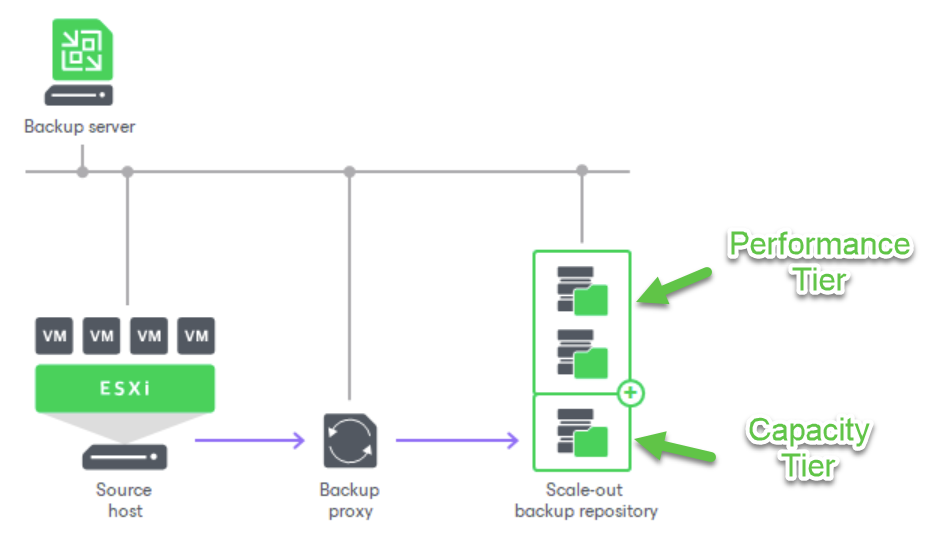
There is a 3rd tier, the Archive Tier, which is used for long term storage. We won’t be discussing the Archive Tier in this blog, but you can read about it here on our Help Center page for Archive Tier.
Benefits of SOBR extents
The SOBR extents and tiers provide additional benefits along with the ability to scale-out the SOBR. Performance and resiliency are added to a SOBR via the use of these extents and tiers. Let’s discuss the performance benefits of the extents first. By having multiple extents, a SOBR can receive more concurrent streams of backup data from more simultaneous backup jobs than a stand-alone backup repository. When you configure a SOBR, you must set the backup file placement policy for the extents. You can choose either:
- Data Locality
- Performance
The backup file placement policy instructs VBR on how backup data is distributed across the extents. Data Locality will keep the backup chain for a machine(s) being protected to the same extent. Performance will spread the backup workloads across all available extents. You can learn more about data placement policies on the Help Center page for Backup File Placement.
However, losing an extent means losing all backup workloads stored on it. This is where the tiers add a level of resiliency by allowing data from another tier to be used for recovery. In the event of losing a Performance Tier extent, you can recover from the data stored in the Capacity Tier.
Being able to recover from the Capacity Tier can mean the difference between keeping the lights on and a catastrophic data loss. That said, recovery from offsite backups presents operational challenges, particularly in terms of Recovery Time Objective (RTO), which is the time to restore operations and Recovery Point Objective (RPO), which is how old the data recovered is. Restoring from a local backup is faster and more straightforward typically than using secondary backup copies.
This puts the onus on finding a storage solution used for your SOBR tiers that you have confidence will be available when you need to access the backup data in either tier. Wouldn’t it be nice to use a storage platform that retains and even enhances the flexibility of a SOBR while ensuring zero downtime and data loss? Even in the event of a complete server loss?
One such solution is Scality ARTESCA.Today we’re going to take a look at ARTESCA and see how it behaves when you need it the most.
Node failure during Backup
For this blog, we are using a 3-node ARTESCA cluster and a VBR instance, which we have already configured using the Veeam Assistant. You can learn more about the Veeam Assistant this Veeam Assisant blog that Pierre and I co-wrote recently.
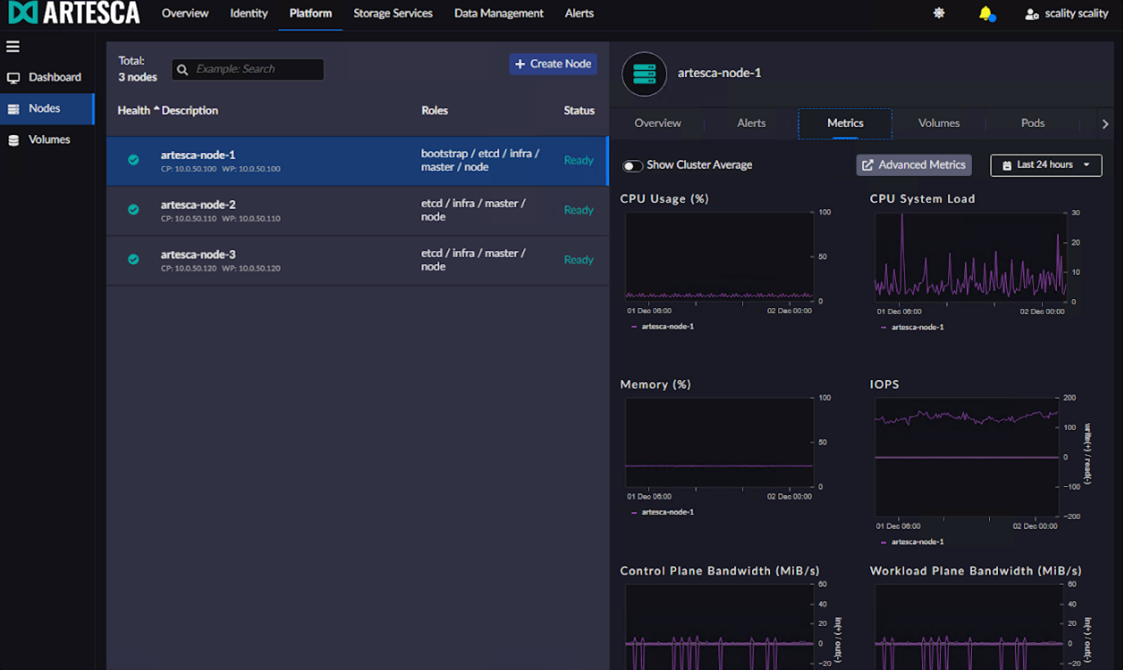
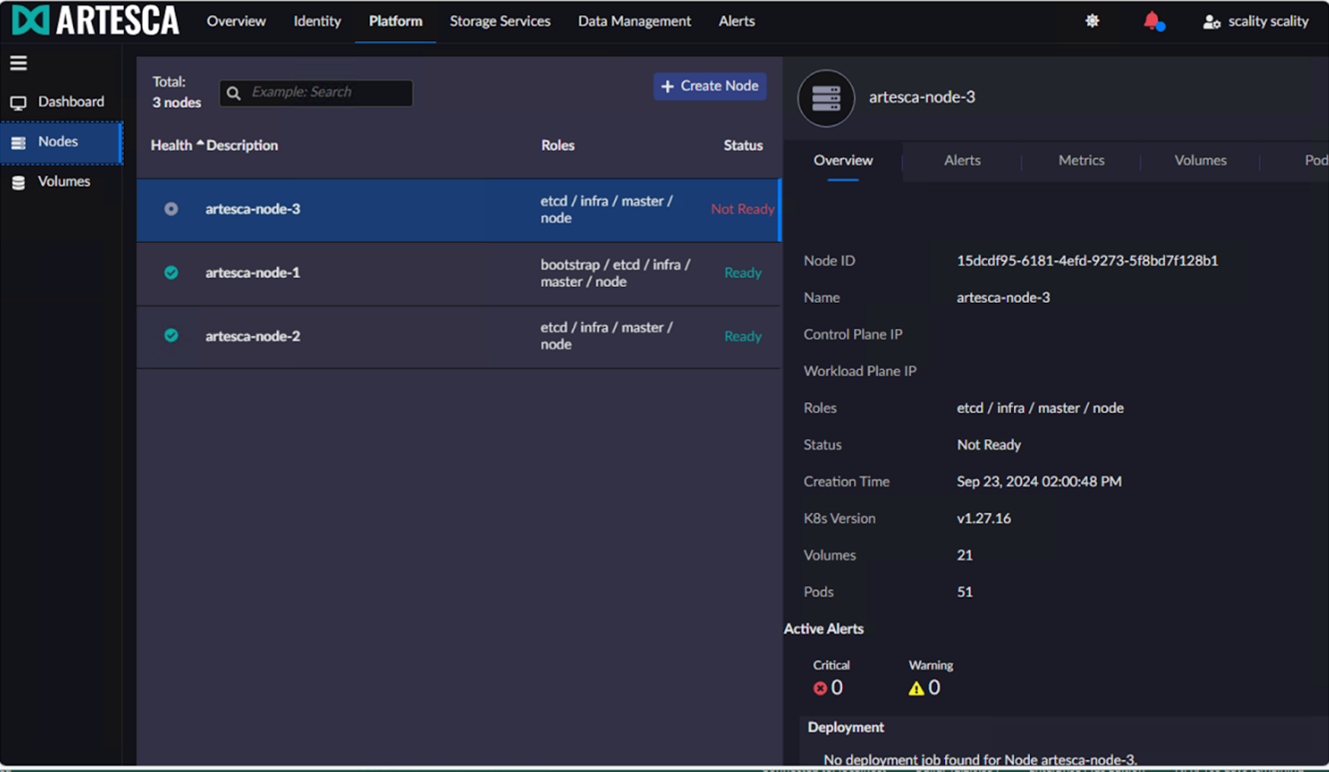
Here you can see that all three nodes “Ready” and we are all set to move forward:
Our first example of ARTESCA’s resilency is to cause a node failure during a backup job:
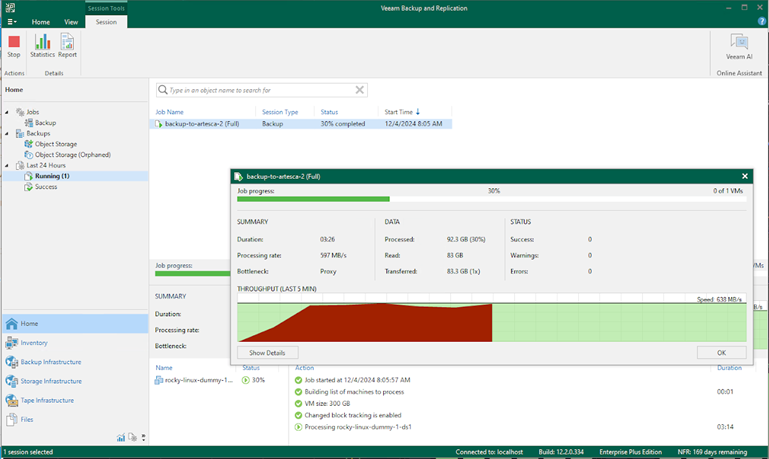
The backup started smoothly and progressing with no issues. Now let’s simulate a node failure on the ARTESCA by shutting down one of the nodes while this backup job is running to see how both ARTESCA and VBR behave.
We are not bringing the ARTESCA node down gently by shutting it down immediately:
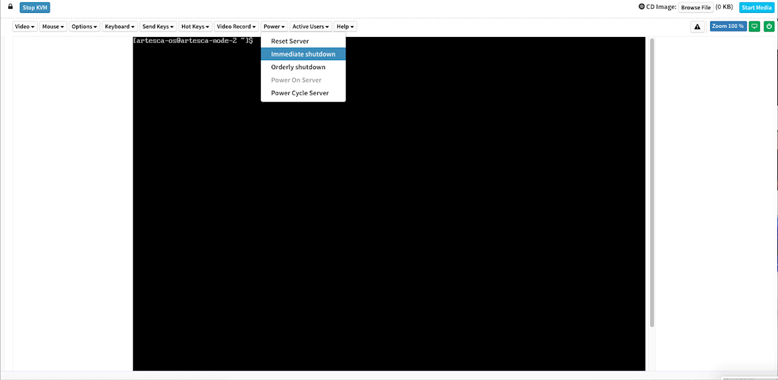
After the ARTESCA node is shut down, it appears as "Not Ready" in the ARTESCA console. You can see the node we brought down was node 3:
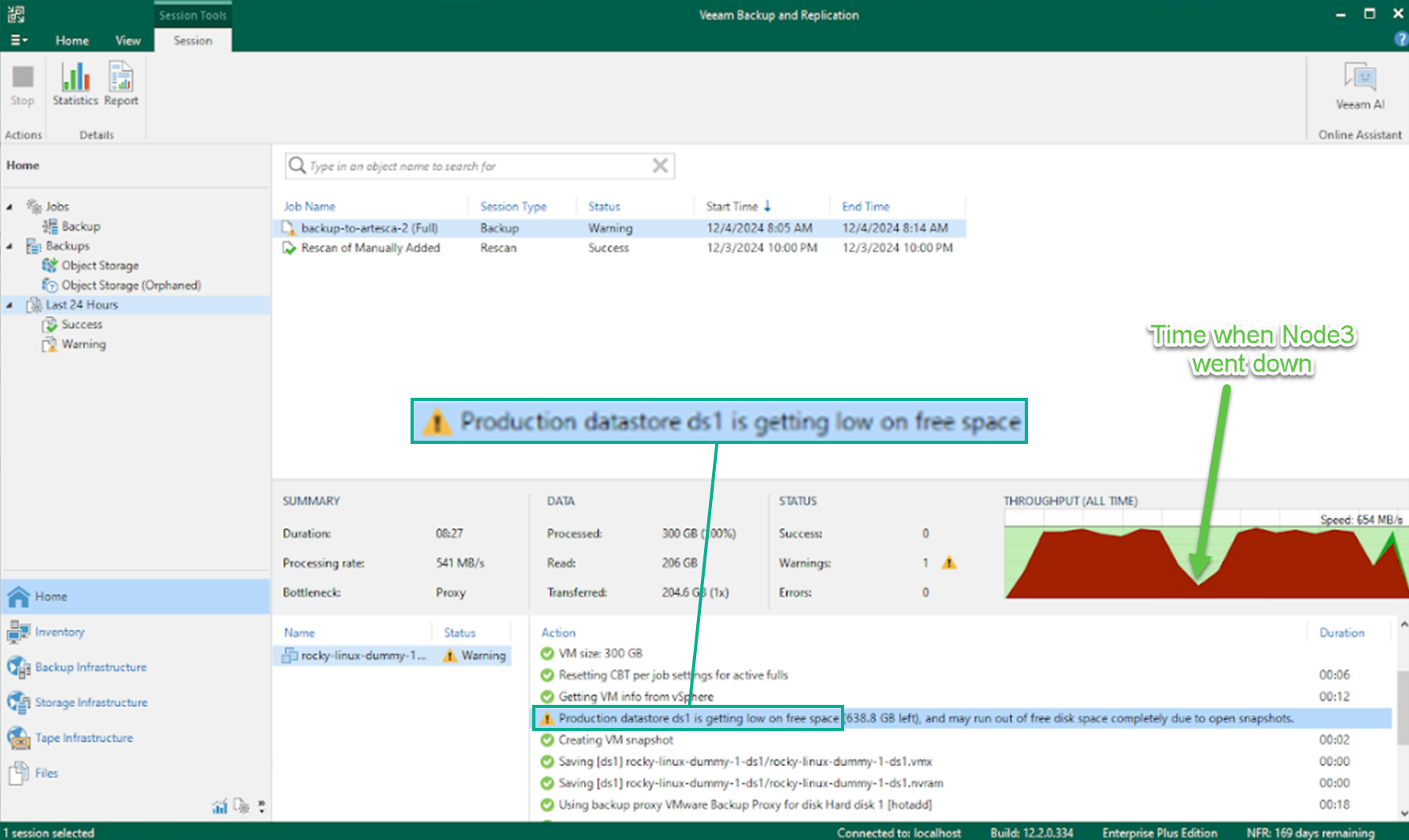
You can see the valley that shows when the backup job experienced Node 3 going down. Due to the loss of the node, the transfer speed temporarily slows down, but VBR quickly recovers and the backup job resumes at full speed after the ARTESCA dealt with the issue. The backup job soon completes successfully without any errors.
Notice the capacity warning upon job completion: VBR monitors the available capacity of object storage by using the Smart Object Storage API (SOSAPI). In this case, the storage is nearly full, prompting VBR to issue a warning. While it is possible to configure email alerts in ARTESCA, the Veeam administrator might not receive these so it’s extremely helpful to see this warning within VBR’s console.
To learn more about the Smart Object Storage API, please check out this SOSAPI blog.
Despite the server failure, the backup continues uninterrupted., This is due to the network erasure coding which uses a 2+1 data parity distribution in a 3-node configuration, allowing for the loss of an entire server. Additionally, ARTESCA includes built-in S3 high availability across the back end, ensuring transparent failover. When a server fails, the cluster automatically redirects requests - previously balanced across all three servers - to the two remaining servers. By combining network erasure coding with this failover mechanism, ARTESCA effectively makes hardware failures an invisible event for Veeam.
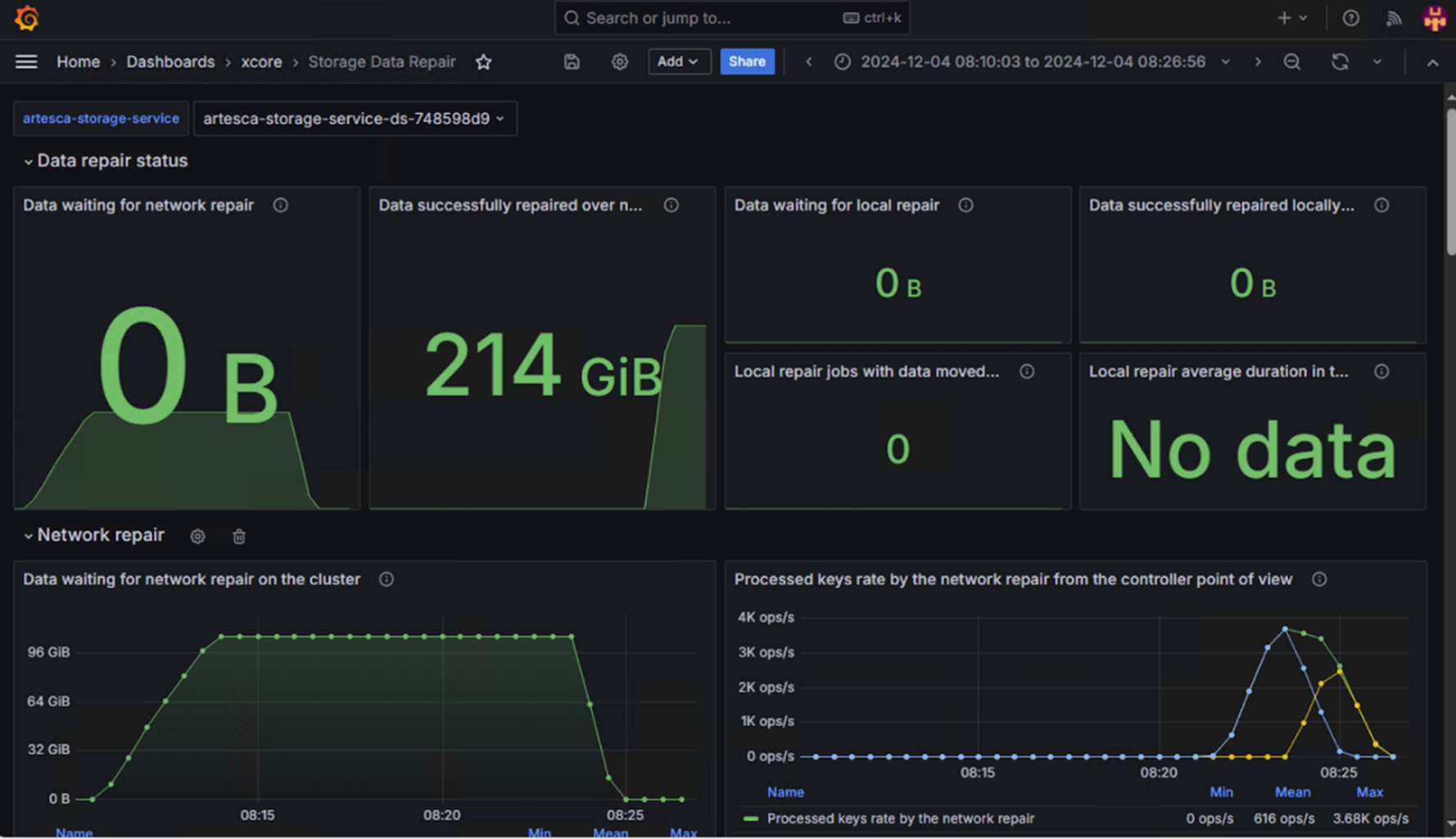
When we re-introduce the failed server to the cluster, the rebuild process begins, reconstructing the missing parity on the rejoining node and swiftly restoring the protection level to 11x9s of durability. It might seem like magic, but it’s not - ARTESCA provides a pre-configured dashboard to monitor the rebuild process. In this case, after just a few minutes, all the data had been rebuilt and the system had returned to its normal fully resilient state.
Node failure during Restore
Now that the backup is securely stored, let’s proceed with the restore. We initiated the recovery from the VBR console restoring the data from the ARTESCA:
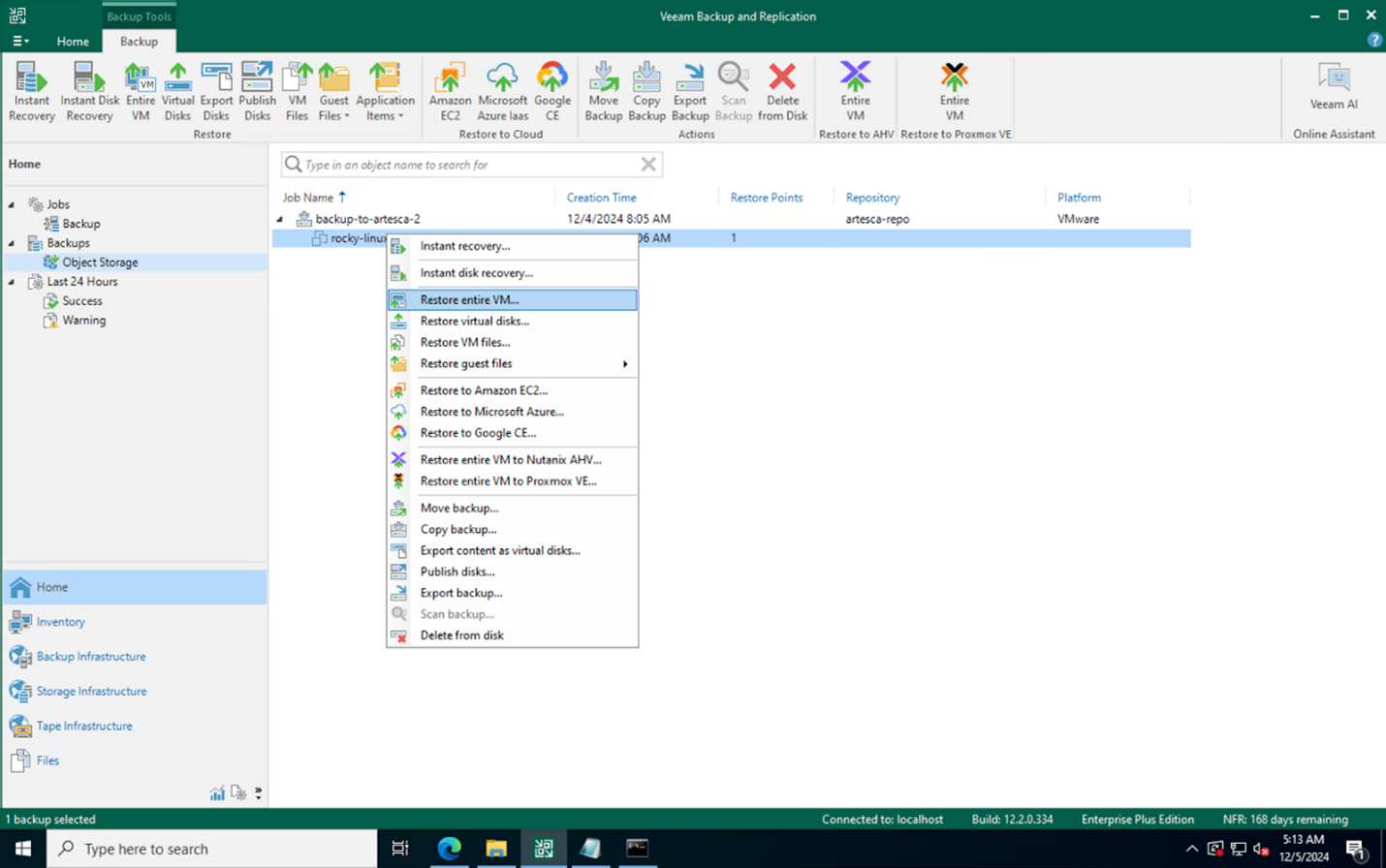
The restore process for the virtual machine starts as expected with no issues:

This time, during the Veeam restore process, we shut down a different node, artesca-node-2. This “failure” verifies the data which was originally missing on artesca-node-3 during our last test has been successfully rebuilt once the node was recovered:
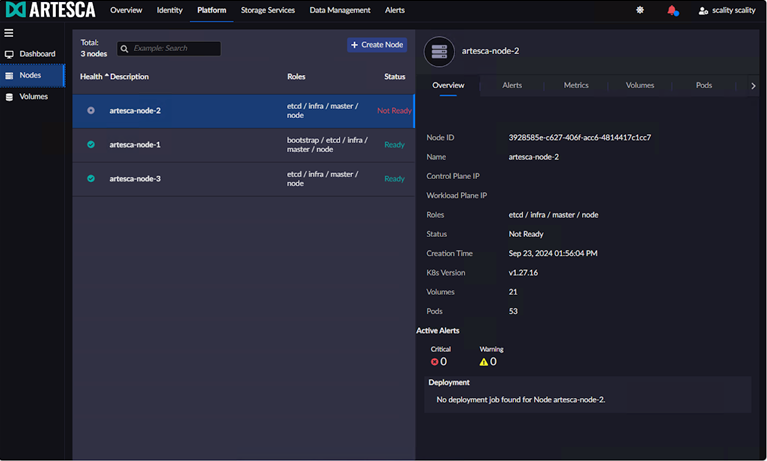
As expected, this does not impact the virtual machine recovery process. The restoration job proceeds without interruption and all of the backup data required exists on the two remaining nodes. This data recovery and distribution amonst the ARTESCA nodes was done behind the scenes and didn’t require any actions by us.
ARTESCA offers a comprehensive set of built-in dashboards, so we switched to the “S3 service” screen to monitor the restore throughput:
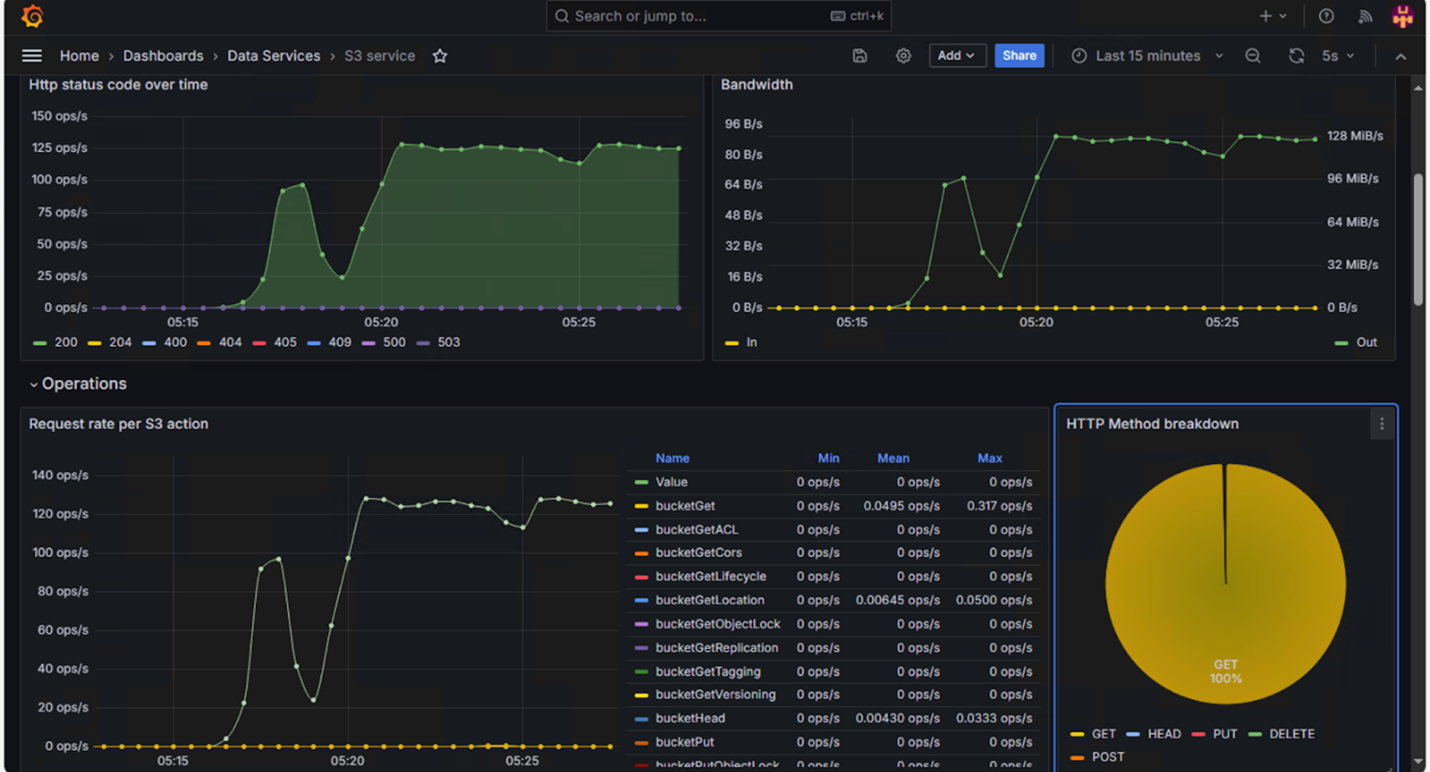
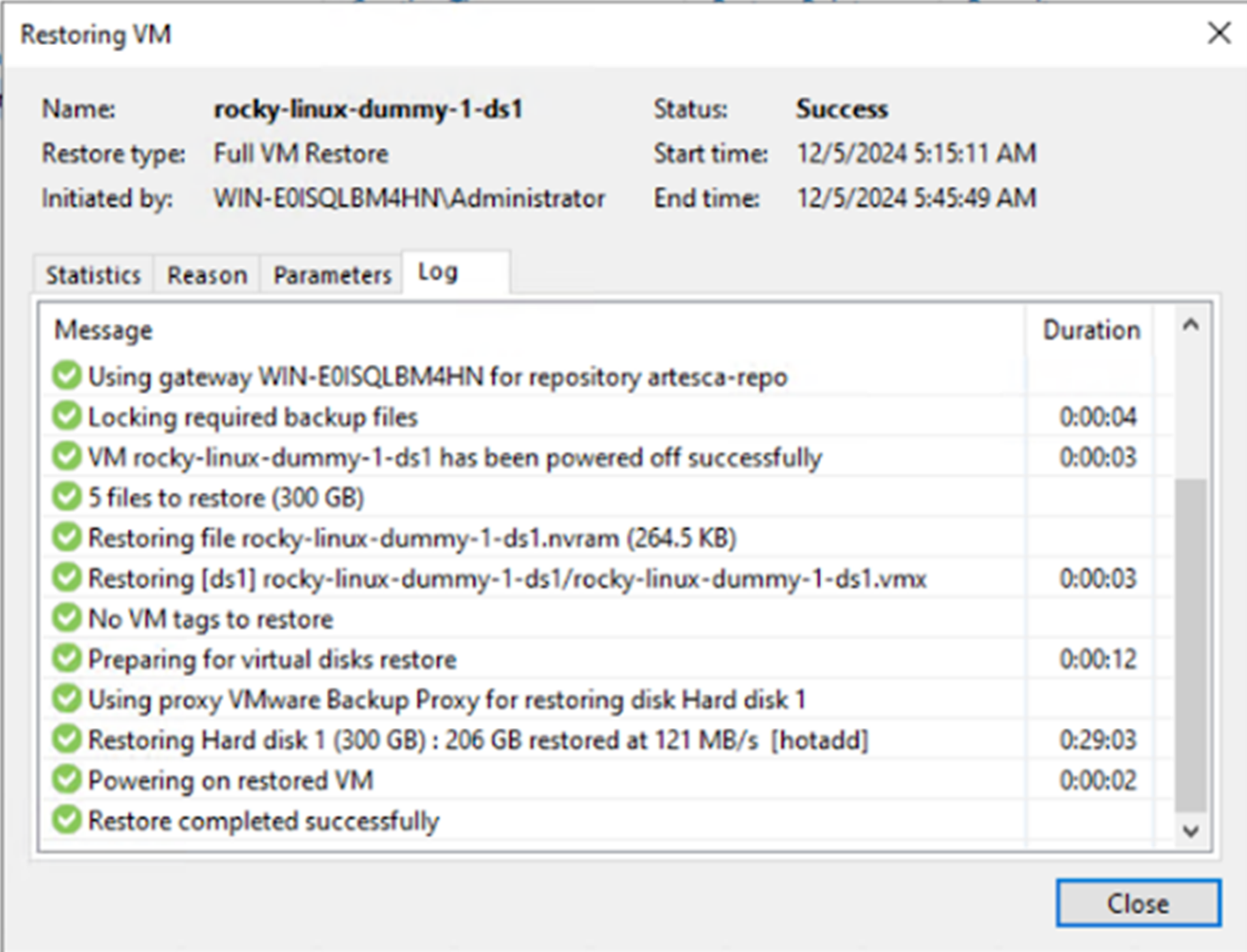
Similar to the backup phase, there is a brief drop in throughput and operations per second when the outage occurs, but the system quickly returns to its normal performance. It's also important to note that no HTTP errors are generated. From the VBR perspective, the server failure is completely transparent. The restore job completes successfully without any errors.
ARTESCA allows administrators to enable email notifications to alert the relevant contacts in the event of a hardware failure. While the system immediately rebuilds any missing data, quickly bringing the system back to full resilience, the faulty component will need to be replaced to restore original available capacity. These notifications enable the system administrator to interact with the hardware vendor and quickly replace the failed components.
Final thoughts
In the world of data protection having a flexible and resilient storage solution is the key to ensuring business continuity. Scality ARTESCA, combined with Veeam Backup & Replication, offers a compelling way to maintain high availability while minimizing downtime and eliminating data loss.
As we’ve seen, the ability to recover quickly from a node failure is crucial for maintaining seamless operations. Combine that with resilient object storage, your backup strategy can be both robust and adaptable, ensuring your organization is prepared for whatever challenges come your way.
