

Veeam Backup & Replication v12.1 + Spectra BlackPearl = On-Prem Archive Tier
Veeam Backup & Replication (VBR) v12.1 is loaded with many great new features and enhancements. One of the new features is the extension of the Archive Tier to on-premises storage solutions that are Amazon S3 Glacier compatible. Spectra’s BlackPearl S3 Hybrid Cloud Storage is one of those solutions.
But what is the Archive tier? It was first introduced in Veeam Backup & Replication v11 back in February of 2021. The Archive tier is an additional tier of storage that can be attached to a scale-out backup repository (SOBR). You can transport applicable data to the archive tier for archive and cost saving purposes.
The following types of backups files are eligible to be sent to the archive tier:
- GFS backups
- Orphaned GFS backups
- Veeam Backup for Red Hat Virtualization GFS backups
- VeeamZip backups
- Exported backups
- Kasten K10 backups
For the purpose of this blog I will be using backup files with GFS flags. The GFS backups that I will be archiving are weekly full backups.
Prior to VBR 12.1 the Archive Tier options were Amazon S3 Glacier and Microsoft Azure Archive Storage. But now with VBR 12.1, you can take advantage of the benefits of “cold” storage while keeping your data on-premises.
The following diagram illustrates the different tiers of a Scale-out Backup Repository that are available in VBR 12.:
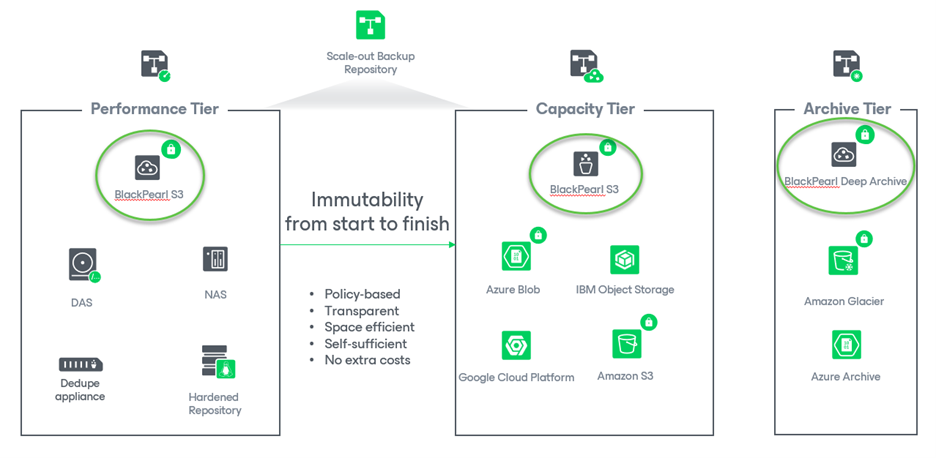
BlackPearl Steps:
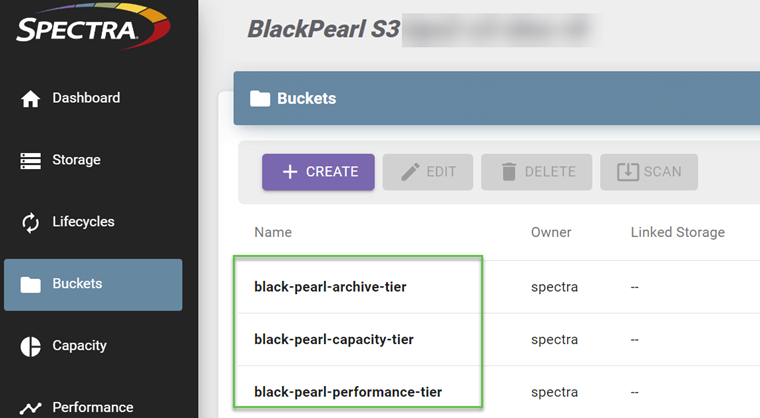
Let’s walk through how to set up an on-prem Archive Tier using BlackPearl. The first step is creating the required buckets. In this example, I will be using BlackPearl S3 Hybrid Cloud Storage for all three of my repository tiers (Performance, Capacity, and Archive).
You can see from the BlackPearl interface that I created my three buckets and using my “wicked awesome” naming conventions, you can clearly see the intended use cases for the buckets:
Now, how does Veeam Backup & Replication know which bucket is Amazon S3 Glacier compatible and is eligible to be an archive tier? If you have read any of my previous “Veeam Amazing Object Storage Tips & Techniques” blogs, you can probably guess what the correct answer is.
The Smart Object Storage API (SOSAPI) is the mechanism where the bucket, in this case “black-pearl-archive-tier”, is enabled to be an Archive Tier. In VBR v12.1 we added a new parameter to the SOSAPI that an object storage provider like Spectra can flag a bucket to note that it is capable of being used as a target for the Archive Tier.
VBR Steps:
Now we can hop into the VBR Console to set up the backup infrastructure to use these new BlackPearl buckets.
For the sake of keeping the blog under the maximum character count, I am going to assume you know how to create an object storage repository and I will focus on the archive tier repository steps. If you need a refresher or are new to creating object storage repositories, our HelpCenter has all the information that you need regarding Object Storage Repositories.
From the VBR console select “Add Repository”, choose “Object storage” (note: same steps for Performance and Capacity tiers):

On the next screen you choose “S3 Compatible” (note: same step for Performance and Capacity tiers):
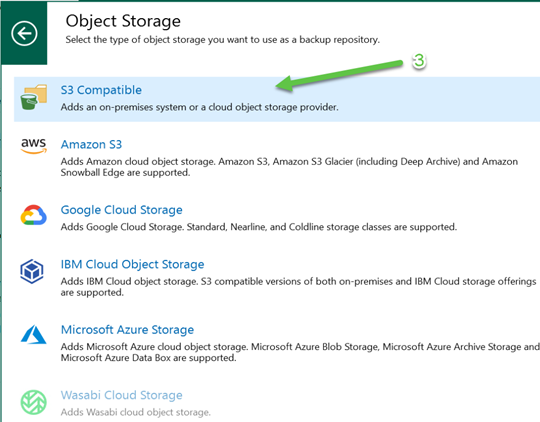
This step is where we diverge from the path we would take for the Performance and Capacity tiers. For those repositories we would select “S3 Compatible” but to create the Archive Tier repository we now select “S3 Compatible with Data Archiving”:
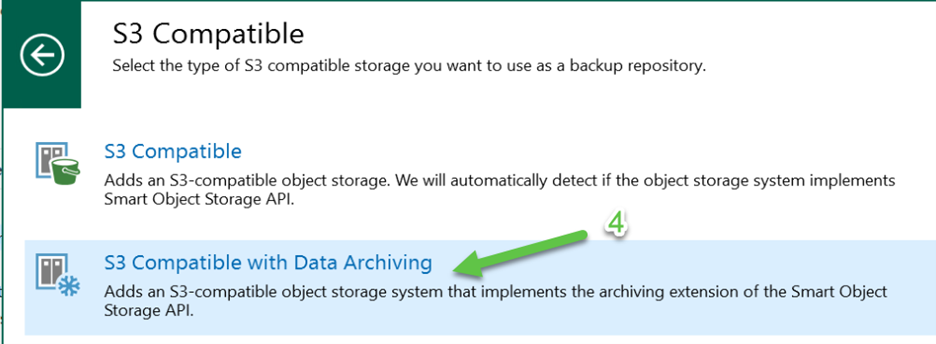
Notice the icon at the top of the next screenshot shown below. It shows a blue snowflake. This indicates that we are creating an Archive Tier repository. On this screen we need to enter the “Service point”, “Region”, and “Credentials” for the bucket we are going to use. This is the same information you need for the Performance and Capacity tier buckets as well. The difference on this screen from those other tiers is the “Archiver appliance” section. For the Performance and Capacity tiers you need to specify the “Connection mode”:
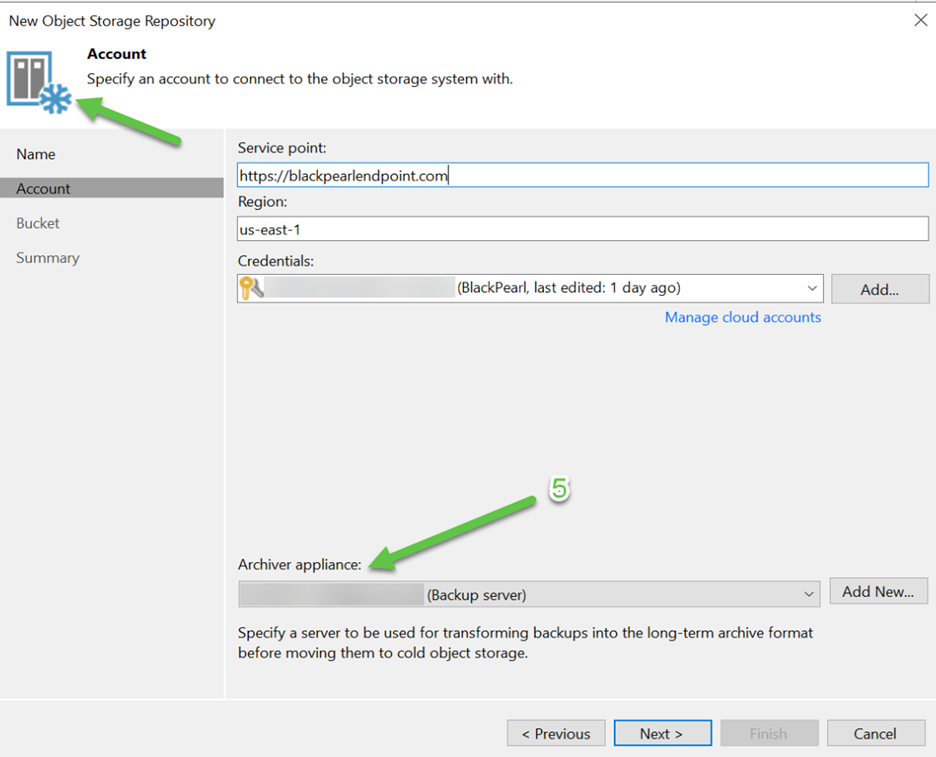
The Archiver appliance is a service that runs on the server you select. I am using the VBR server in my example. The Archiver appliance’s purpose is to build the objects that will put to the cold storage that comprise the GFS backup that is being archived. The source objects for this example will come from the Capacity tier, but you can archive data directly from the Performance tier as well as long as the Performance tier uses object storage backed extents.
Now that I have my repositories created for all three tiers, I will now create a Scaled-out Repository (SOBR) which is required for the Archive Tier. I am again going to assume you know how to create a SOBR but if you don’t HelpCenter is a great resource for Scale-Out Backup Repositories.
Within the SOBR wizard you will see the Archive Tier option. When you get to that step you need to enable the Archive Tier for archiving GFS backups via checking the “Archive GFS full backups to object storage” checkbox. Once you do that you can select the appropriate Archive Tier repository. The next step is to choose which GFS backups will be archived based on age:
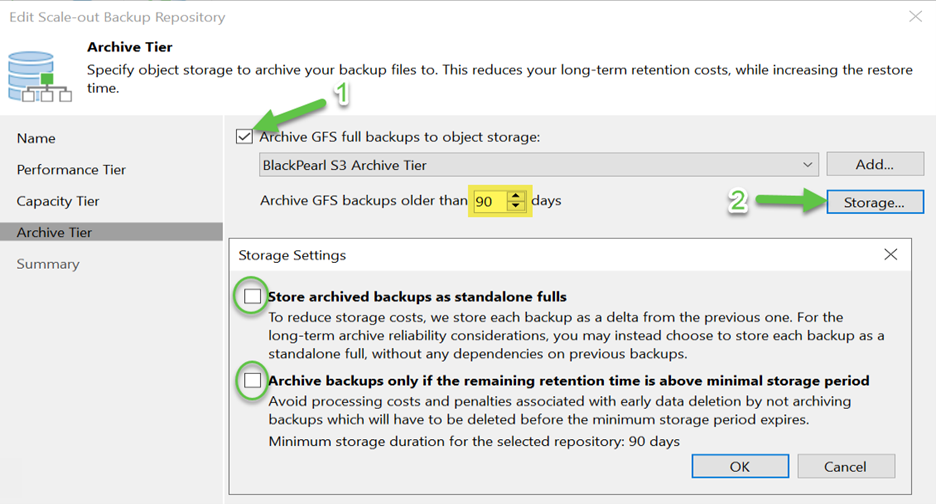
The default is to archive GFS backups that are older than 90 days. But as I noted earlier, I am impatient, so I set the value to 0 days. That way the backups I create today will be eligible to be archived today. Also, click on the “Storage” button and deselect any checked boxes on the “Storage Settings” screen.
Now you can see my completed SOBR “BlackPearl S3 SOBR” and the three repository tiers. Notice the Archive Tier repository has the distinctive blue snowflake to indicate “cold” storage:

The next step is to create a new backup job that will use my newly created SOBR so that we can archive some GFS weekly full backups to BlackPearl’s cold storage via our Archive Tier.
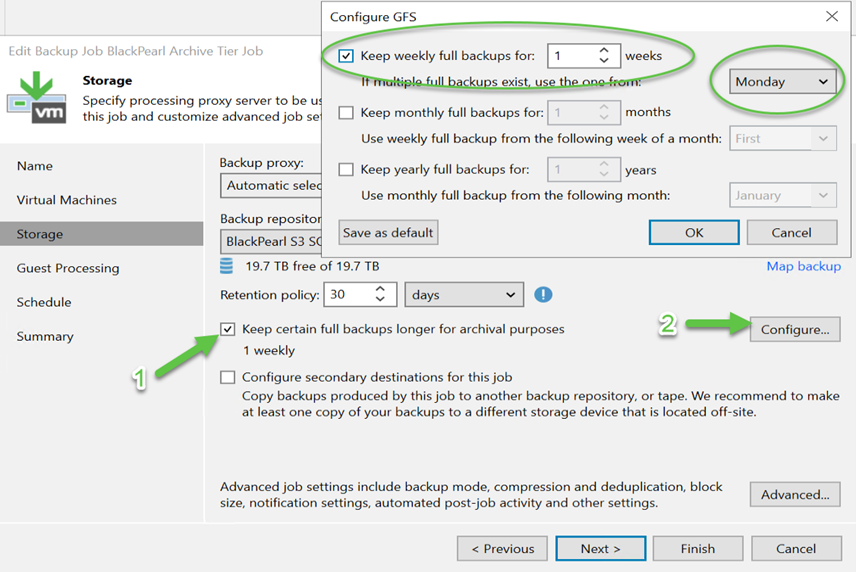
Within the job’s configuration settings you can configure the GFS backups for archival purposes. The 1st step is to check the “Keep certain full backups longer for archival purposes”. Then we need to click on the “Configure” button to configure our GFS setting on the pop up window. In my example I chose to keep my weekly full backups for 1 week and that they will be created on Monday:
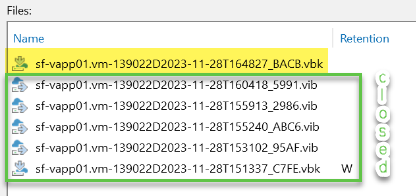
I ran an initial full backup (.vbk) and then 4 incremental backups (.vib). You can see the full backup chain here:
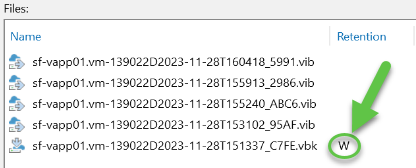
Notice that the full backup is marked with “W” indicating that it is a Weekly GFS backup.
Now that I have my backup chain created, I need to close the chain by creating a new full backup. Only after the current backup chain is “closed” will the GFS backup get archived.
For the purposes of this blog I will manually initiate an Active Full backup. To initiate an Active Full backup you can either click on the Active Full button on the toolbar or you can <right-click> on the backup job and select “Active full” from there:
Now the GFS backup is eligible to be archived. This can be done manually running the tiering job or wait for the system offload job to run. By default the system generated one runs every 4 hours and as you know by now I am impatient, so you know what option is next.
No surprise, we will do it manually by using “<ctl> + <right-click>” on the SOBR name and selecting “Run tiering job now”:
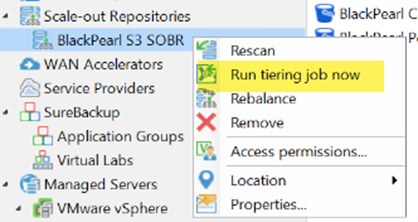
Once the tiering job finishes you should see the archive offload job start running:

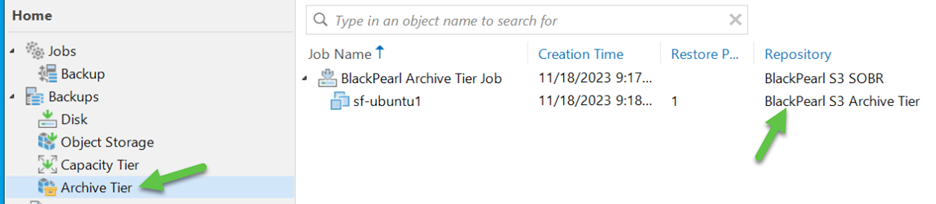
We can now see in the VBR console the Archive Tier along with the backup that resides in the Archive Tier and what repository is being used:
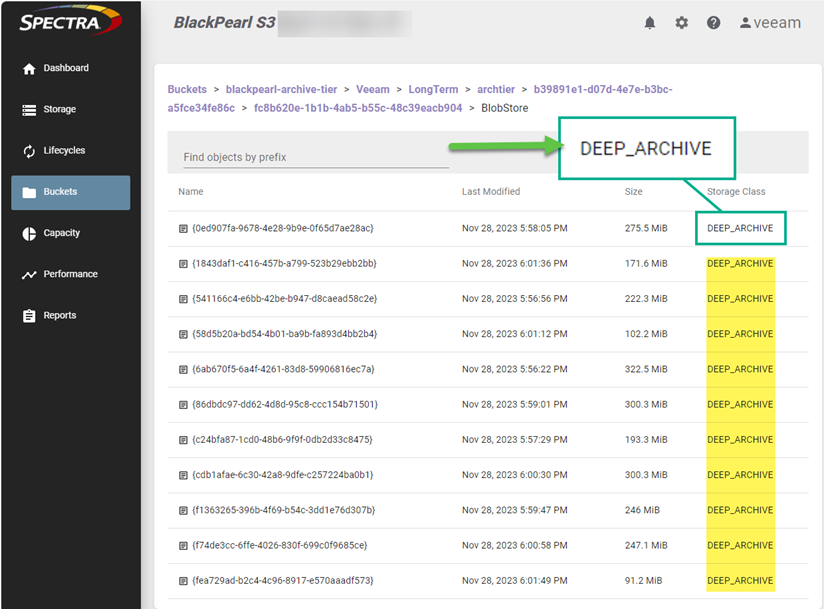
Now if we check the Archive Tier bucket “black-pearl-archive-tier” and look at the objects, we will see the storage class is “DEEP_ARCHIVE”, which when using BlackPearl indicates the objects are in their “cold” storage:
BlackPearl will now take these objects and place them on tape. So the final resting place for their DEEP_ARCHIVE storage class will be tape. And from the BlackPearl console I can see the tape(s) that my GFS weekly is stored on:

The combination of Veeam Backup & Replication v12.1 and Spectra BlackPearl S3 Hybrid Cloud Storage now will allow you to implement an Archive Tier. You get the benefits of storing your GFS backups on “cold” storage while not incurring the costs of retrieving the data back from the Archive Tier as you do with some public cloud solutions.
If you have any questions, please reach out to me via the comments feature and I will do my best to answer them.



