

Hi, I am new to Veeam Backup. On a Dell PowerEdge R7515 running Windows 2022 Standard, I have a 67 terabyte REFS volume where I store Veeam backups under a folder called “vault” (see screenshot below). In Windows Explorer, when I check the size of the “vault” folder (by right-clicking on the folder name and going to Properties) it says the “Size on disk” is more than 67.6 terabytes (see below). This folder contains one .vbm file and a few .vbk and .vib files. However, when I check the properties of the physical disk volume under Disk Management utility (diskmgmt.msc), it says that I still have about 31.9 terabytes left on disk meaning that ONLY about 35 terabytes of data is used with about 48% free (see below). Also, I do not have data duplication role installed on this server. Could someone shed some light on this extremely large discrepancy between disk volume size and folder size? Thank you!
Content of “vault folder”:
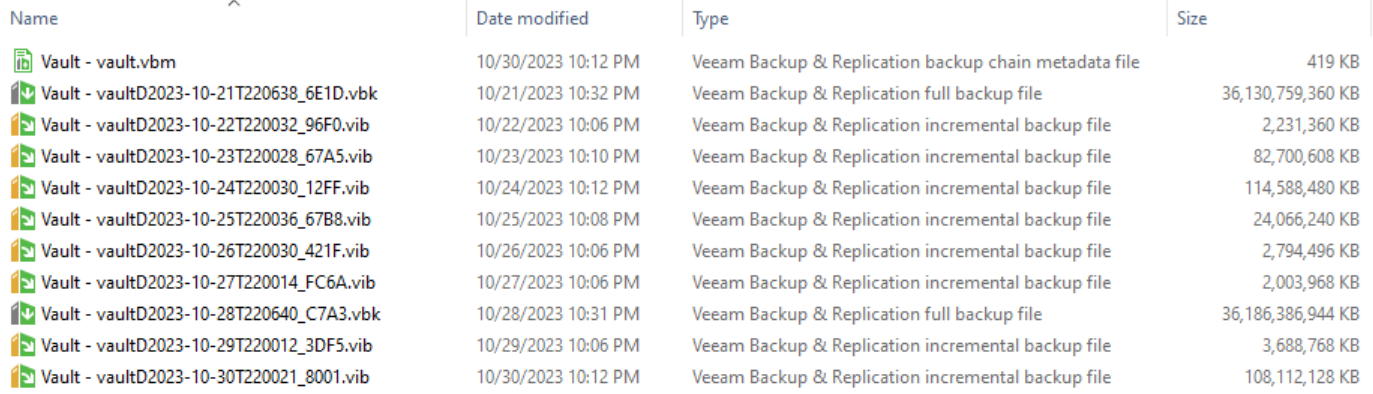
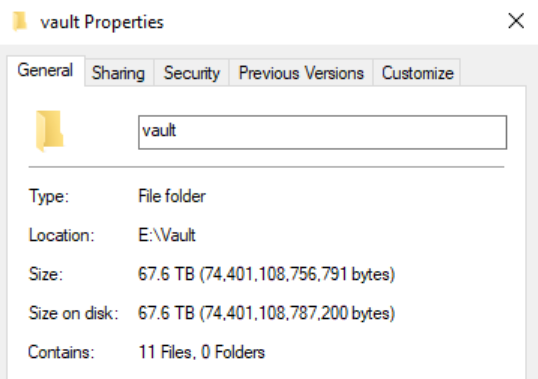
Disk Management says:




