
Hi,
I’m using a blueprint to backup Odoo databases and using kando to export them to a S3 bucket.
The output backup file is around 10GB.
I’m seeing a RAM spike in the kanister-job container doing the job, and then crashing with exit code 137 (OOMKilled), but there’s no limits and there’s enough RAM on the node it was scheduled on.
Here’s the status of the pod :
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2025-06-12T17:36:31Z"
status: "False"
type: PodReadyToStartContainers
- lastProbeTime: null
lastTransitionTime: "2025-06-12T17:07:18Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2025-06-12T17:36:29Z"
reason: PodFailed
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2025-06-12T17:36:29Z"
reason: PodFailed
status: "False"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2025-06-12T17:07:18Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: containerd://0eef6a65b0f8798be4f116ffe6ad316e92406ad5652e7f0b5802c4cf7f56f655
image: harbor/kanister-tools:top
imageID: harbor/kanister-tools@sha256:6c626b188bc41f1b2c65f4f638689e009dc157f19817795d59bb29135b7dcc0d
lastState: {}
name: container
ready: false
restartCount: 0
started: false
state:
terminated:
containerID: containerd://0eef6a65b0f8798be4f116ffe6ad316e92406ad5652e7f0b5802c4cf7f56f655
exitCode: 137
finishedAt: "2025-06-12T17:36:28Z"
reason: OOMKilled
startedAt: "2025-06-12T17:07:19Z"
hostIP: 10.148.10.21
hostIPs:
- ip: 10.148.10.21
phase: Failed
podIP: 10.42.1.38
podIPs:
- ip: 10.42.1.38
qosClass: BestEffort
startTime: "2025-06-12T17:07:18Z"
And snag from the pod describe :
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 50m default-scheduler Successfully assigned odoo/kanister-job-7kw8g to node1
Normal Pulled 50m kubelet Container image "harbor/kanister-tools:top" already present on machine
Normal Created 50m kubelet Created container container
Normal Started 50m kubelet Started container container
Warning NodeNotReady 21m node-controller Node is not ready
And the RAM usage :
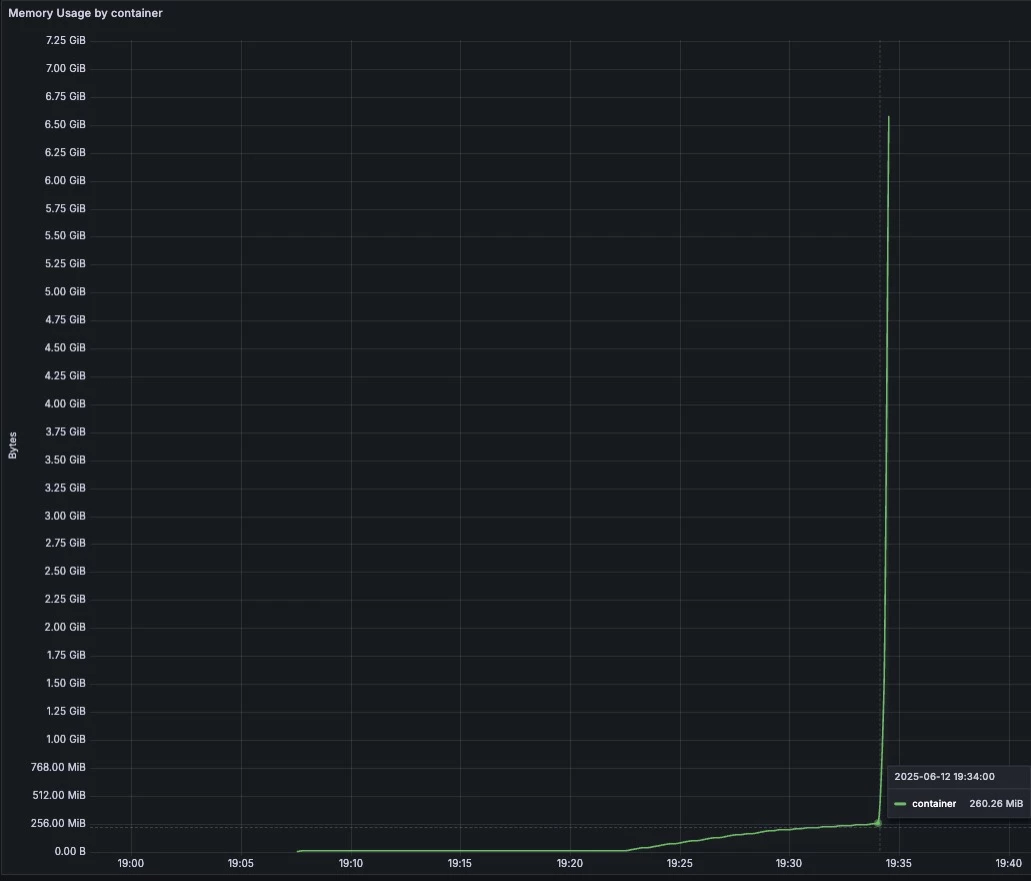
I’ve added notification to the job itself and can confirm that the S3 upload (cmd: kando -v debug location push --profile '{{ toJson .Profile }}' $ZIPFILE --path $BACKUP_LOCATION) starts at 19:34.
Any clue on how to let the pod finish the upload or limit the RAM used by kando ?
Thanks :)

