I’m new to Veeam and I really like how easy it is to create scheduled backups and to retrieve individual files.
Does anyone know what kind of compression Veeam uses when they create either increment or full backups? Thanks, Steve

I’m new to Veeam and I really like how easy it is to create scheduled backups and to retrieve individual files.
Does anyone know what kind of compression Veeam uses when they create either increment or full backups? Thanks, Steve
Migliore risposta di coolsport00
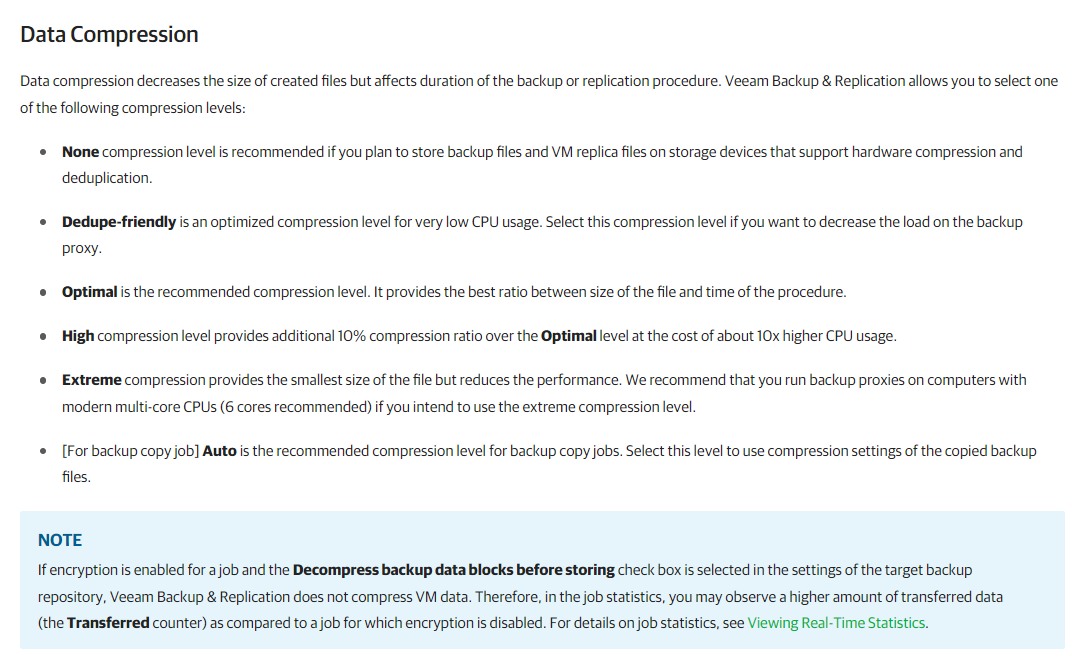
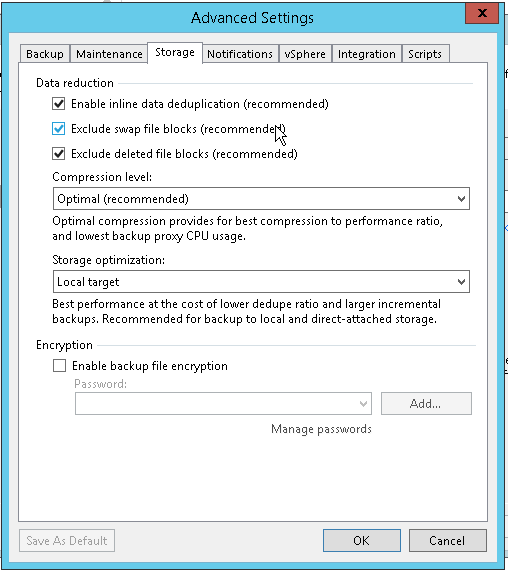
Others provided the compression options you have, and the User Guide screenshots/links to discuss what Compression option to use & when. If you’re wanting to know what Compression algorithm Veeam uses, it isn’t readily available in the Guides. You have to do a little digging in the Forums. It was also discussed in the older Veeam VMCE course. The algorithms Veeam uses for compression are lz4 and zlib as shown in this Forum compression algorithm change suggestion post. Hope that helps.
Cheers!
Non hai ancora un account? Crea un account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.