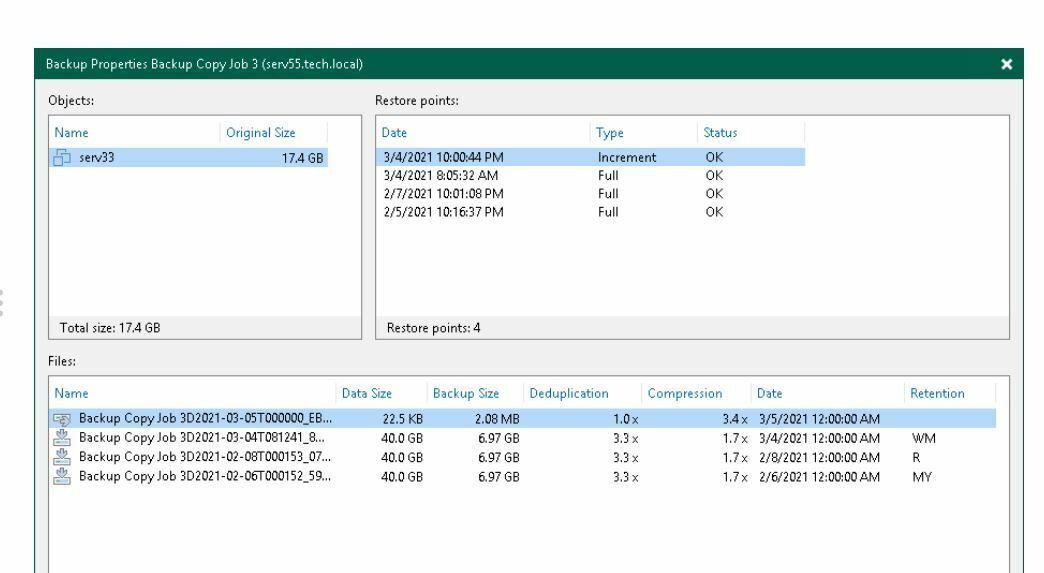
What does “Warning: some restore points failed to process” mean? I got this warning on a cloud copyjob and I can’t really find out what specifically it means or why it happened? Does this mean the copyjob failed or in a disaster recovery scenario that I’d have missing data that I couldn’t restore to from the cloud because it didn’t copy over?
I ran a new sync and it was successful, but I am wondering what this warning means and how can I present it in the future?