
Hello everyone,
This morning during my VMware VM backup job, I encountered the following error:
Error: Cannot proceed with the job: existing backup meta file 'Prio 0.vbm' on repository 'ds_veeam_sanctl03' is not synchronized with the DB. To resolve this, run repository rescan
As explained in the message, I initiated a rescan of the datastore on my NAS. The scan failed with this error:
11/01/2024 09:10:58 Warning Failed to import backup path nfs3://xxxxx:/|volume1|ds_veeam|Prio 0|Prio 0.vbm Details: '.', valeur hexadécimale 0x00, est un caractère non valide. Ligne 1, position 1.
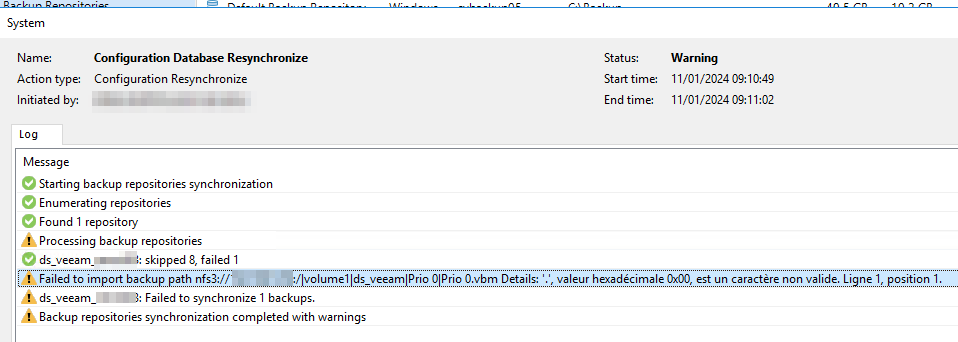
I did not find any information about this error in the knowledge base or other forum messages. I am using Veeam Backup & Replication 11.0.1.1261 P20220302.
Thank’s for advance.
Philippe.
