Final update….I have it now working. It turns out that the errors I was getting after resolving the above had to do with the VM not being attached to the disks. For instance, the VMX was pointing to SERVER1-interim.vmdk but I don’t believe those disks existed for some reason or had a different name (don’t recall exactly what happened). When I tried to edit the VM to remove the disks and then reconnect to the disks, it wouldn’t connect. In the end, I blew away the VM, deleted the disks and remaining files from the datastore and then reseeded/replicated the VM from scratch and it began working normally.
Now it’s just a matter of fine tuning the RPO policy and when I get alerts. I got a LOT of failed and success emails the first day or two because I’m attempting a 15 second RPO and it’s having a hard time keeping up at times, so I may have to back it off a bit. Which is fine...with snapshot replication, we had these at every 4 hours before implementing CDP, so a 1 minute or 5 minute or even half hour or so RPO would be acceptable in the case of these particular VM’s. I did end up changing my warning and failure alerting period to 2 minutes and 5 minutes respectively so my emails don’t get quite so blown up.
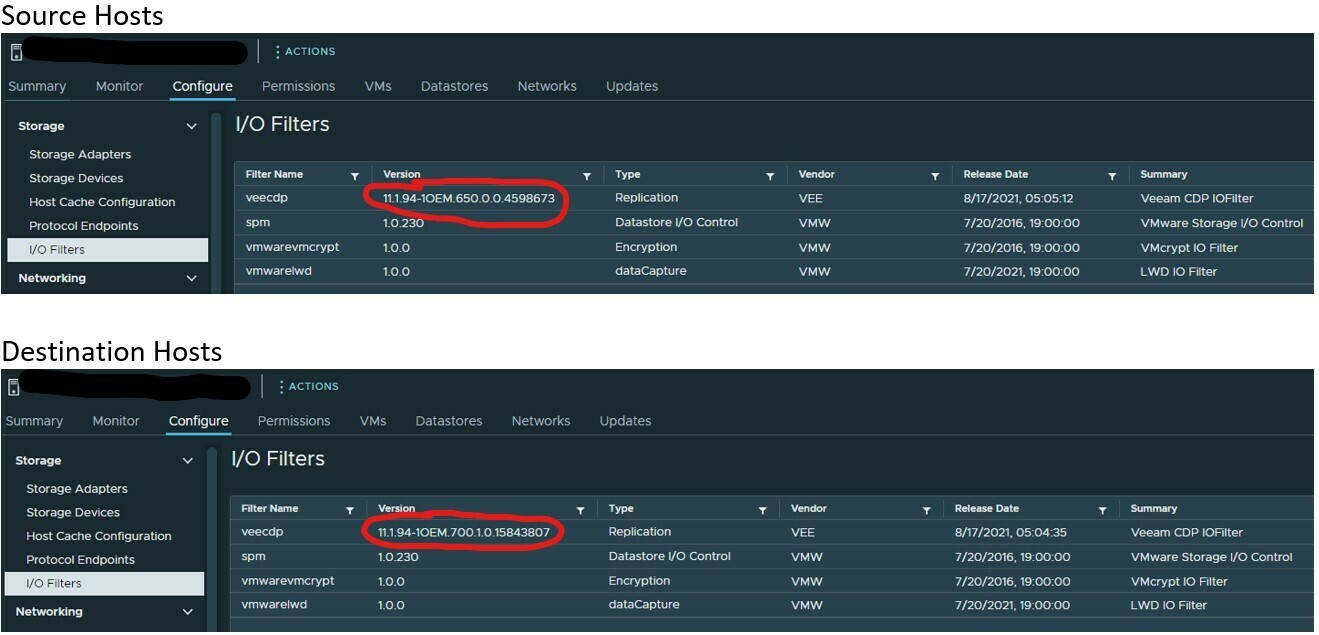
So in summary, it appears that the root cause of the issue was that the IO Filter versions didn’t match between the two locations even though the Veeam console was showing that they were up to date when managing the IO Filters. Putting the hosts in maintenance mode was critical here, but it’s a bit misleading as it apparently queues up the changes waiting for the hosts to go into maintenance, but the console shows it either passed or failed, and appears to only be able to be applied at the cluster level and cannot be managed per host. So that’d be a suggestion to clean that up a bit going forward in future versions, but for the first crack at it, I’m impressed. I can’t speak to if the version of the virtual hardware was an issue or not as upgrading didn’t resolve the issue. Everything else appears to have been the after-effect of the failed replications after the initial seed which were resolved by starting the syncs over from scratch.