Good day… We’re a small MSP with a cloud environment of about 120 VMs mostly on HyperV (our target platform) with perhaps 40% still on VMware. We run a 10Gbps core with Veeam running on a dedicated server, sub-interfaces into each customer network for guest interaction and 12 14TB spindles behind a MegaRaid 9361-8i controller. We use a separate set of 12 2TB disks for our internal systems.
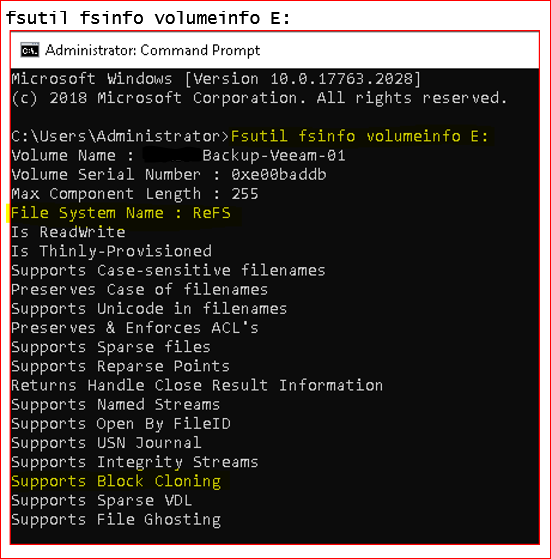
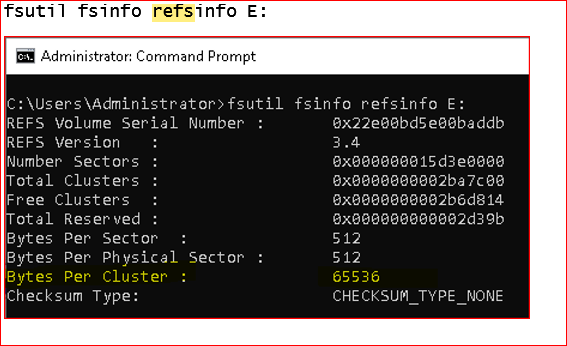
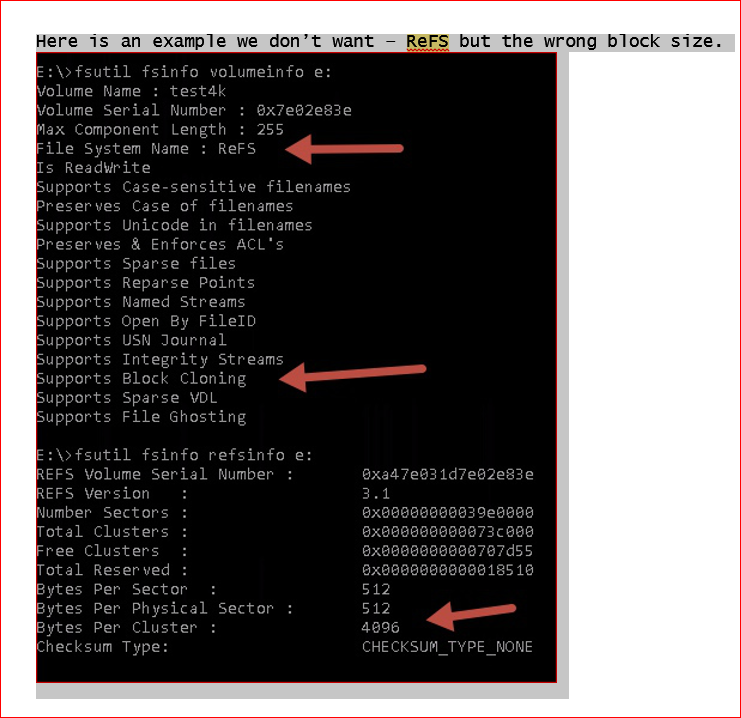
We’re on the hook for 90 days of backups per SLA and the last set offsite (we try to keep at least the last 30 days, but we’ve been adjusting this). We’re running on an older generation server with 2 Xeon 2620 v2’s (6C @ 2.1), 96GB of RAM and REFs on the repos. We’ve tried using 1TB of cachecade on the MegaRaid, but the size seems too small and it actually hurts us on performance. We’ve turned it off for now.
We have been struggling to keep up with our backup workloads, despite the box seeming to be okay from a resource perspective at the OS level. We’re right at the concurrent process limits based on the number of REPOs, OS, Proxy, etc. Jobs run long and then the copy jobs get hung up. Since they get hung up, the next set of backup jobs fail. We can’t seem to find the sweet spot for ensuring our backups are reliable (through consistency checks), not growing out of hand (real fulls that we can’t keep due to space issues and synthetic fulls that don’t really seem to work (they still take up tons of space)). We ran shadow protect for the longest time with no issues, but the model is completely different (we ran in-guest only and then offloaded copies using ImageManager). It kept up with collapses and transfers without incident.
We’re trying to figure out where to focus next. Add another 6 or 12 spindles and make the R50 (2x6 R5 now) bigger, adding another volume and putting it in the scale out repo as another extent, changing out the procs for more clock cycles and cores, getting 10Gb (current 1) to our secondary datacenter, getting rid of REFs? We can’t seem to get it right and I’m wondering if any others have struggled in this manner? Tech support has not really made many recommendations and IMO, most of the guidance is “squishy”. Anyone out there in a similar situation and how is your platform working? Thanks in advance!

Struggling with our datacenter backups - How are you approaching this?



Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.