Hi all,
I hope you’re well,
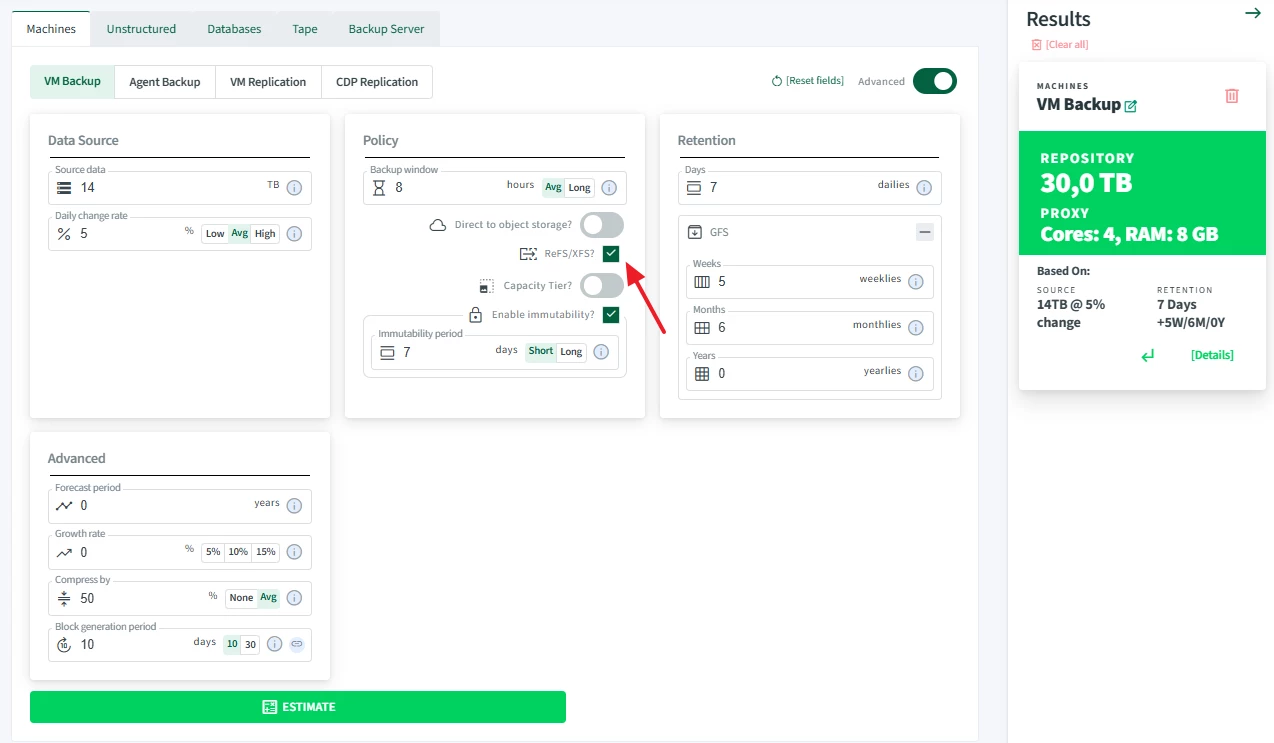
I require assistance in sizing the backup repository storage capacity for a VM workload running on vSphere with approximately 14 TB of source data. The backup repository well be hosted on a deduplication appliance either Dell EMC Data Domain or ExaGrid.
The backup policy includes:
7 daily incrementals
5 weekly full backups
6 monthly full backups
With offloading to azure blob storage cool tier and subsequently azure archive tier.
Could you help calculate the actual storage capacity required on the support this retention policy, considering deduplication and compression ratios best practices?