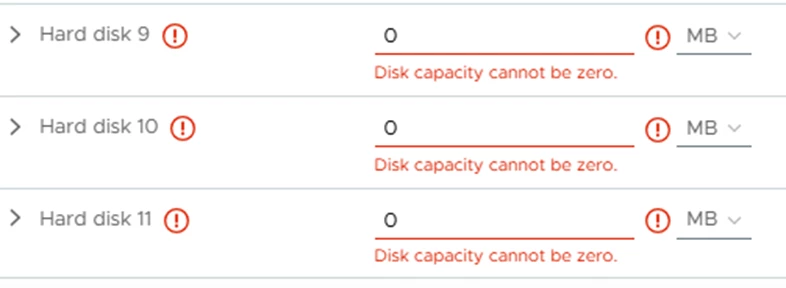
Recovered VMs not powering up in Datalab test due to unable to access virtual hard disks.
Have a couple of large VMs with multiple disks (60 and 90 TBs and 10 disks on each VM) that will not power up due to the error above. We are using storage failover and we have daily replication of the production volumes to our DR volumes. Replication status on our Storage device show that replication is successful but vsphere shows host incompatibility/permission issue accessing the disks.
I don’t think that this is either a host or permission issue since the other virtual disks for the same VMs can be seen in vCenter. There are other VMs in the Orchestration and these are the only 2 servers that would not come up. Below is a screenshot from vCenter.