in this configuration we run daily incrementals (Monday thru Friday) to disk (Linux Repository)
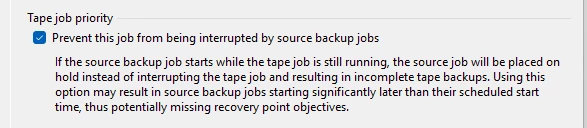
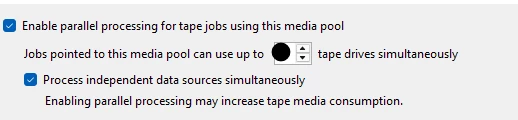
on Saturday Morning (just after Midnight) we start our Tape Backups job,(there is only 1 job that looks at the entire repository) it is a GFS job that Generates synthetic full backups for Weekly / Monthly retention. the HP Library target contains 2 LT08 Tape drive that are streaming at about 540MB/Sec. This would probably be acceptable with the exception of one 42 TB file server (starts about 1/3 of the way through the job and grabs one tape drive for 50 Hours+.) This causes the Overall tape Backup to run up to 76 Hours. Spilling into the next days incremental Jobs. I’m considering a change to the Daily’s Backups jobs to have them Generate Weekly Full backups on the repository, and then use Tape Copy Jobs to move the Full backups to tape? is it worth the effort? is it Supported?