
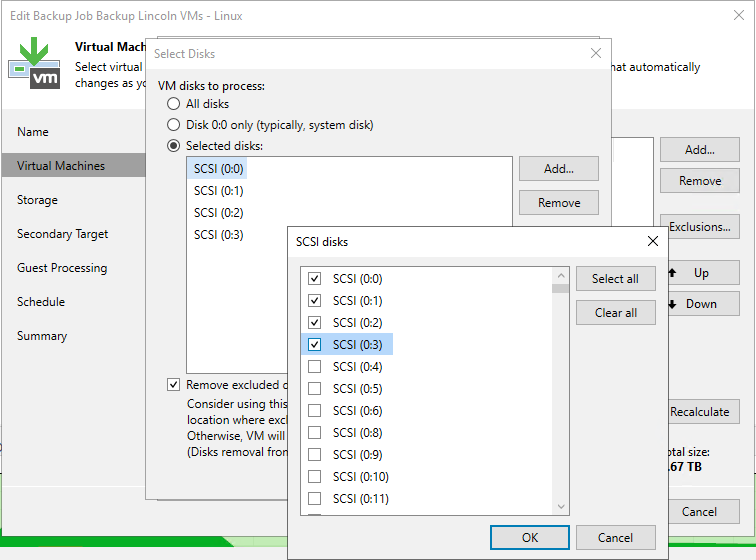
We have a large windows fileserver with many disks/shares and have been backing them up with an agent with separate jobs for each drive selecting the Volume. Im wondering that since its a VM should I have another VM job that backups the VM but just the C drive. Since we are currently only backing up volumes I wonder if we could actually recover the entire server.

Question
Large Fileserver VM



Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.