Hello everyone,
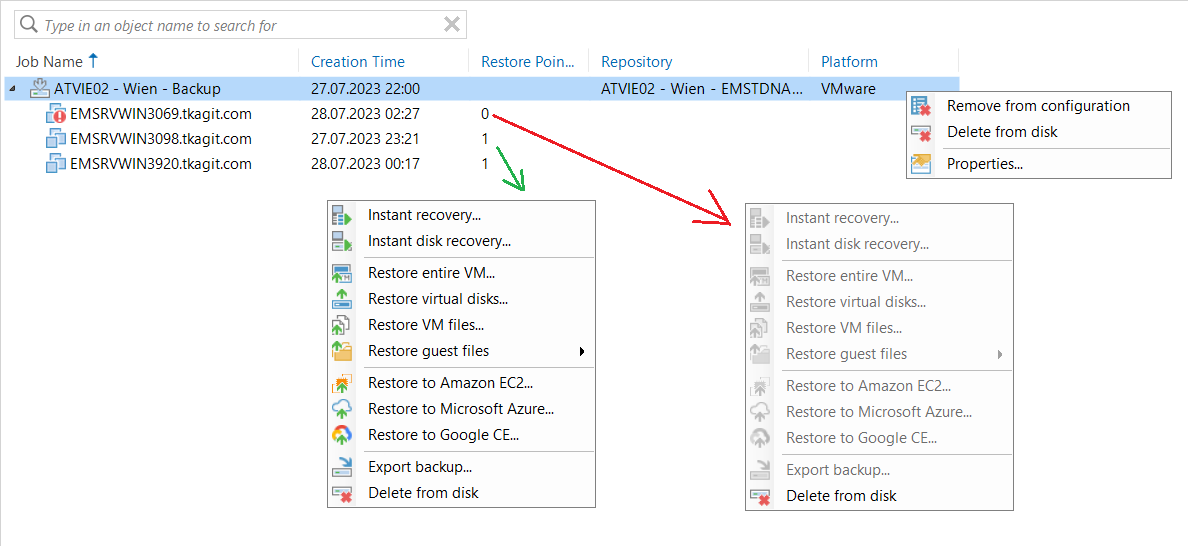
some backup files were manually deleted from D:\ storage (ReFS) and
now backup jobs don’t work.
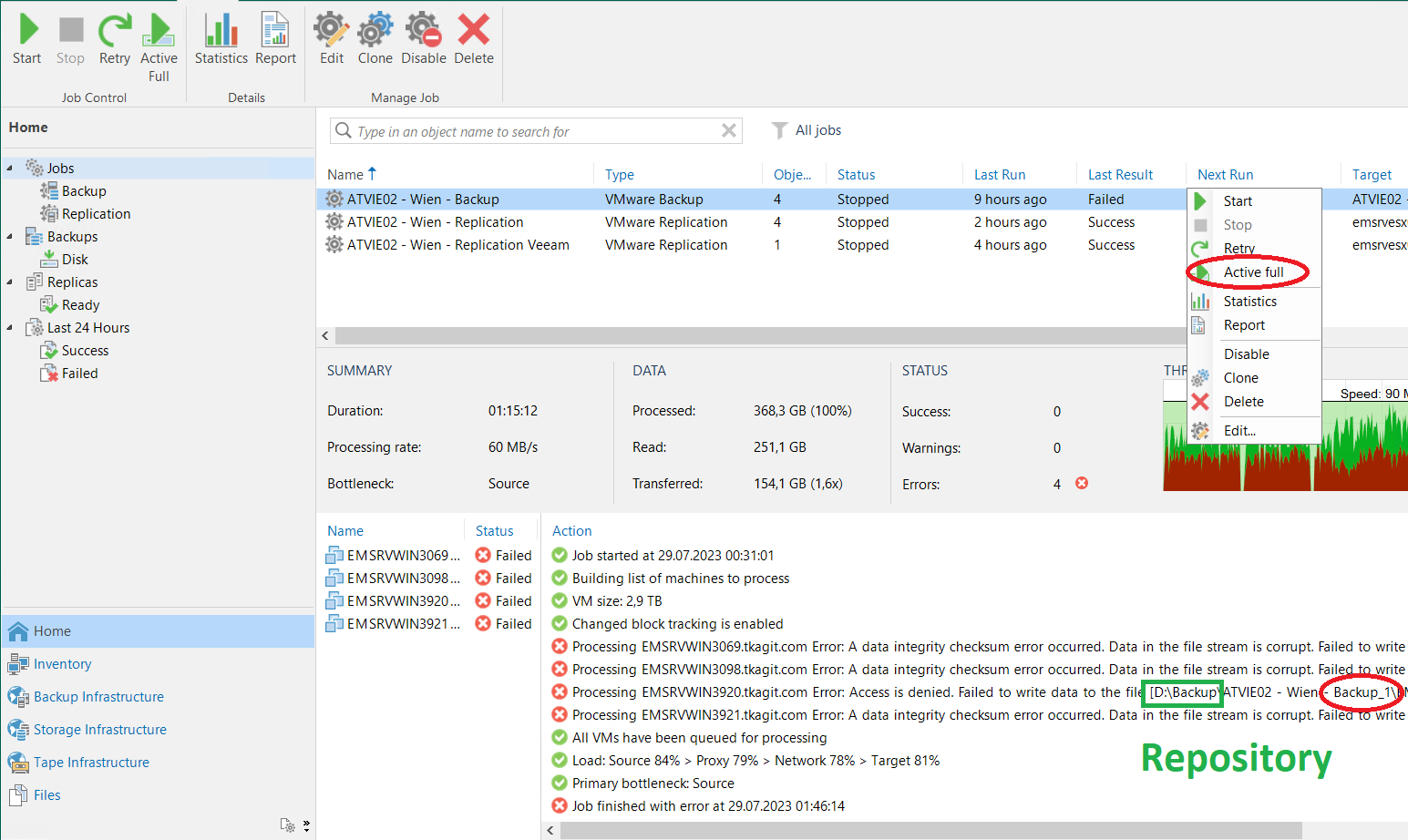
Failed to pre-process the job Error: A data integrity checksum error occurred. Data in the file stream is corrupt.
Failed to read data from the file [D:\[...].8D2023-07-26T204743_9167.vbk].
--tr:Error code: 0x00000143
--tr:Failed to parse metadata stored in slot [528384]
--tr:Unable to load metadata snapshot. Slot: [528384].
--tr:Failed to load metastore
--tr:Failed to load metadata partition. Delayed loading: [0]
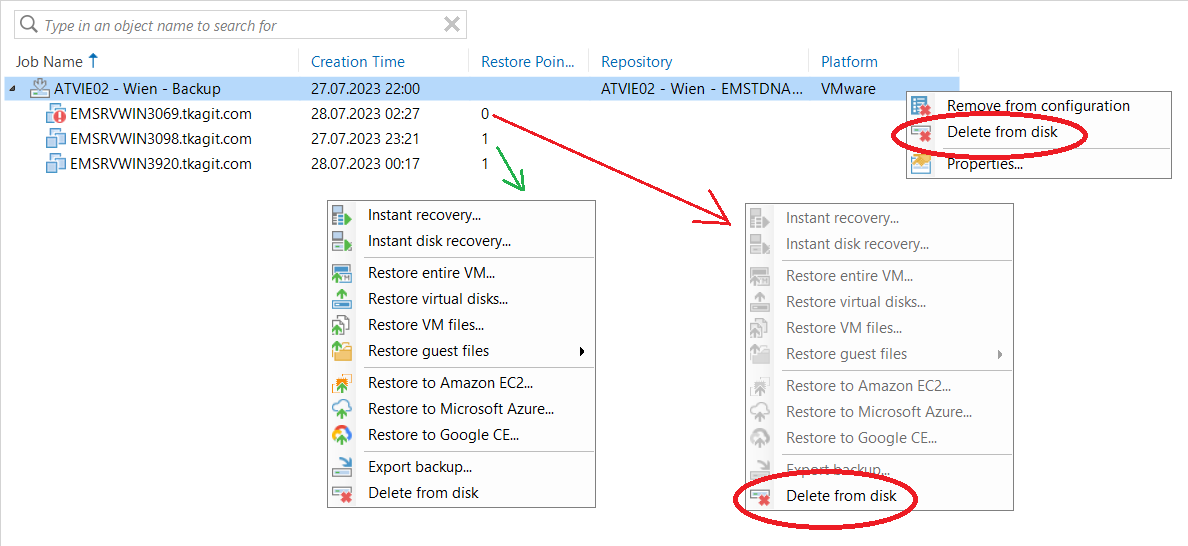
Failed to open storage for read/write access.We tried to create new repository (on the same storage) - didn’t help.
ReFS partition was formatted (yes, backup data are lost) - didn’t help.
The LUN on QNAP was re-created and we are getting the same error.
Yesterday I tired to uninstall Veeam and I made a fresh install on VM.
I didn’t help as well (note: I’ve removed %programdata% files, etc.).
It seems there are still some old parts of backup chains, surprising...
I didn’t find any solution, so maybe you could help? v. 11.0.1.1261
// I saw a topic where someone at the end suggested damaged RAM:
https://forums.veeam.com/microsoft-hyper-v-f25/case-05295340-refs-corruption-issues-t79430.html