

Backup Job Chains…
If I keep seven (7) restore points and run an Active Full on Saturday (point #7) what happens to the six (6) files in the prior backup chain? Are they useless but don’t get deleted because we’re keeping seven (7) restore points?
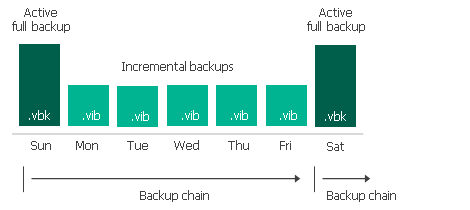
Backup Copy Jobs are different if not mistaken. If you keep seven (7) restore points and the seventh is a periodic full, the six prior restore points are deleted all at once?
