

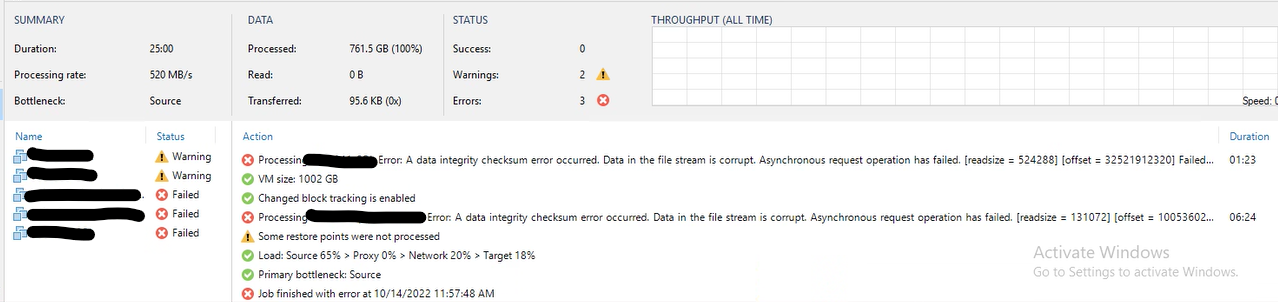
Had a client contact me this morning that is getting corruption errors on their backup copy jobs to the performance tier for their SOBR, but data appears to be making it out to their capacity tier, Wasabi, as far as they know (I didn’t check available restore points on that tier, but for sure the data is not sitting on the performance tier when I look at that filesystem).
Background configuration is that they are using in both their primary and secondary datacenters a Synology NAS that is connected to their Windows Repo server as an RDM disk presented via ISCSI to their ESXI hosts, volume is formatted REFS, 64k blocks, the usual. I realize that NAS’s are less than desirable, and my standard procedure is now to no longer use REFS when using a NAS as the backing array, but this is where we’re at. I will point out that another copy job, not going to a SOBR but to the same NAS is copying data successfully. I can’t say for sure off the top of my head if it’s the same volume or if this is going to a separate volume as they do have two volumes presented from this array to the repo server.
I suggested we open a case with support and the client is also going to contact Synology support as they just upgraded the firmware on their NAS’s last weekend which seems to be about when the issues started, but I didn’t know if anyone else had seen any similar issues and if anyone had any good ways to check for data corruption on the filesystem. Appears the usual tools don’t work on REFS volumes because more or less, REFS isn’t supposed to get corrupted….lol.

