
For the past several weeks, I have been deeply involved in managing a major cyber incident at one of my customers.
Disclaimer: This is a European customer classified as SMB! Talking about enterprise customers in larger scales this situation might be handled differently!
I also don’t privode too much details about this scenario to both keep the customer’s privacy and to not spread too much information for potential attackers.
On a Sunday, I received a private call from a colleague in sales who informed me that one of her customers had been hit by ransomware – their entire environment was encrypted.
I knew this customer well. Just a few weeks earlier, our teams had been onsite to discuss new disaster recovery strategies and present a modern concept. The plan was to implement a holistic and up-to-date backup solution using Veeam Backup & Replication, leveraging modern standards such as MFA, monitoring, anomaly detection and user accounting to replace the customer’s outdated and “fragmented” backup infrastructure.
Shortly before the attack, we had implemented an offsite backup to the Wasabi Cloud – just days before the environment was compromised. A small silver lining in an otherwise catastrophic scenario.
The first days:
Together with a team from my epmloyer, one of our forensic partners, and the customer’s IT staff, we quickly gathered to define the immediate next steps. By that point, the customer had already shut down all IT systems to prevent further spread of the malware. Unfortunately, all of their sites across Germany were already impacted.
What was affected?
- The customer’s entire production Active Directory domain
- All branch offices
- vSphere infrastructure
- All virtual servers (Windows Server only)
- All databases
- The entire Veeam Backup infrastructure
- All backup components (details below)
Next steps:
Since the customer had no functional disaster recovery or incident response plan in place, much of the response had to be handled ad hoc. The most critical point was to clearly define responsibilities and boundaries between all parties involved to avoid costly mistakes.
In the meantime, the customer – as many organizations in such a situation would – considered whether paying the ransom demand might be an option. However, this thought quickly moved into the background.
The attacker’s threats were presented as follows:
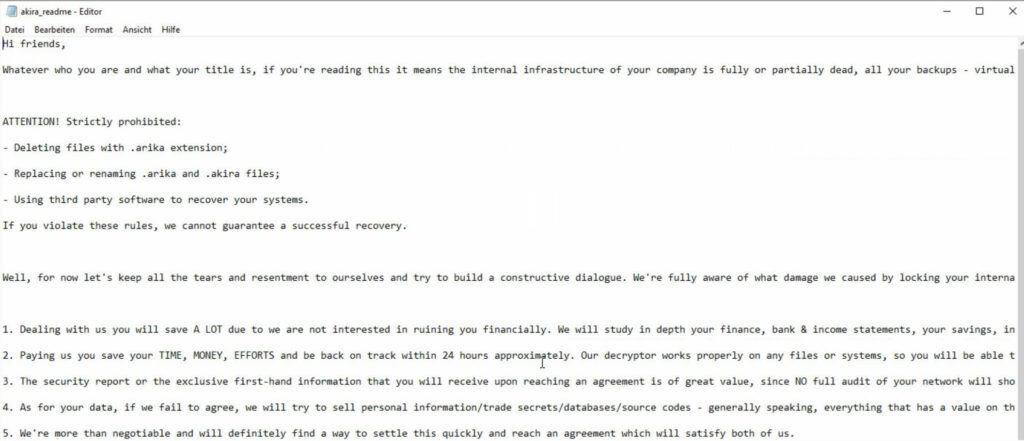
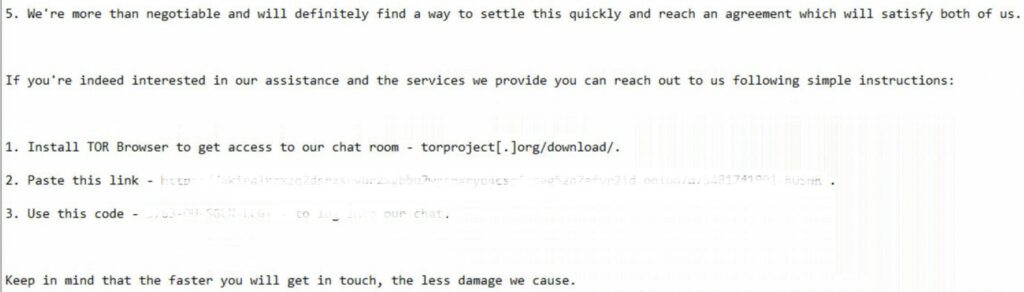
Step 1:
Establishing a temporary, isolated network at the customer’s headquarters. This provided a secure communication channel and a working environment for the forensic teams.
Step 2:
Deployment of a temporary Veeam Backup & Replication server to analyze the available backup data.
In parallel, the forensic team investigated the original VBR server. The outcome was clear: all system and program files were encrypted, making it impossible to start or recover the application.
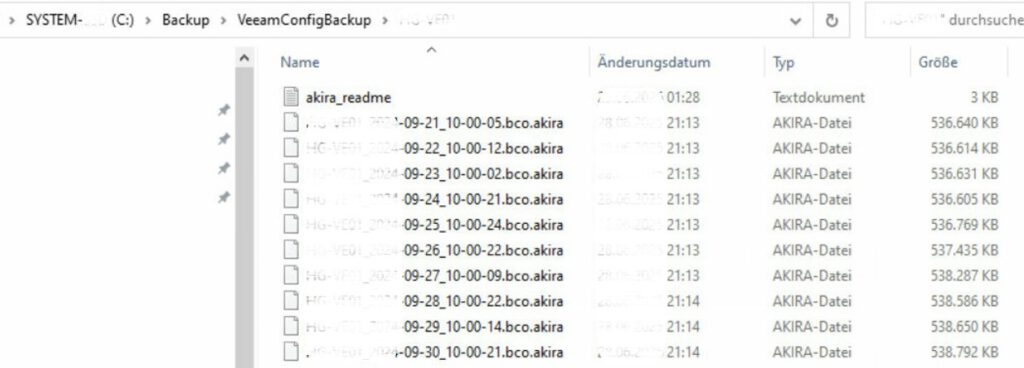
The customer was operating an LTO-9 tape library, but had never removed a single tape from the system.
As a result, the attacker was able to encrypt all 49 data tapes:
Step 3:
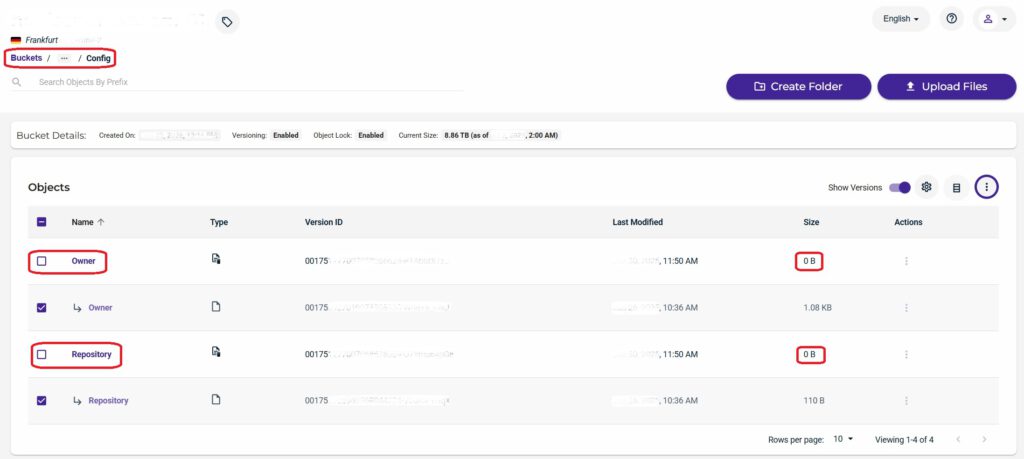
Reconnecting the Wasabi Cloud repository to access immutable backups. While the data itself was stored in immutable form, the attackers had managed to delete the repository configuration from the cloud tenant. Since metadata and configuration files change frequently, these cannot be stored in immutable mode.
At this stage, I contacted Veeam Support – and their guidance was crucial. By leveraging versioning (a prerequisite for immutability), we were able to use an S3 browser to access the last valid version of the repository configuration. With that restored, the temporary VBR server successfully recognized the repository and could access the backup files.
Step 4:
The initial goal remained to restore basic communication. To achieve this, we deployed a Microsoft Azure Virtual Desktop (AVD) infrastructure. This allowed selected users to access email again and to bring the telephony systems back online.
At this stage, the rollout did not target the entire company. Instead, only a group of key users was onboarded first, ensuring critical business functions could be resumed.
In parallel, the forensic analysis of the compromised environment continued.
Challenges of the Previous Veeam Configuration:
- The VBR server was joined to the production Active Directory domain
- The VBR server was located in the same network as all other servers
- Tape library management was domain-joined
- The tapes were never ejected and remained inside the library
- Backup repositories (deduplication appliances) were domain-joined
- Passwords and PAM tools were not stored offline – they were encrypted as well
- No emergency communication channels had been considered or defined
- No clear escalation and reporting chains were in place
- Domain Administrators (built-in) had unrestricted access to every component
How did the attackers get into the system?
Our forensic team’s initial analysis revealed that the attacker most likely moved laterally within the customer environment via the domain-joined Veeam server.
It is still unclear how exactly the attacker obtained the Domain Admin credentials, but given the previous configuration, there were multiple potential ways to capture these credentials.
The subsequent encryption of systems was carried out over the network, leveraging the attacker’s global administrative privileges.
Timeline:
- 4 days between first Wasabi Offsite backup and compromise
- 3 days until the initial emergency team was declared after the impact
- 1 more day until emergency communications were established
- 7 more days until a global AVD infrastructure was established and rolled out across all sites
- 4 weeks later until the branch offices and remote productions were partially running again
- many weeks later until the emergency and re-design processes got established to stable basis
Learnings:
The customer had several opportunities to detect the attack earlier and thereby minimize the overall damage.
The following measures could have been taken:
- Create emergency plans and verify them regularly to have working measures in case of a disaster
- Create emergency communication plans and both verify and update them regularly
- Have offline documentations of DR systems available (including glass break accounts and passwords)
- Remove DR systems from the production Active Directory domain
- Perform planned password changes regularly
- Use cyber incident insurances (additional requirements may be to fulfill)
The following Veeam options and technologies might have helped before the impact:
- Veeam Security & Compliance Analyzer
- Identify and fix potential attack vectors
- Veeam SureBackup
- Identify potential threats before they get executed in production
- Tape ejection
- Make sure tapes get ejected to avoid unwanted access
- Veeam ONE with anomaly & malware detection
- Identify anomalies (e.g. longer backup windows or password changes)
- Backup file encryption
- Avoid to let attackers use data they might have extracted
and much more…
What happens now – weeks later?
The customer is very slowly recovering from the scenario. The lessons are learned but it became clear that many major changes have to be made according to cyber security standards and data resilience.
The incident is slowly changing from a “dirty production” into a green zone. The project itself (“results of the incident”) will be with the customer for another few months but regaining control of the situation was the strong focus.
We now offer SLA-based services to the customer and help him with ongoing tasks to let him focus on moving further into the green zone.
Please also see the article on my personal blog:
23 – Lessons learned: Cyber attack in the field (SMB) – Disaster and Recovery
