

An interesting question arose some time ago. A customer changed permissions of files on a Windows file-server VM. Changes were replicated using DFS. So far so good, but the amount of data that was processed at next incremental backup of target VM was even more than a full backup. Because incremental backup is based on VMware Changed Block Tracking (CBT) feature, it was suddenly interesting to know whats the size of a CBT block. After some recherche I did not find an answer to this question. But I did find a great script that calculates CBT incremental backup size. Based on this script I created the following script to list the amount and the size of blocks changed in between of two snapshots.
Outcome in short
When using the script – described in detail later – to show CBT blocks I was surprised. I thought there will be a number of fix-sized blocks that are marked to be backed up. But – assumed, script works correct – there isn’t a fixed size of CBT blocks. There seems to be a wide variance of block sizes. I observed sizes from 64KB to many MBs. Probably because of that and because of the cluster-size of the file-server, a lot more data is processed during incremental backup compared to actual changed data.
How CBT works in (very) short
When enabled, CBT tracks changes in VMDKs and saves maps of changes to *-ctk.vmdk file for each *.vmdk. When backup-software (like Veeam B&R) queries CBT it can ask for changes between the current snapshot – taken just now – and the snapshot that was taken at last backup. CBT returns a number of blocks that contain all changes during this period.
About the script
You can do you own testing using the following script. Basically the script works for one VM. It creates a snapshot, to set the start-point of changes. In reality this would be the snapshot created during last incremental backup. After removing this snapshot, script pauses and you can do your changes within the VM. To continue the script, press Enter. The script creates a new snapshot to set the end-point of change-interval. Now CBT is queried for changes that backup-software would process during a incremental backup. Furthermore the amount of blocks are shown: number of unique block-size.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
|
Outcome in long
With the tool in hands I did a few tests. I used a VM (Windows 2016) with two drives. One just for testing. This partition is formatted in NTFS using a 4KB cluster-size.
No changes
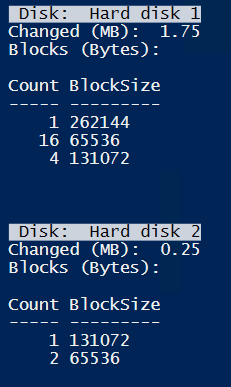
First test is to run script without changing anything between snapshots. Anyway, as you can see there are still changed blocks returned by CBT. There are 64KB, 128KB and 254KB Blocks. Hard disk 1 is the c-partition, Hard disk 2 is an empty test-partition.
A few files
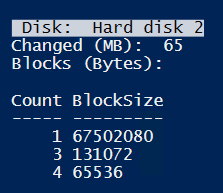
For next test I copied a ~64MB file to the partition in between snapshots.

Result of querying CBT is shown in next screenshot. This fits very well: 65 MB to backup.
Deleting fine between snapshots:
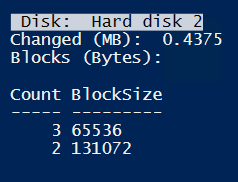
Not much to do for backup.
A lot of small files
Lets continue by testing small files. For this I created 1024 files of 1KB size using the following commands.
| 1 2 3 |
|
Because of the cluster-size of 4KB, one file takes 4KB on disk. From Windows NTFS perspective one file (left) and the whole directory (right) looks like this.

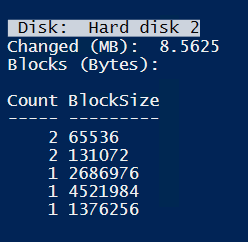
For CBT, new files causes 8MB of backup. Also the variety of block-sizes is notable. This is no matter of fragmentation, because I re-tried and formatted volume before. Nearly the same result.
What happens, when changing file properties without changing the content of the file? Therefore I “touched” files using these commands.
| 1 |
|
CBT talks about 3MB of changes – just changing meta-data.
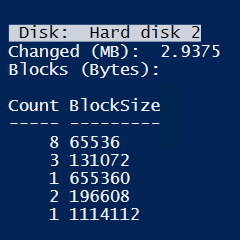
Deleting all files is nearly the same.
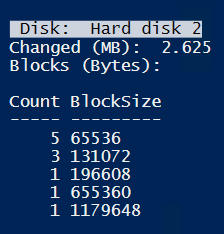
A lot of bigger files
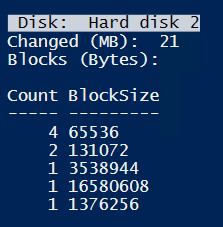
Now testing files in 5KB size – bigger than cluster-size.

Quit big CBT blocks.
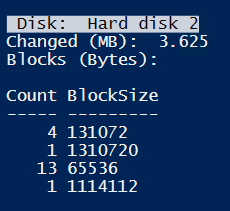
Changing meta-data of all files by touching them. Still about 3MB.
.
A lot of random-sized files
Now about 450 files were created with a average size of 50KB.

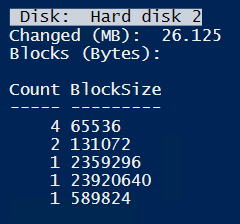
For CBT about 26MB are marked as changed.
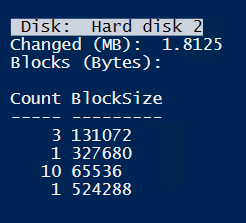
“Touching” all files results in 1.8MB changed blocks. So this seems to be related to file-count, not size.
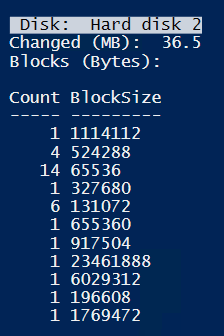
Now changing each file and append a few letters to each content. The result is in increment even larger than after creating all files.
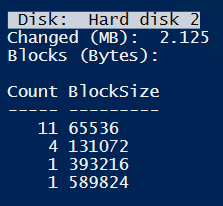
Deleting all files results in about 2MB meta-data changes.
IMHO
CBT is here for a while. Despite of a few ugly bugs (silent corruption of backups) it works fine. Because it is widely used to enable incremental backups it is important or at least interesting to know how it works and about its weaknesses. So in certain situations much more data is marked for backup than really changed. But meta-data updates seems not to be responsible for this, as you can see in this post. Creating files and file-content changes lets backup grow rapidly.
In my opinion the reasons for this are
- A lot of small files, because for small files the overhead of the filesystem cluster-size is huge.
- The smallest observed size of a CBT block was 64KB.
From my perspective CBT is a useful feature with some limitations. Because of the mixed nature of virtual workload/data, over all CBT does a good job!

