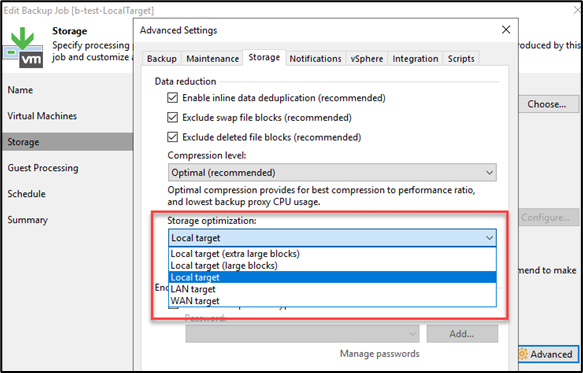
While I was studying for the VMCE, a detail on deduplication caught my attention.
I’m talking about inline deduplication.
What's about?
Inline deduplication is a feature offered by Veeam B&R and it’s used to reduce the amount of storage space required to store backup data by removing duplicate data. One of the main benefits of inline deduplication is in fact that it can significantly decrease the amount of storage space, amount of time and resources required for backups and this can be especially beneficial for organizations that generate a large amount of data on a regular basis.
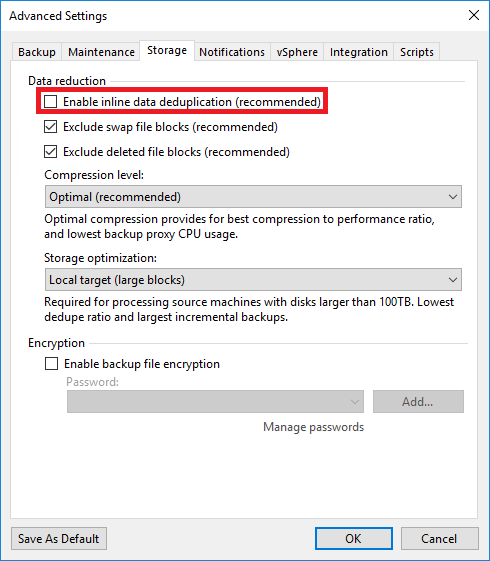
Another advantage of inline deduplication is that it can improve the efficiency of backups, ‘cause backups can be completed faster and the amount of data that needs to be transferred and stored is reduced.
An example?
An immaginary company named CatsFood has a file server that contains 10 terabytes of data and the organization wants to create a backup of this file server using, proudly, Veeam. Without inline deduplication the backup would require 10 terabytes of storage space. However, with inline deduplication enabled Veeam would identify and remove duplicate data before creating the backup: in fact if file server contaisn multiple copies of the same file or multiple versions of the same file that have been modified slightly, Veeam's inline deduplication feature would identify these duplicate files and “remove them”, reducing the amount of data that needs to be stored in the backup. Let's say that the inline deduplication feature was able to remove 2 terabytes of duplicate data. This would mean that the backup would only require 8 terabytes of storage space, as opposed to 10 terabytes without deduplication.
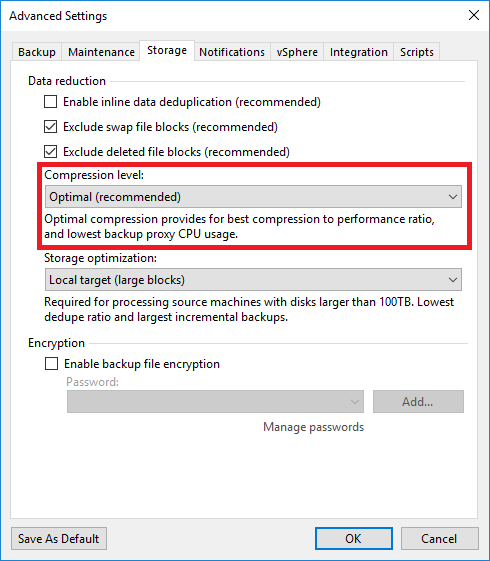
This is a significant reduction in storage requirements and can help organizations save on storage costs. It's worth noting that Veeam's inline deduplication feature can be configured with different settings to optimize the performance and storage space usage. For instance, you can configure the level of deduplication, the block size and the compression level.
And what if repository’s a dedup storage?
Best practices says disable inline deduplication setting when writing into deduplication storages.
Find more here:
Deduplication Appliance Best Practices: https://www.veeam.com/kb1745
Help center: https://helpcenter.veeam.com/docs/backup/hyperv/compression_deduplication.html?ver=110