

Recently I shared a post on how to set up Veeam HA in the VDP v13 BETA preview. In this post I’ll walk you through how to perform a Switchover and Failover operation to the 2nd VBR node. There are no pre-requisites per se’ before performing the steps listed below, except for the HA enable configuration steps I shared in my Part 1 post. So let’s get to it, shall we? 😊
Perform a Switchover
- First, log into the Remote Console to the Cluster IP. Review my previous post on what that IP is
- Next, go into the Backup Infrastructure Node > Managed Servers, find your 2nd VBR node and rt-click > Switchover
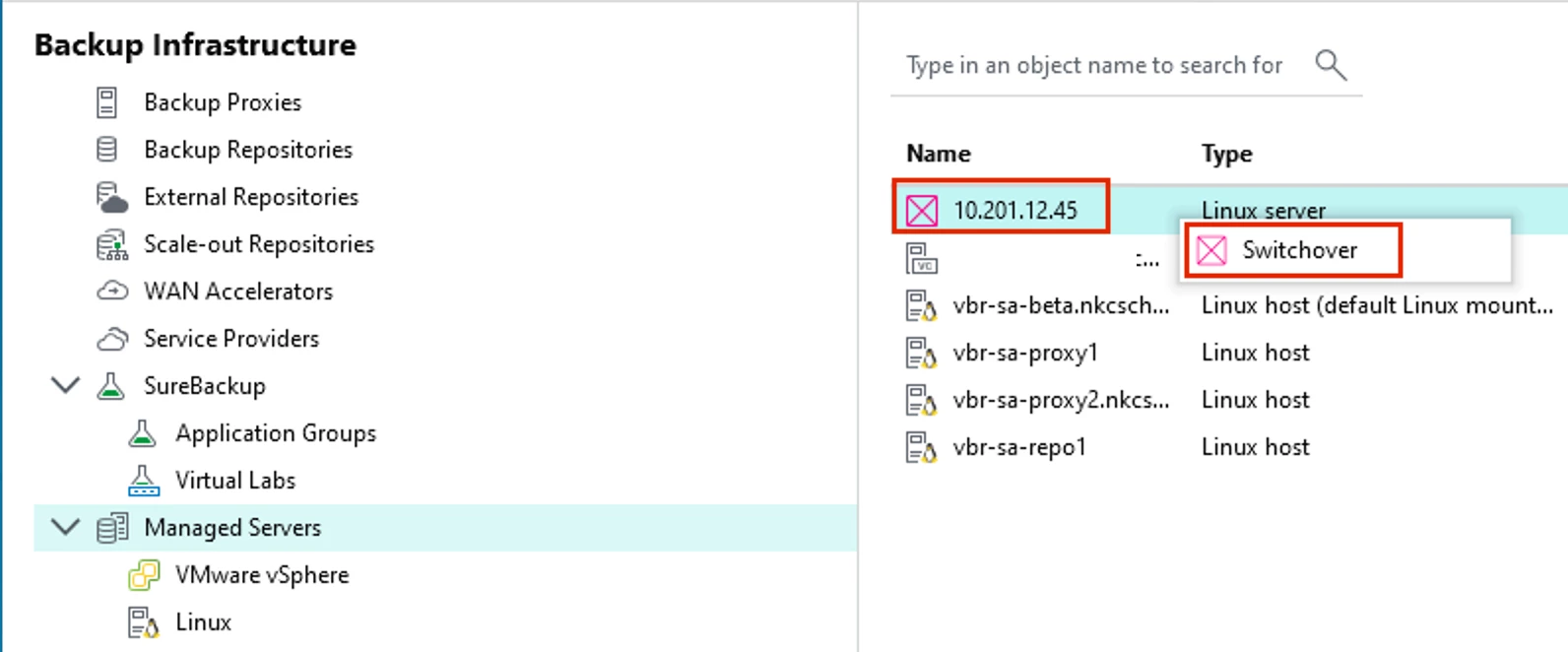
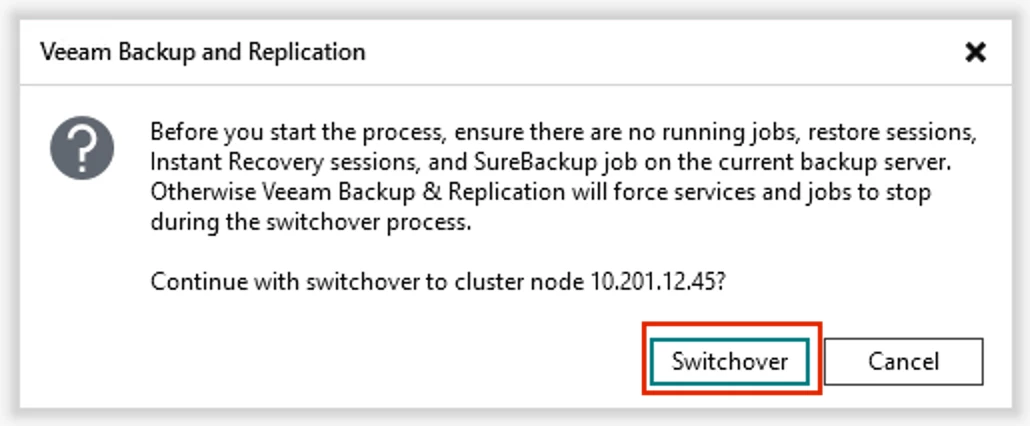
VBR HA Cluster Switchover - Verify the items in the next message are taken care of. If not, just click Cancel and take care of them before proceeding; otherwise, click Switchover
VBR HA Cluster Switchover Message - After you click to Switchover, the Remote Console will be logged out in 5 seconds
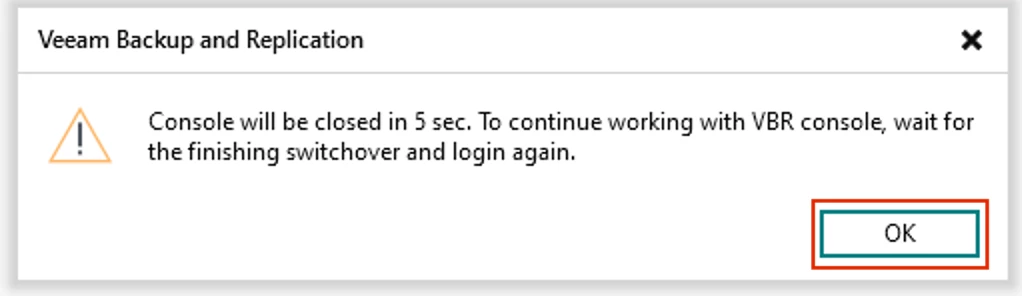
VBR HA Cluster Switchover Logout Message - After the Console is logged out of, wait roughly 10-15mins for the Switchover process to complete, then log back into the Remote Console with the Cluster IP NOTE: Before Switchover, if you connected to the Linux OS Console of the primary VBR node, you would’ve seen the IP of the primary change from its configured static IP to the Cluster IP used when creating the HA Cluster in the previous post. After the Switchover, the Cluster IP is now assigned to the secondary VBR node. Also, after initiating the Switchover process, I monitored the Console of my secondary VBR node and saw the IP change from its statically-assigned IP to the Cluster IP in about 10mins, but it may take longer or even shorter for you depending on your environment
- Another item I should share about the login here → when connecting to VBR through the Cluster IP after initial HA Cluster setup as shared in my Part 1 post, if you enabled MFA in the Remote Console (should be enabled imo), you should have been prompted with configuring MFA. Make sure to use this new MFA account to login with, not the MFA account associated with either VBR node1 or VBR node 2
- After you do login to the Remote Console, return to the Backup Infrastructure Node > Managed Servers section and notice VBR node 1 is now assigned as Backup Server (Node 2) . For example, looking at the 1st screenshot I shared above, the IP of my former primary VBR node was 10.201.12.40 (10.201.12.45 in the screenshot is/was my secondary node), so I saw Name: 10.201.12.40 Type: dBckup Server (Node 2) in the Console
- Jobs and tasks should run as normal; verify this to be true in the Home node of the Console. For me, I ran a test job which I created and successfully ran before I performed the Switchover
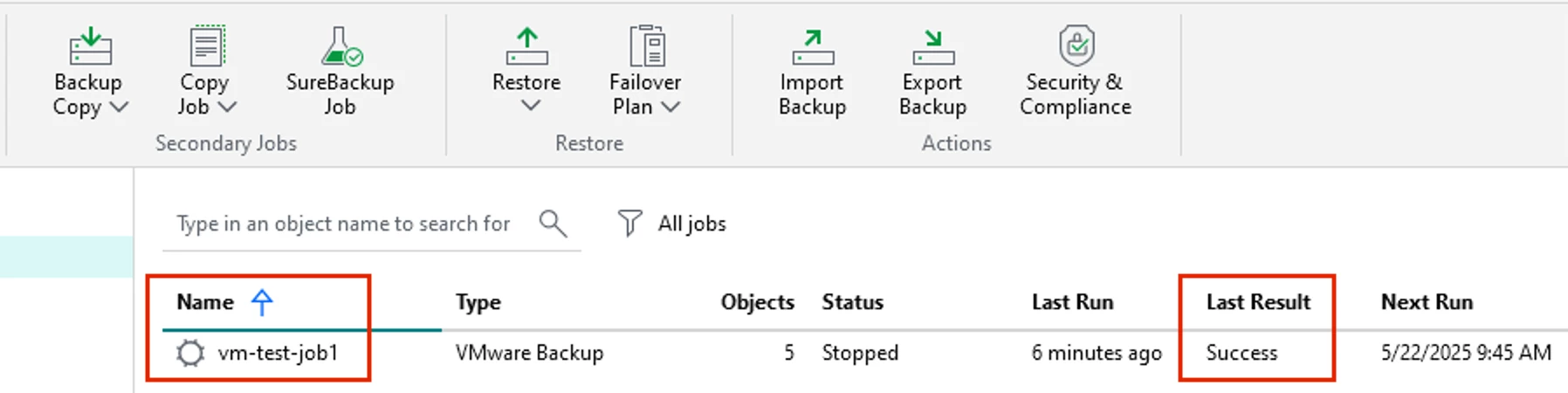
VBR HA Switchover Test Job Successful Run - After you resolve whatever issue you had for your VBR node, you can failback your Veeam Backup environment to your primary node performing another Switchover following the same steps shared just above:
- Log into the Remote Console with the Cluster IP and verify you have no Jobs, etc. running (Disable them if needed)
- Go into the Backup Infrastructure Node > Managed Servers, find your 2nd VBR node (the former primary) and rt-click > Switchover
- The same 2 messages shared above will display. Click Switchover then Ok to failback to your previous primary VBR node. Wait about 10mins before attempting to login to the Remote Console with the Cluster IP
Perform a Failover
If your primary VBR node goes down unexpectedly, you can perform what Veeam calls a Failover to your 2nd VBR node. To test how this works, perform the following steps:
- As with the Switchover task, login to VBR with the Remote Console to the Cluster IP and verify you have all Jobs, etc. Disabled. By the way, before peforming a Failover, Veeam recommends connecting to VBR with the Cluster IP at least one time before running this task. After logging in and verifying no Jobs are running, etc. close out of the Console
- Go to the Console of the primary VBR node and shut it down. Be patient...this process can take awhile (10mins or so)
- Open the Remote Console and attempt to log back into the Cluster IP. After 2 or 3 minutes, the Console should prompt you with the following message stating your primary VBR node is unresponsive:
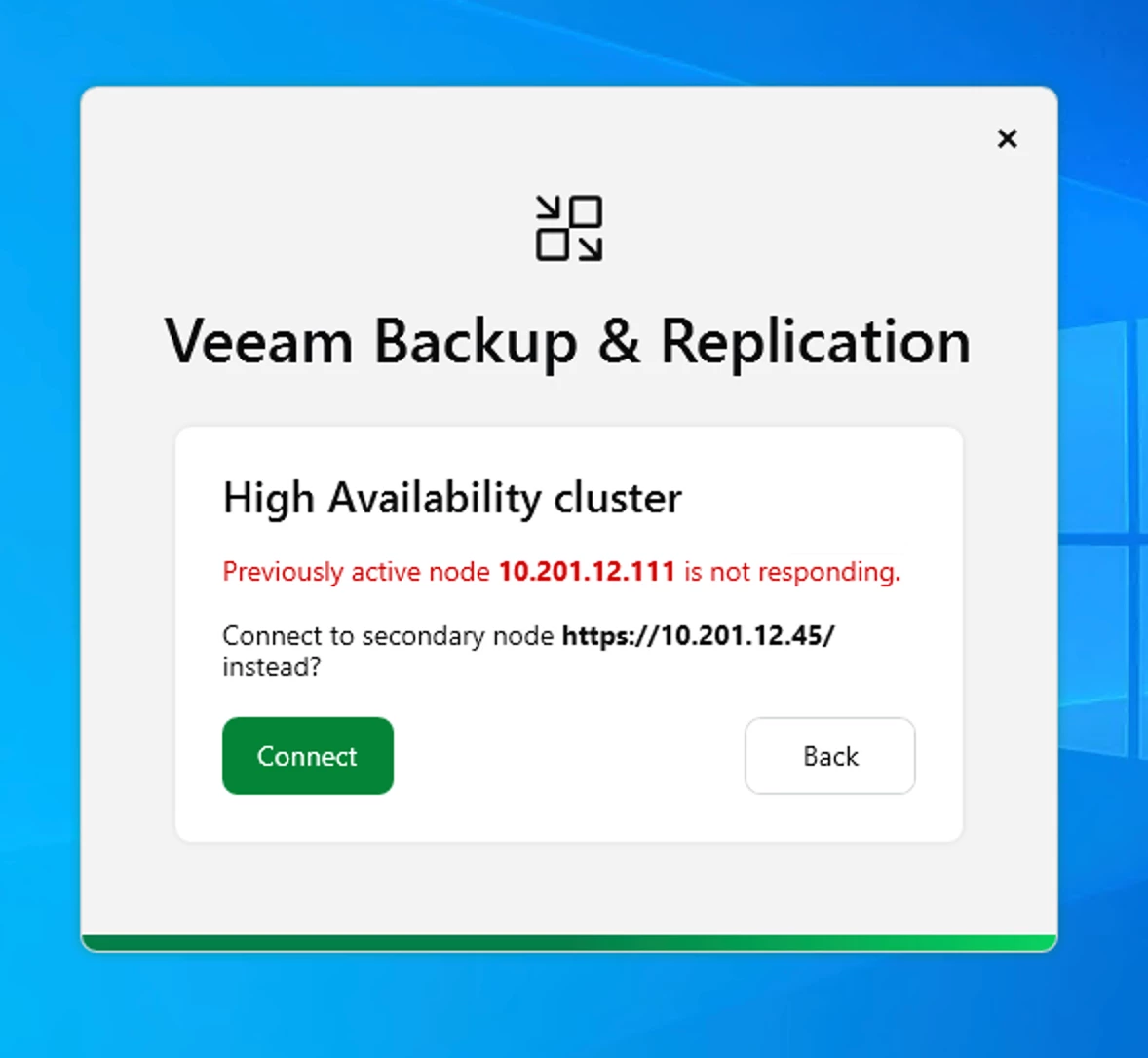
VBR HA Unresponsive Message - Click Connect and attempt to login with your credentials and Cluster IP MFA account
- You’ll then get the following prompt
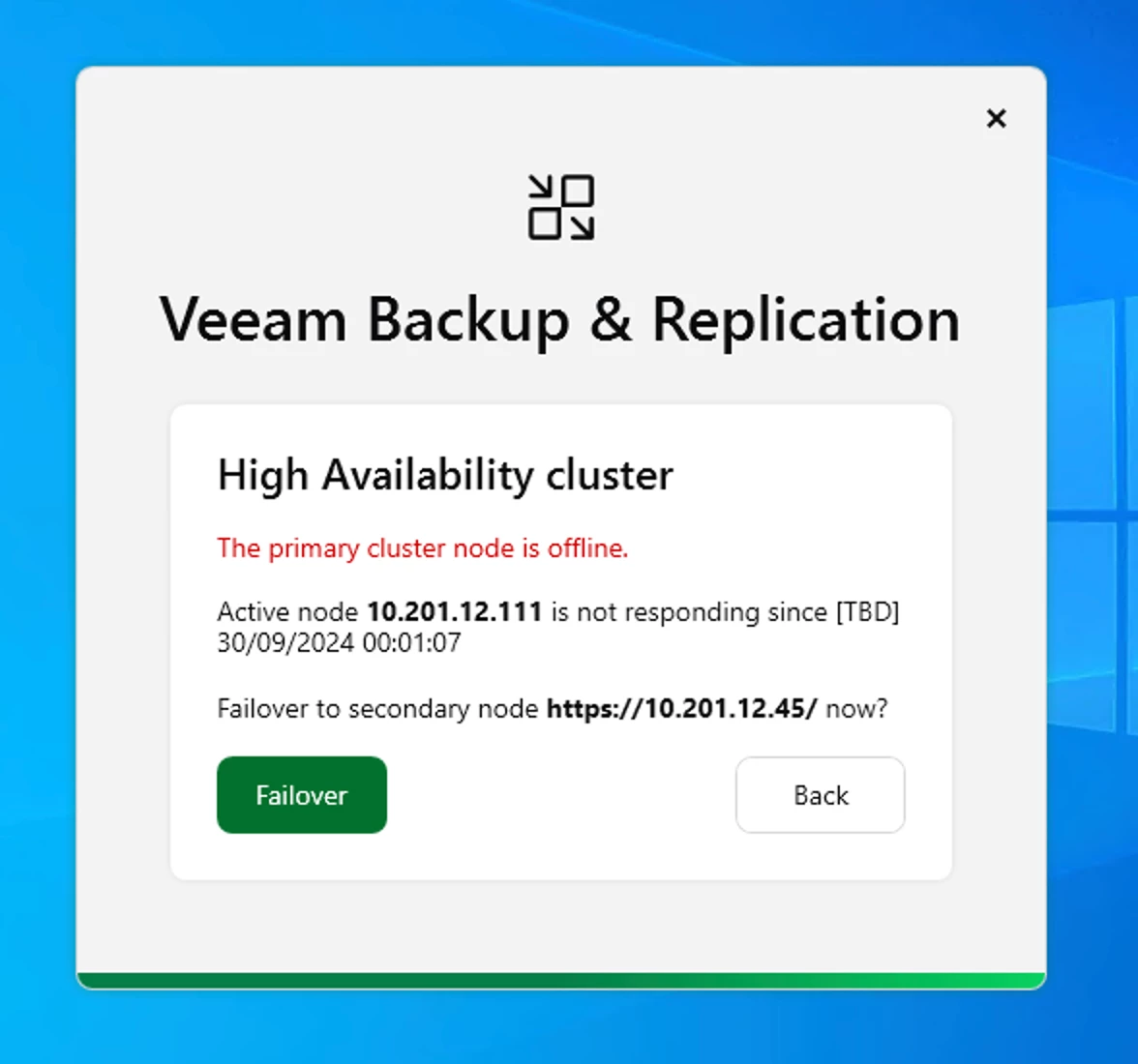
VBR HA Failover Message - After the Failover process completes, currently...at least in the BETA preview, you’ll notice the Console Failover process stop and the login screen will display. This took about 6-7mins for me. Do not login! First, close the Remote Console login window, then verify the Cluster IP is on your secondary VBR node Console and not its static IP, then re-open the Remote Console and attempt to login to VBR with the Cluster IP. Hopefully, as it was with my testing, it’ll be successful. Not being able to log in right away..having to close the Console and re-open...is a known bug in the BETA preview. This will hopefully be addressed before v13 reaches GA
- Currently, with the BETA release, there is no process/information readily available to recover from a Failover..i.e. to revert your VBR environment back to your former primary VBR. If I can get information on how to do so, I’ll update this post.
And that’s all there is to it! 😊 What do you all think? Pretty neat redundancy feature, isn’t it? If anyone has any questions about the steps above, feel free to ask by creating comments below. If I don’t know the answer (this Veeam v13 version isn’t yet released of course, so there is also no User Guide), I’ll try and get your question(s) answered by a member of Veeam.
Thanks for reading!
