

Introduction
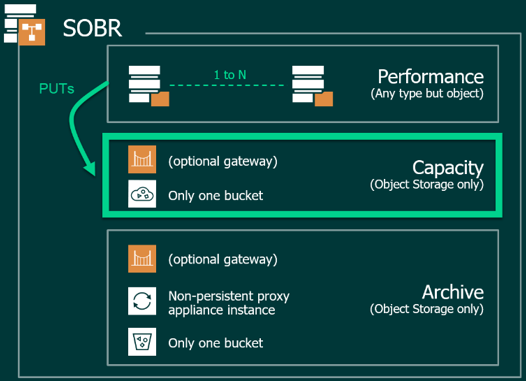
SOBR is a logical construct allowing a backup administrator to group storage extents together to form a multi-tier storage "pool" to ease the management of backups.
The Performance Tier holds the "operational restore window" parts of the backups on-premises, typically on block or file-based storage, while both the Capacity and Archive Tiers allow expansions to Object Storage.
The Capacity tier offers two types of offload operations:
- Copy
- Move (after x days).
Note: You can combine both offload operations.
When offloading backups to the Capacity Tier, the “.VBK” or “.VIB” shell is cracked open. Veeam backup Meta-Data and Data bits become Objects stored onto the Capacity Tier via PUT operations.
Note: It is safe to assume that 99% of all objects created are backup Data bits, the rest is backup Meta-Data.
With most public cloud providers, API operations are not free.
If you are considering an "on-premises" Object Storage solution, be mindful of vendor-specific limitations in their ability to handle large amounts of object metadata (and therefore number of objects).
Note: Object Storage Device metadata service implementations vary from vendor to vendor. Some vendors store object metadata in databases while others may store object metadata on disk using placement technique such as consistent hashing. Each implementation comes with its own limitations.
The architecture specific limitations of the object storage vendor’s metadata service are typically expressed in one or a combination of the following metrics:
- Objects ingest rate (objects per second) and maximum object size
- Data ingest rate (MB/s) and maximum object size
- Bucket maximum size for a given object size
- Maximum number of objects per bucket
The following formulas propose a simple method to "guesstimate" the number of PUT operations and maximum number of objects for backup offloads.
You can plug these numbers into your public cloud calculator of choice for cost or ensure that your on-premises object store can optimally process the workloads locally.
Formulas
The number of PUTs is directly related to the Veeam Job Storage Optimization settings (“job block size).
For Full:

For Increment:

The "Job block size" (or “Storage optimization”) is defined in the user guide, but to summarize:
| Local target - large blocks | 4096 KB |
| Local target | 1024 KB |
| LAN target | 512 KB |
| WAN target | 256 KB |
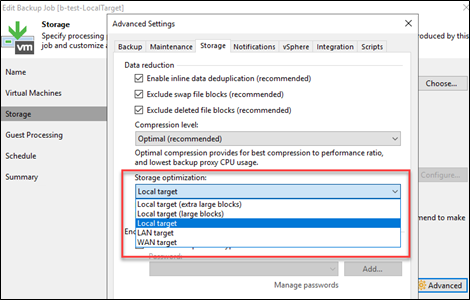
Note: Local Target - extra large (8192KB blocks, see KB4215: Release Information for Veeam Backup & Replication 11a)
The average object size depends on the observed Data Reduction, but a good estimation is to use a 2:1 ratio.

Finally, a count of objects can easily be deducted from the observed or simulated backup size in the performance tier (prior to any capacity tier offloads), and the object average size.

Note: If you use the simulated backup size (https://calculator.veeam.com/vbr), make sure that the ReFS/XFS block cloning option has been selected when running the capacity estimation as offload to Capacity Tier copies only unique data blocks.

Example
We will consider this simple scenario:
- 100TB of source data
- 10% daily change rate
- Default storage optimization setting of “Local Target” (i.e., 1MB job block size)
- Default 2:1 data reduction
- 14 days retention (Forward Incremental) on performance tier and a copy to capacity tier
- Offload window of 8 hours
Let’s first start by calculating the number of PUT operations.
We will express them for both “Month 1” and “Last Month” as expected by most public cloud cost calculators.
PUTs for initial Full = (100 x 1024 x 1024) / 1MB = 104,857,600 PUTs.
PUTs for one Increment = 104,857,600 x 10% = 10,485,760 PUTs.
For “Month 1” we can expect an initial Full and ~29 Increments worth of PUTs.
Month 1 PUTs = 104,857,600 + 29 x 10,485,760 = 408,944,640
For “Last Month” we can expect ~30 Increments worth of PUTs.
Last Month PUTs = 30 x 10,485,760 = 314,572,800
Secondly, if you are considering an "on-premises" object store solution, calculating the actual number of Objects, Objects per second, Data ingest rate and Object size is important.
If you simulate 14 days of backups with block cloning enabled, the (Forward Incremental) backup chain will look like this.

We need to account for “1 Full + 19 Increments” worth of Objects. Our backup size would be:
0.5 x (100TB + 19 x 0.1 x 100TB) = 145TB
Our Object size would be:
0.5 x 1MB = 512KB
The Number of Objects should be:
145TB / 512KB = 304,087,040 objects
Note: You could also just count the amount of PUTs worth of “1 Full + 19 Increments” and arrive to the same number.
The (incremental) Object ingest rate or Objects per Second can be calculated by dividing One Increment’s worth of PUTs by the offload window (expressed in seconds):
10,485,760 PUTs / (8 x 60 x 60) Seconds = 365 Objects/s
Finally, the (incremental) Data ingest rate can be calculated either from the “source data increment” after data reduction divided by the “backup window” or by multiplying the Object per Second by the Object Size:
365 Objects/s x 512KB = 182.5 MB/s
Important Note: On-premises object store vendors will typically work better with larger object size. Be mindful of the impact on your Incremental backup size when adjusting your job storage optimization settings (job block size) to a larger value.
Summary
In summary, understanding how to calculate the number of PUT operations and Objects generated by offload to Veeam Capacity Tier is a critical step towards successfully planning, implementing and integrating object storage with Veeam Backup and Replication.







