This is part two of the blogpost. Part one can be found here: SOBR Archive Tier – Explained and Configured – Part 1 of 4 | Veeam Community Resource Hub
In this part will will discuss the reason behind having different tiers and how they appear within Microsoft Azure.
Hot or Cool? – what’s it all about
S3 storage or blob storage as it is also called is offered by the hyperscalers in various flavors that basically differ in speed of access and the cost charged for the in- or egress of data as well as its storage. We can generally decide between hot, cool and archive for Microsoft Azure. This translates to Standard and Standard-IA (=infrequently accessed) with Amazon AWS. The concept behind is the same. In the following I will stick to the terminology as of Azure.
The capacity tier of the SOBR allows us to leverage either “hot” or “cool” storage tiers from the portfolio the hyperscaler offers. Both tier modes have the same access methodology (API) and the main difference is:
- Hot: Higher storage costs (~2x compared to cool), but lower access and transaction costs, availability: 99.99% (SLA)
- Cool: Lower storage costs, but higher access and transaction costs (~2-5x compared to hot), availability 99.9% (SLA)
A detailed overview for Azure blob storage tiers is given here: Hot, cool, and archive access tiers for blob data - Azure Storage | Microsoft Learn
Azure Pricing can be found here: Azure Storage Blobs Pricing | Microsoft Azure
Hot and cool can be switched back and forth, even with data already inside. Though a cost for the translation my apply. As already said, both can be used for the capacity tier.
So, which of them to use? Actually, from many different customer projects I can summarize: it depends. 😉
Cool is not always cheaper as it has higher costs for the transaction. With a high amount of daily changes (change rate) to your data and frequent backups it might even be, that cool leads you to higher cost than hot. In quite a lot of the cases the resulting monthly cost is even almost the same. So, the higher transaction cost for cool evens out the higher storage cost for hot. You might want to have your own PoC here as your data and workloads decide – milage may vary. Notice that cool also has a 10x lower guaranteed SLA (SLA for Storage Accounts | Microsoft Azure). This might nudge you to hot if the cost is comparable. Also, cool data should rest for at least 30 days to keep the cost low. But this should normally be the case for your capacity tier.
Veeam published a whitepaper in 2020 about cost optimization for the capacity tier for AWS. By just changing the names of the tiers it is more or less also applicable to Azure. The main concepts behind are the same: Designing and Budgeting for AWS Object Storage with Veeam
Now for something completely (?) different - the Archive tier
As with version 11 we can now also use the “archive” (for Azure - “Glacier” for AWS) access tier of Azure. But not within the capacity tier of the SOBR. Another 3rd SOBR tier is introduced. Within VBR this tier is being called “archive tier” relating to the name of the storage access tier within Azure.
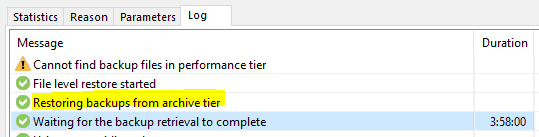
Is the pricing much lower for the date in the archive store? In general, we see the same effect, but to a much higher extent now. Transaction is much more expensive now – especially for egress (restore), but storage waaaay cheaper (~10x compared to cool). If used correctly, we can save a lot of money for the long-term backup storage. Correctly here means, we should not move the data here to early – as we might still need recent backups – and we should keep it for a longer time to justify and compensate the higher cost for the ingress. So e.g., we might want to put it to archive only after 90 days in the capacity tier (hot or cool) and keep it afterwards for at least another 180 days. You might want to keep it even much longer, as the storage cost itself is very inexpensive now. You should only try to avoid to recover from it, as this will be quite expensive. Quite the right option for the long-term storage for those hopefully rare disaster recovery events. 🤞
How to get data into the archive tier
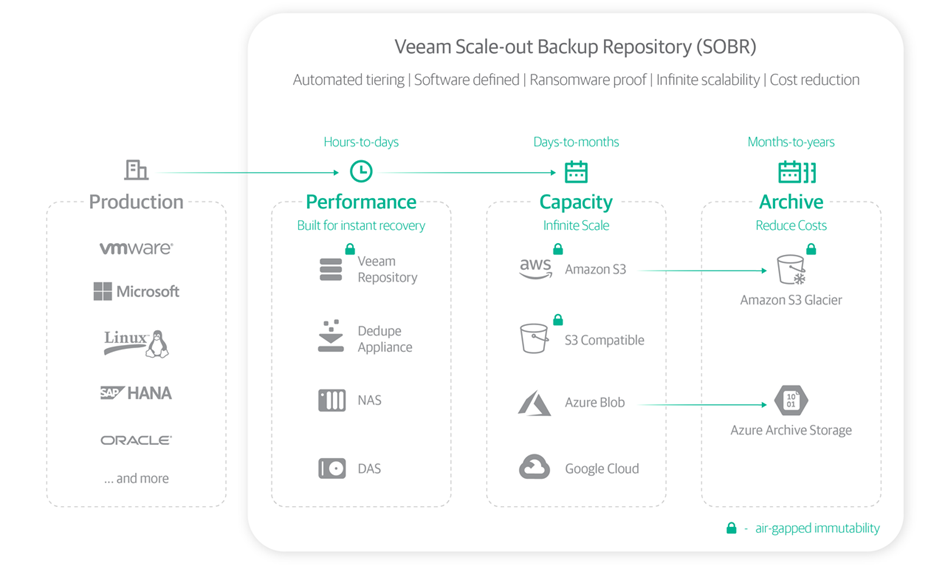
As stated, the hot and cool tiers use the same API for ingesting data. But the archive tier is different. It cannot be directly addressed from your on-premises Veeam installation. It rather needs the help of compute inside the hyperscalers stack. Fortunately, appliances (VMs) are automatically deployed by your Veeam SOBR off-loading process when needed. After the move from hot/cold to archive, those appliances immediately get removed again. The compute consumed by them, will also add to the ingress cost of course. This leads us to the general rule that you have to use the archive tier with the same hyperscaler your hot/cool tiers for the capacity tier of the SOBR are located. See the schematic diagram for an overview of tiers and data paths available.
This concludes the second post of the series about the archive tier. Stay tuned for the following ones in which I will show how to configure the archive tier in detail on the hyperscaler side and within VBR. 😎