Hello Veeam Community,
I want to share a recent experience I encountered with the Linux-based Veeam Backup Appliance (used via plug-in to protect GCP workloads).
This is part of our growing environment where we use Veeam Backup for Google Cloud.
Issue Summary:
Yesterday, I ran into a serious issue where the backup appliance became unresponsive. Here’s what happened:
Problem Description:
- Appliance DB disk was full this caused log files to pile up.
- Logs were not auto-deleting, consuming critical DB disk storage space.
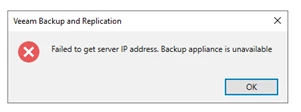
- The appliance showed the following errors below:
- "Failed to get server IP address"
- "Backup Appliance is unavailable"
The Veeam plug-in was unable to communicate with the appliance, and no backups could proceed at that point.


Root Cause:
- The database disk inside the appliance reached full capacity. ( Above Screenshot )
- Logs under the appliance’s backup storage directory were accumulating over time.
- The appliance could not boot its services properly due to no free space, which led to connection and IP assignment issues.
Resolution Steps:
1: Restored the appliance using a snapshot:
- Luckily, I had already configured daily snapshots from GCP host-level.
- Using GCP's snapshot restore feature, I quickly recovered the appliance to the last healthy state.
- This reinforces the importance of snapshot scheduling.
2: SSH into the restored appliance and manually cleaned up the logs
Run this command to safely remove old compressed log files:
- find /mnt/vcb-storage -name "*.zip" -type f -delete
This helped free up the disk and allowed the appliance to stabilize after restoration.
✅ Best Practices (Based on My Experience)
Enable Daily Snapshots from GCP Console:
- These are your first line of defense for recovery treat them like restore points.
- Snapshot scheduling ensures a fast rollback in case of internal appliance issues.
Monitor DB Disk Usage Regularly:
- Especially for appliances storing logs locally — check /mnt/vcb-storage or configure alerts.
Automate Log Cleanup:
- If auto-log rotation is not working, plan for manual cleanups using cron jobs or custom scripts. ( find /mnt/vcb-storage -name "*.zip" -type f -delete )
Secure SSH Access:
- Always ensure only authorized access can reach your appliance over SSH for such operations.
Document Recovery Steps:
- Keep a runbook or SOP with your cloud and backup team for quick restoration.
Final Thoughts:
The Linux-based Veeam appliance for GCP is a great tool but like any backup solution, it needs regular monitoring and hygiene. With proper snapshot policies, disk usage alerts, and log management, you can avoid surprises and ensure a smooth backup and recovery lifecycle.
I'm happy to be a part of this community and share this hands-on learning. I hope it helps others who might face similar issues.