
Importantly, administrators are responsible for enabling and configuring the fencing mechanism after cluster deployment. Without the fencing configuration, node remediation and VM restarts will not happen as expected.

In virtualized environments, high availability (HA) is essential to keep workloads running even when a node fails. In OpenShift Virtualization, HA leverages Kubernetes-native mechanisms combined with OpenShift’s self-healing infrastructure.
A key element is fencing, the process of isolating a failed node to prevent issues like split-brain—a scenario where nodes lose communication but continue running independently, causing data inconsistencies and conflicts.
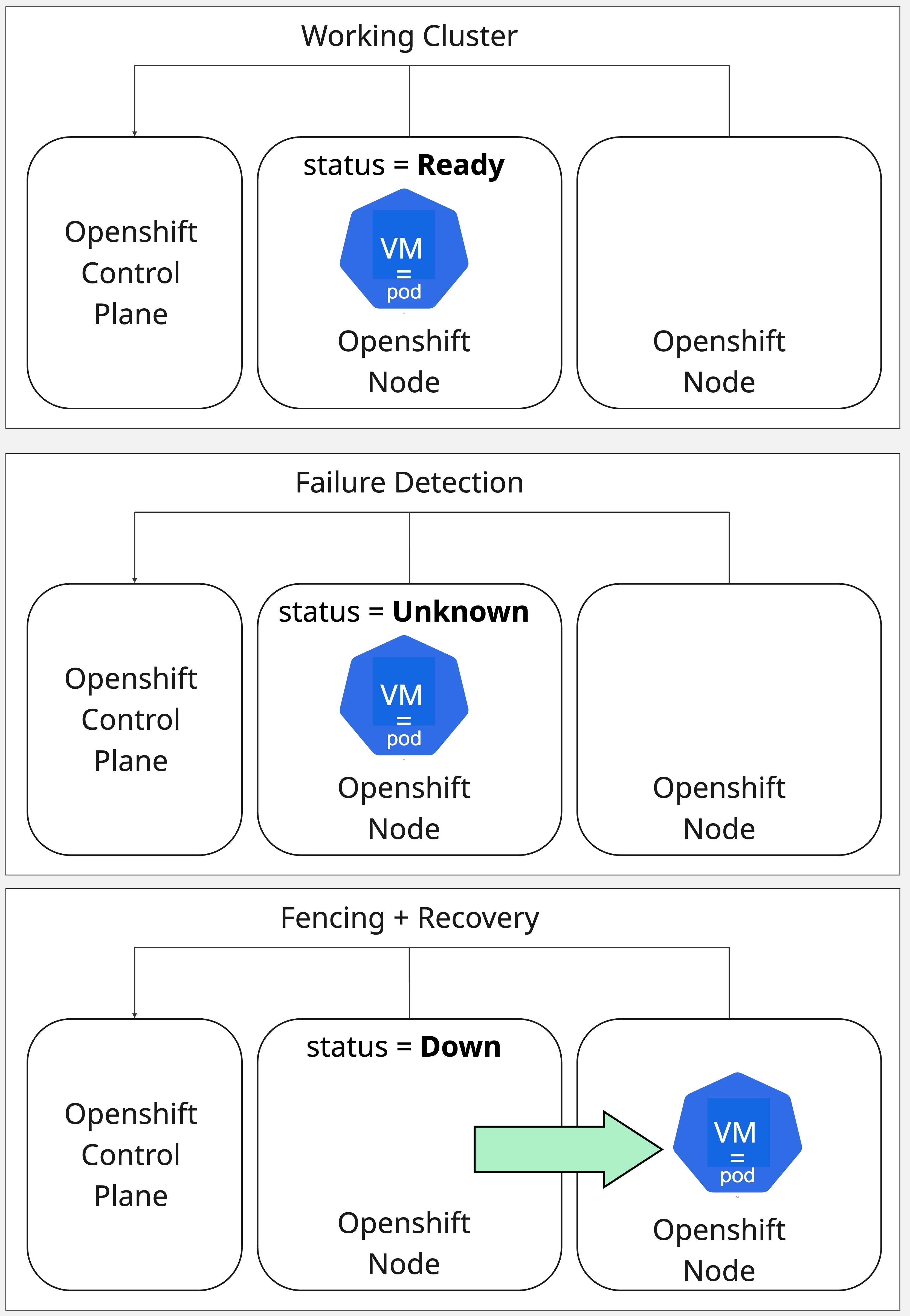
When a node goes down, restarting virtual machines (VMs) happens in three phases:
-
Failure detection – Identifying that a node has stopped responding.
-
Fencing – Ensuring the failed node is safely isolated with no active workloads.
-
Remediation – Restarting affected VMs on a healthy node.
Through this approach, OpenShift Virtualization ensures service continuity while protecting both data integrity and workload availability
In OpenShift, failure detection is handled through Node Health Check (NHC) or Machine Health Check (MHC).
-
NHC: works at the node level, monitoring conditions and triggering direct remediation (e.g., local reboot). Best for manually managed nodes or environments outside OpenShift automation.
-
MHC: integrates with the Machine API, monitoring both the node and its Machine object. When unhealthy, it deletes and reprovisions the Machine. Suited for automated environments like cloud or bare metal IPI.
Choosing between NHC and MHC depends on the cluster’s infrastructure type and automation capabilities.
High availability in OpenShift Virtualization relies on combining failure detection, fencing, and remediation.
There are three main strategies:
-
Self Node Remediation (SNR): the node reboots itself using watchdogs, without external hardware.
-
Fence Agents Remediation (FAR): leverages management interfaces (IPMI, iDRAC, iLO, Redfish) to power-cycle failed nodes reliably.
-
Machine Deletion Remediation (MDR): deletes and reprovisions the node via the Machine API, suited for cloud and IPI bare metal.
Often an escalating approach is applied: start with FAR (fastest), then SNR, and finally MDR if needed.
Each option has trade-offs, but together they ensure minimal VM downtime and protect workload integrity.
Ultimately, ensuring VM availability in OpenShift isn’t just about running a cluster—it’s about building a comprehensive strategy that combines monitoring, fencing, and recovery. With the right tools, downtime can be minimized, and workloads can continue to run seamlessly. The real strength of OpenShift Virtualization lies in its ability to adapt to different environments while delivering enterprise-grade resilience.
