
When Veeam Recovery Orchestrator (VRO for short) is used, it is usually an infrastructure with a VDP Premium license. Alternatively, the use of VDP Advanced and additional 10 instance packs for the Orchestrator would also be possible.
In the Orchestrator itself, there are various ways to map recovery plans.
In this article, I would like to show a way to first shut down the productive workloads when using replication jobs, transfer the delta data to the DR-site and then boot it up there. This corresponds to a native planned failover within Veeam Backup & Replication (with more options and reporting functionalities).
Replication Jobs in VBR
In my lab, I work with various VMware vSphere tags, which map SLAs here (Gold, Silver, Bronze). My replication jobs within VBR are named in a similar scheme.
Replication Jobs:
REP_vSphere_Site A_RP_Gold
REP_vSphere_Site A_RP_Silver
REP_vSphere_Site A_RP_Bronze

Within the respective replication jobs, my resources to be backed up are also selected via tags:
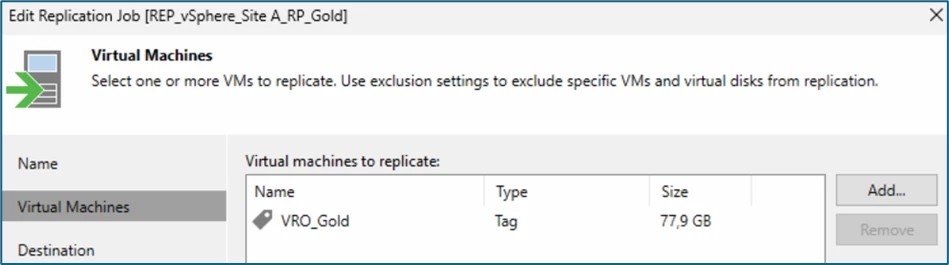
In this configuration, the jobs are scheduled once a day (06:00 a.m.), which corresponds to an RPO of 24 hours.
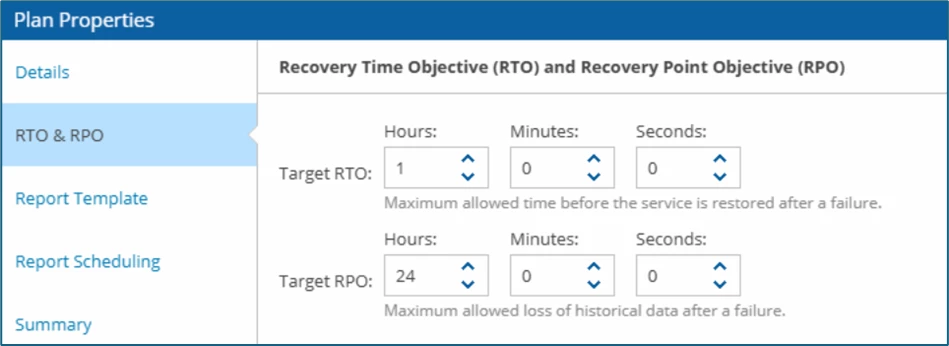
VRO - Recovery Plans

The recovery plan itself is defined with an RPO of 24 hours and an RTO of 1 hour.
Within a regular recovery plan, no Pre-plan steps are defined by default, see here:
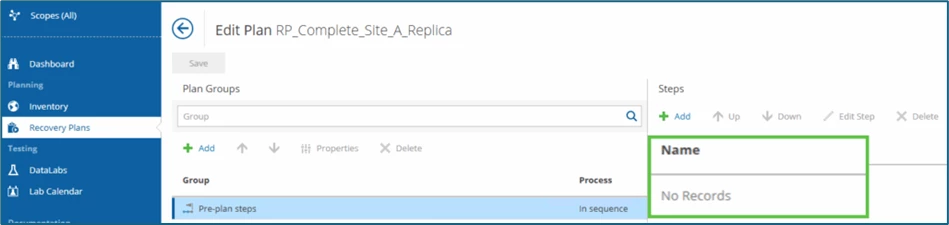
That's exactly what we want to change now and add a planned failover function! Within the Pre-plan steps group, we select the Veeam Job Actions and VM Power Actions functions via Add.
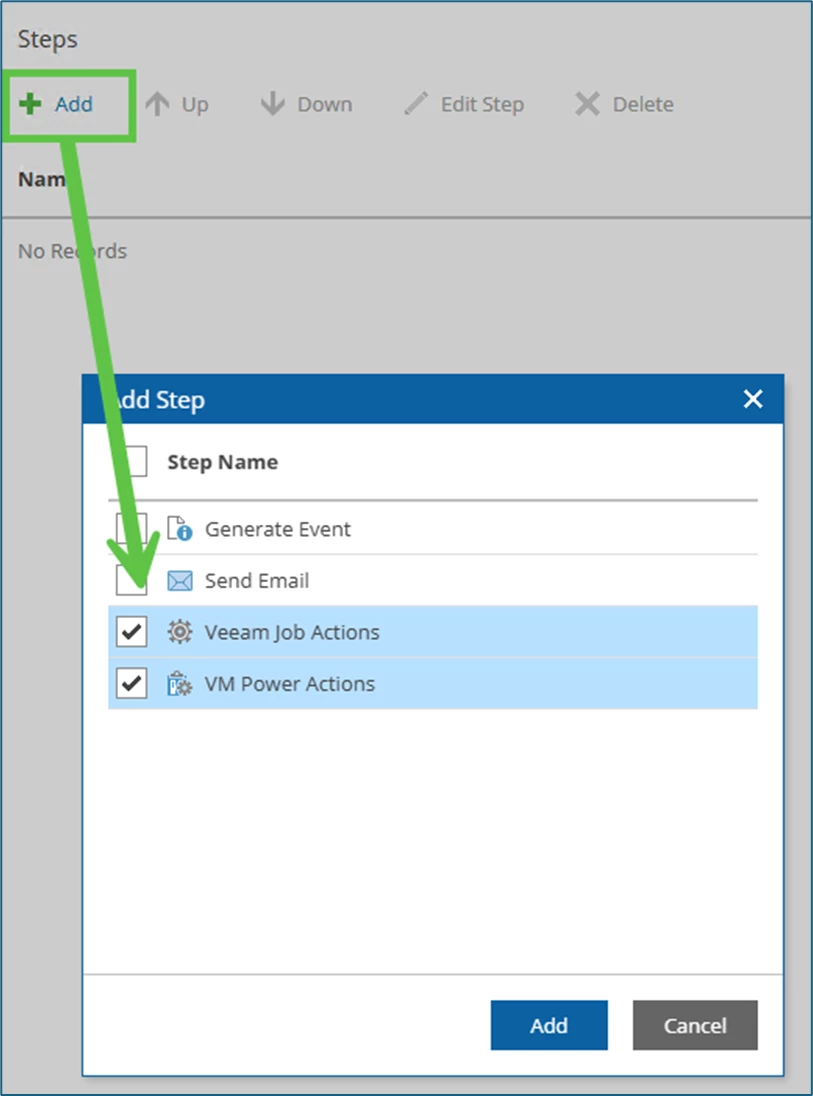
Then VM power Actions is selected and adjusted via Edit Step:
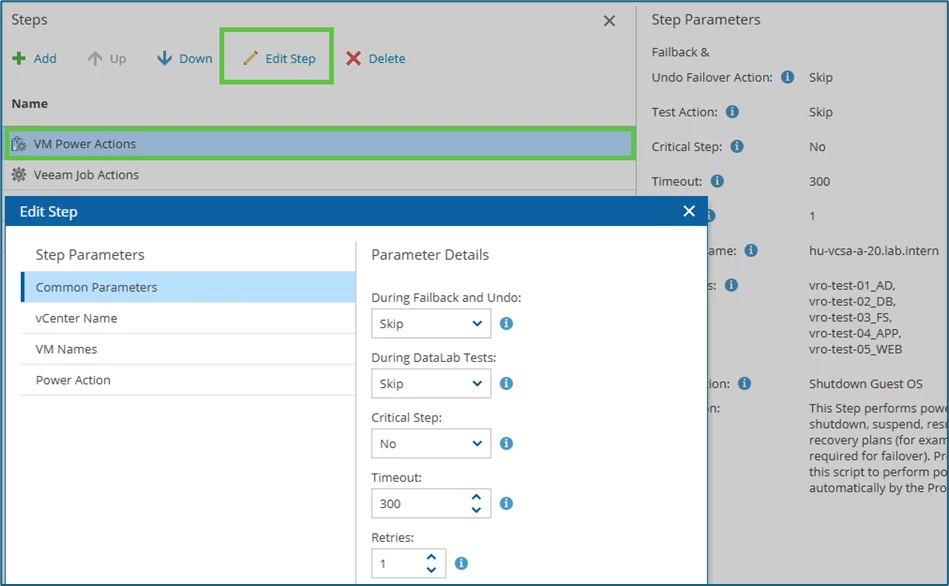
For During Failback and Undo please select Skip!
Important: in this scenario, the option Skip must be selected under During DataLab Tests! Otherwise, testing the isolated recovery plan would shut down the productive workloads.
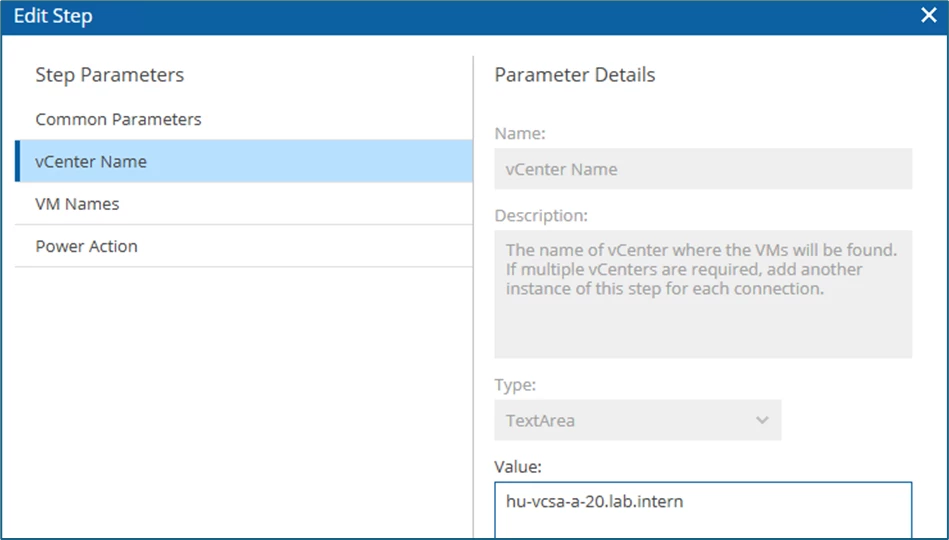
In the field vCenter Name the FQDN of the source site is stored, in my lab this would be vCenter hu-vcsa-a-20.lab.intern.
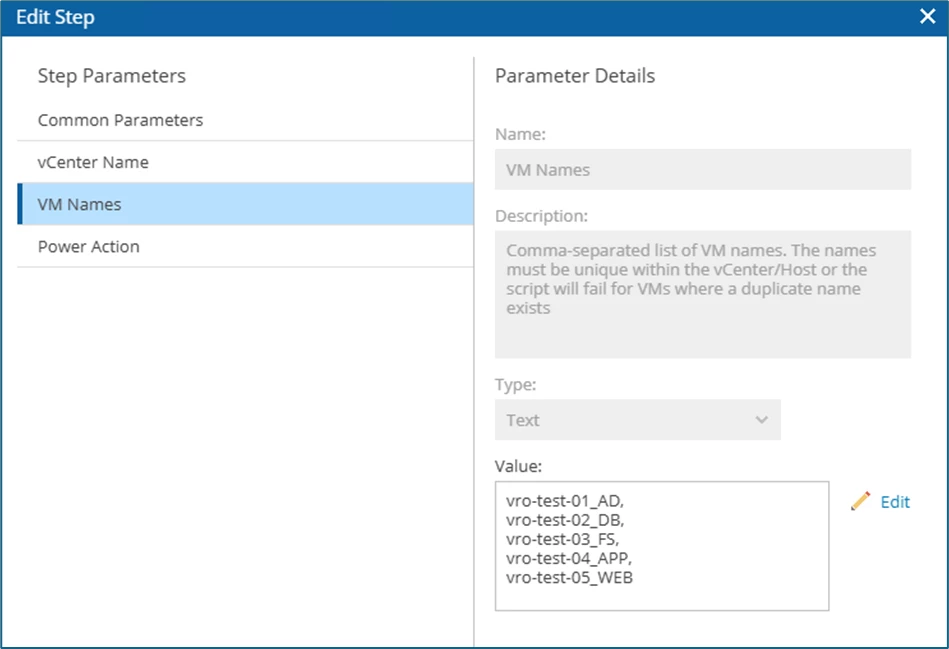
Under VM Names, enter the VMs to be processed. Note: I have not yet been successful with the existing variables, this is still on my list that needs to be clarified. It would be nice, if you can work with a variable something like %all-VMs-who-are-processed-in-this-whole-recovery-plan% Maybe
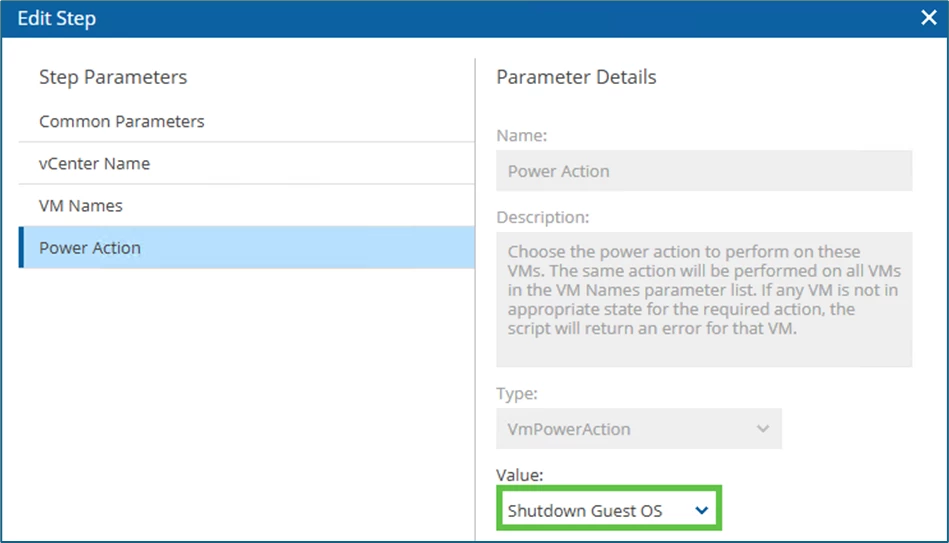
Under Power Action, the value Shutdown Guest OS is selected.
Save with Apply and then edit the Veeam Job Actions step:
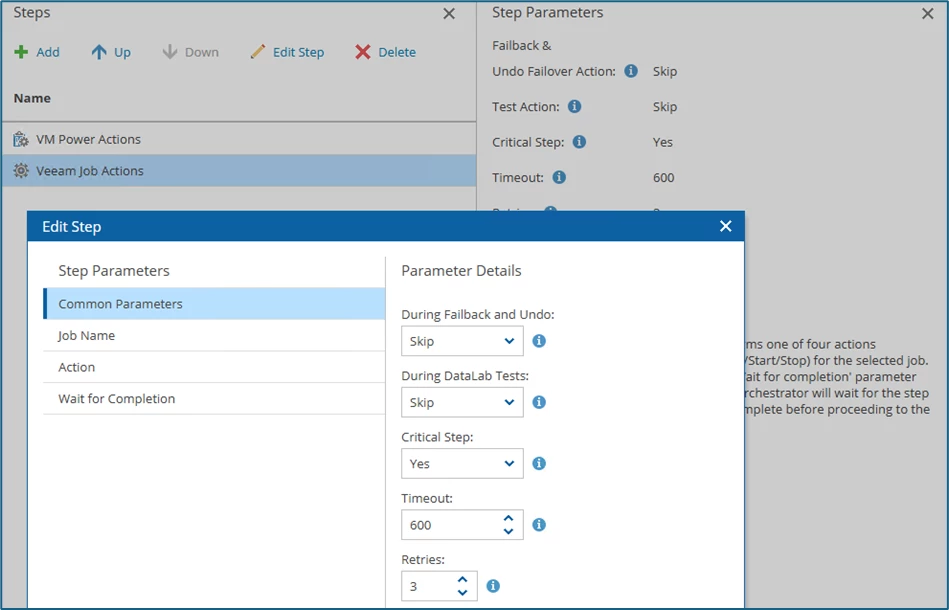
Again, I choose Skip during the DataLab test. Because I don't want to start a replication during the isolated recovery plan test.
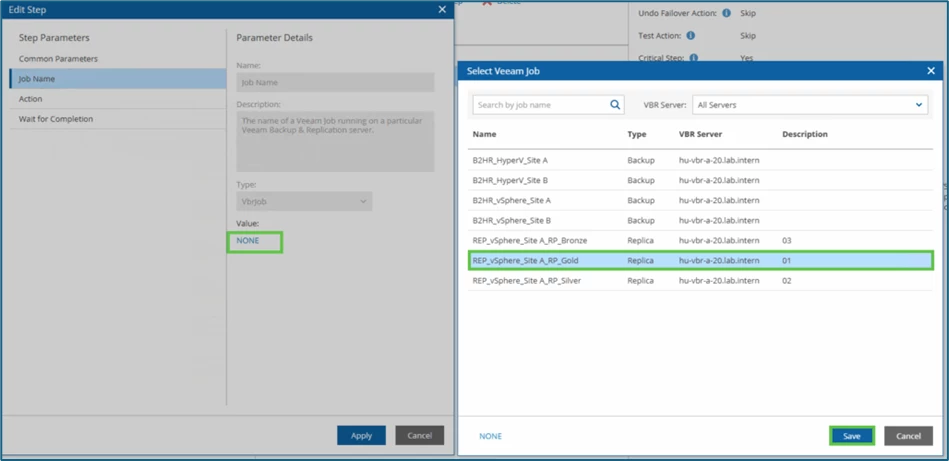
Under Job Name, I now select the respective replication jobs - You must do this step again for each individual replication job. Here is an example of the job REP_vSphere_Site A_RP_Gold.
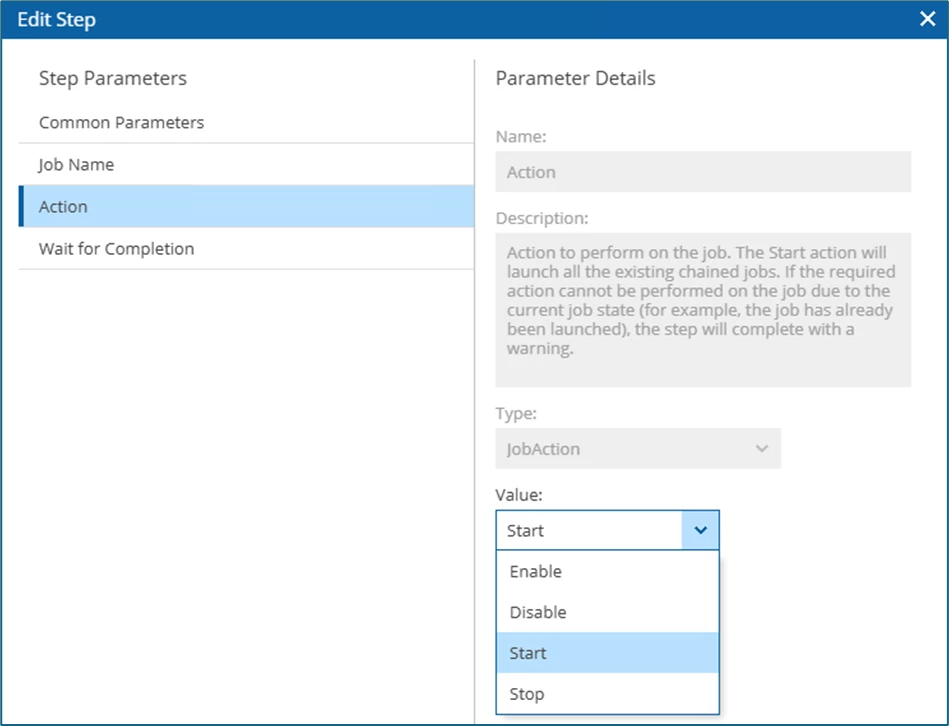
In the Action field, the value Start has to be selected.
Confirm the default value Yes in the Wait for Completion field and save the option with Apply. Because you don't want to start the actual failover until the replication is complete.
In my scenario I have three replication jobs (see above), so in the end the whole thing looks like this:
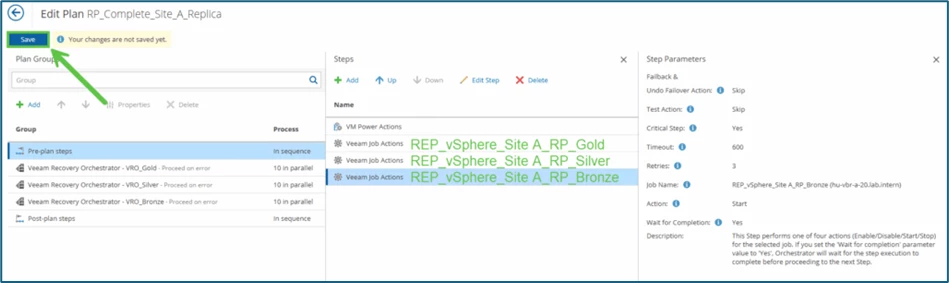
So I selected 3 x Veeam Job Actions and stored the respective Replication Tasks. The adjusted plan is saved via Save.
Planned Failover
Now it's time to start the planned failover.
Starting point:
- last replication this morning at 06:00

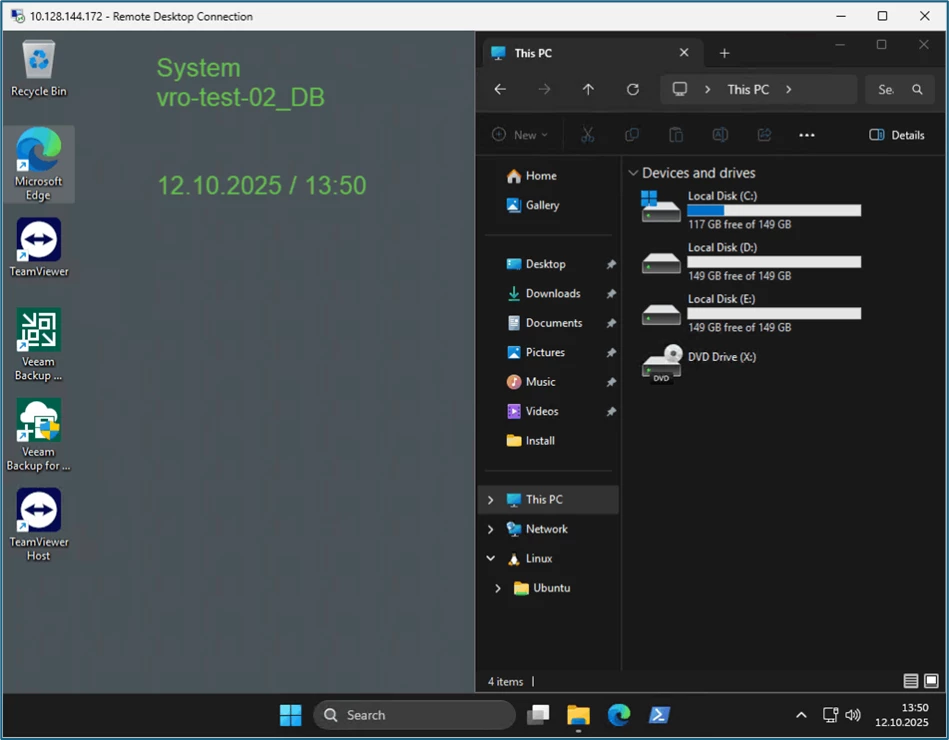
| System vro-test-01_AD | System vro-test-02_DB |
|---|---|
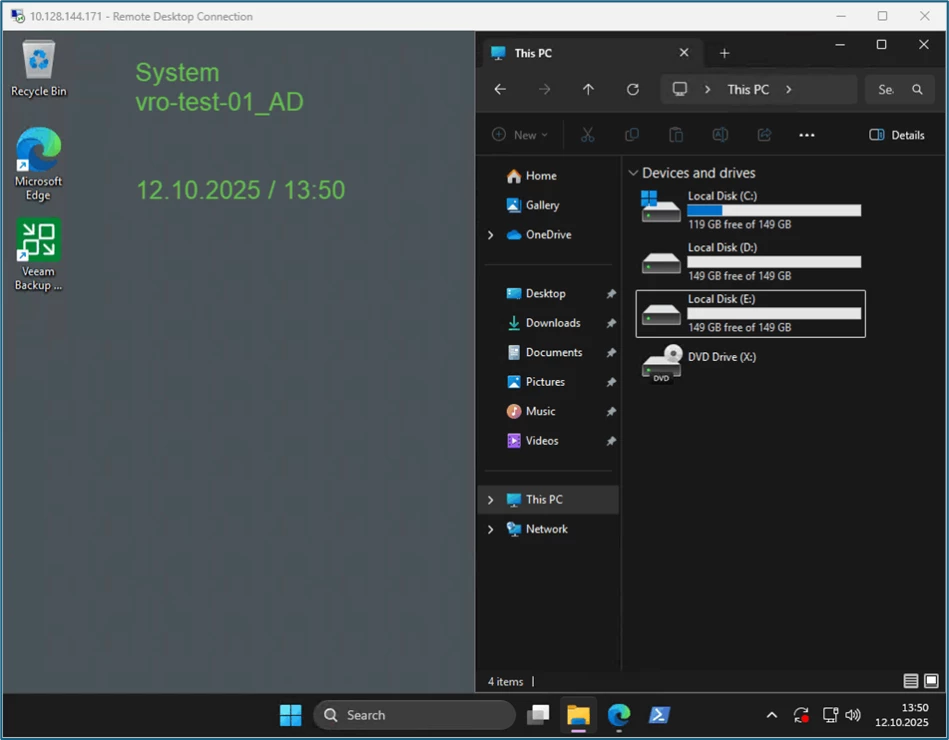
| 
|
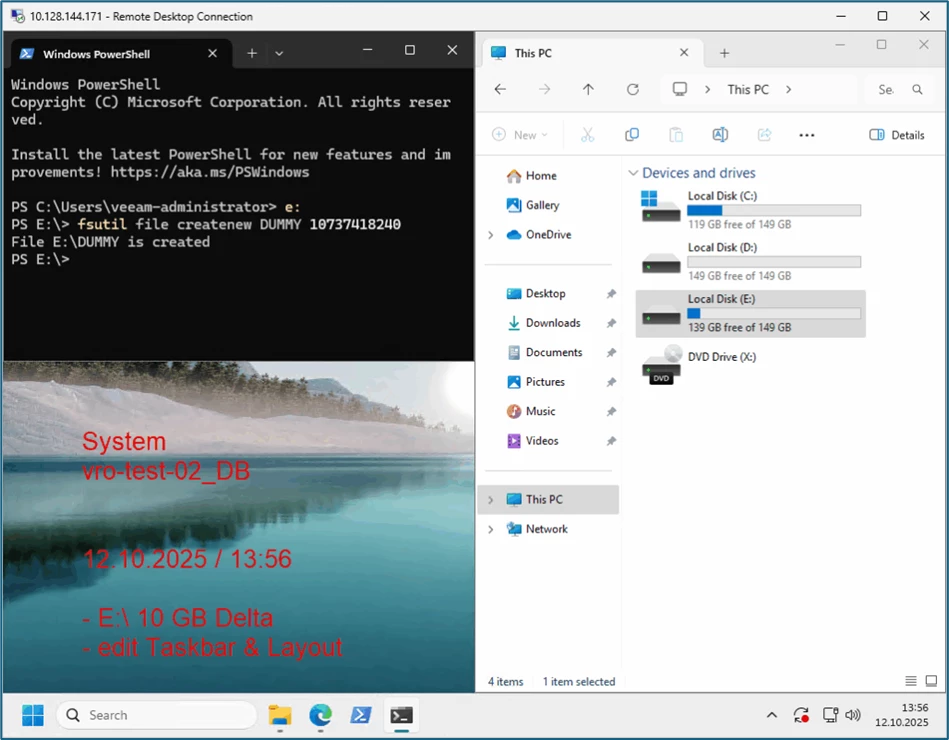
I'm generating changes and delta data on both systems:
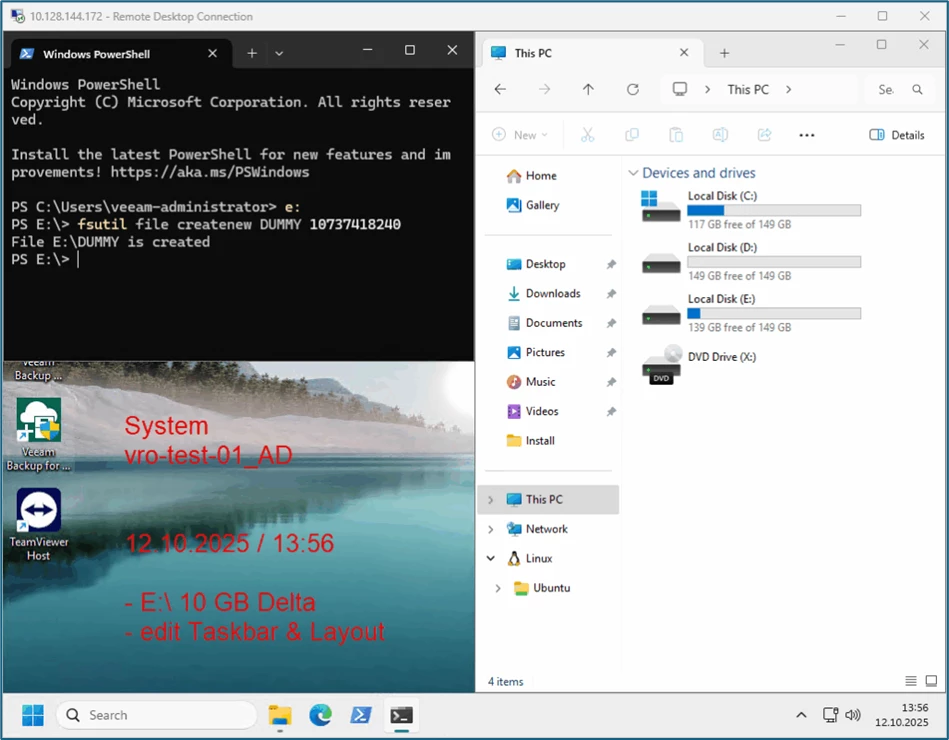
| 
|
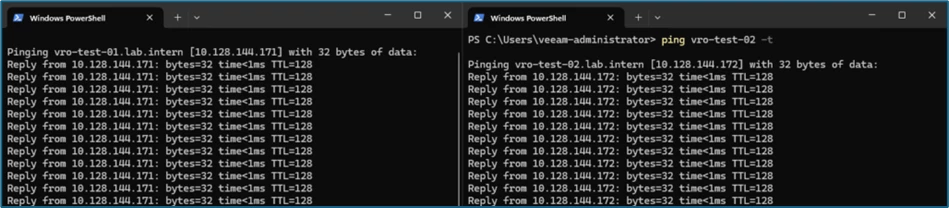
The systems are slightly modified and are still online.
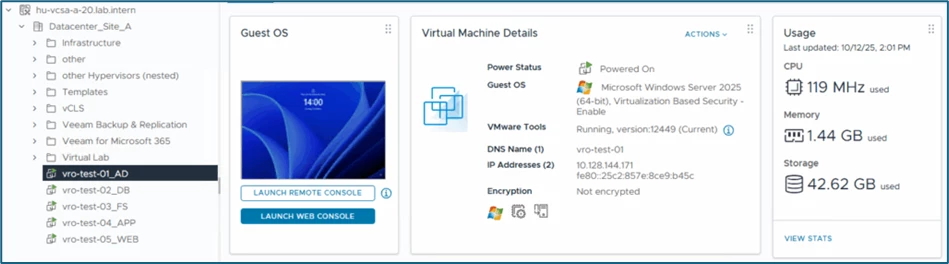
View of the productive Site A in the vCenter:
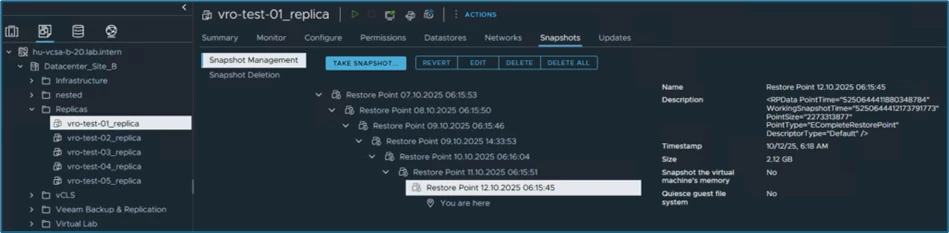
On the DR-site the systems are still off, last restore point from this morning 06:15 a.m.:
Recovery Plan in VRO
I now start the recovery plan, via launch and run:

The plan must be activated via Enable this Plan:
To execute, the credentials must be confirmed again:
The last readiness check is displayed with status:
We select the last existing restore point (default):
Subsequent summary and via finish the operation is started.
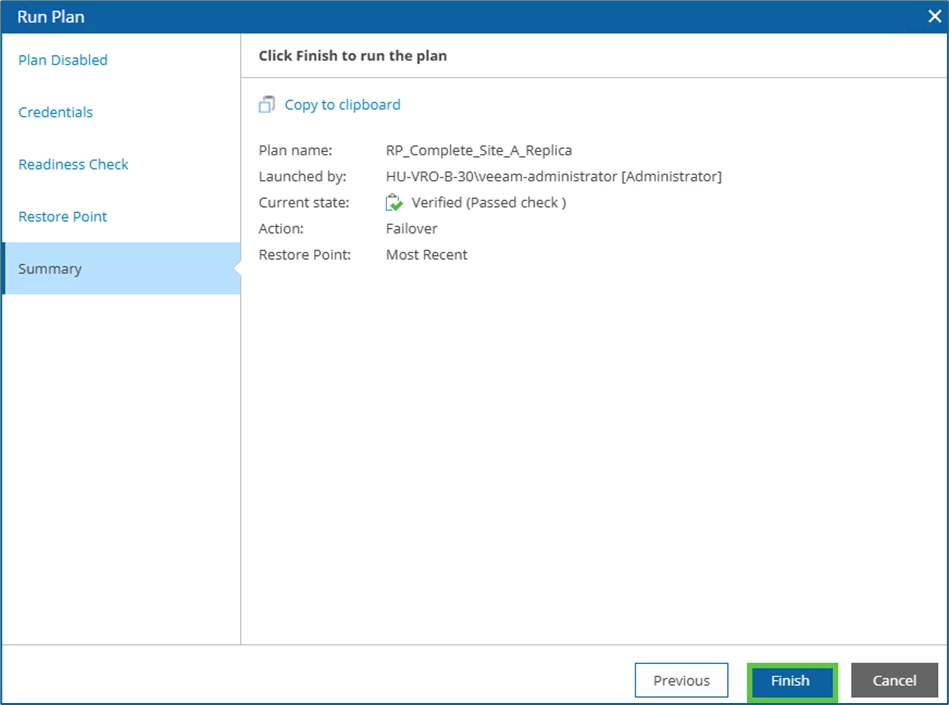
Shutdown / Replication / Startup / Check
The systems are now shut down immediately via the Orchestrator:
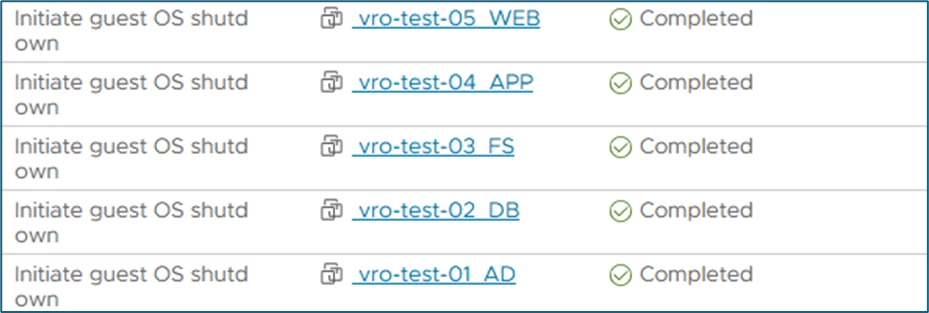
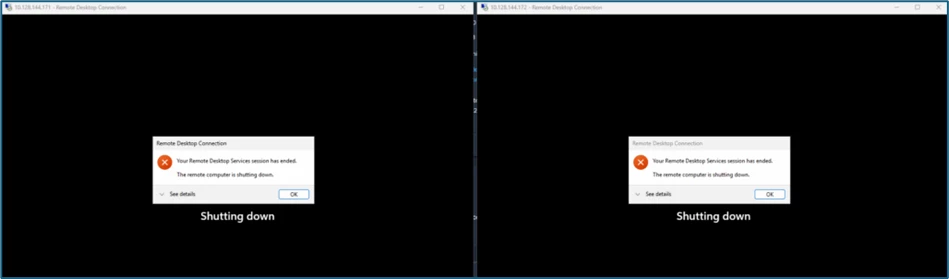
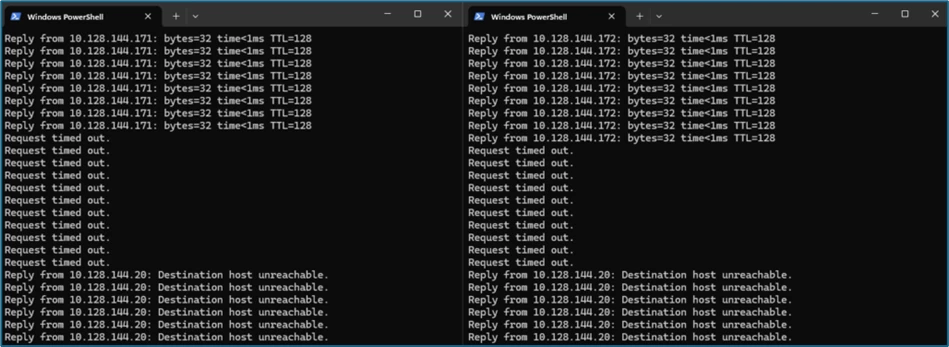
Then the replication jobs start in VBR:
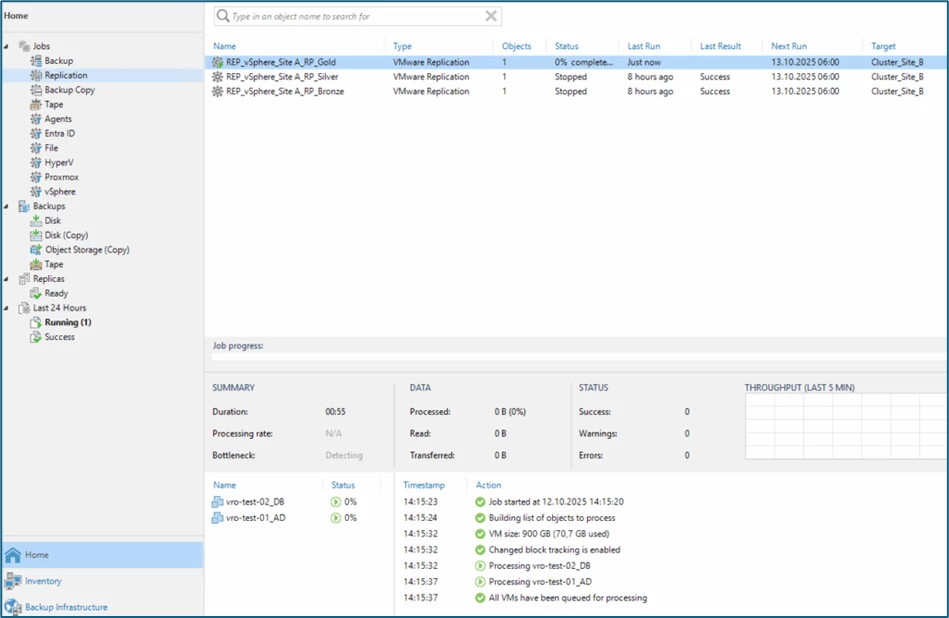
Within VRO, the whole thing looks like this:
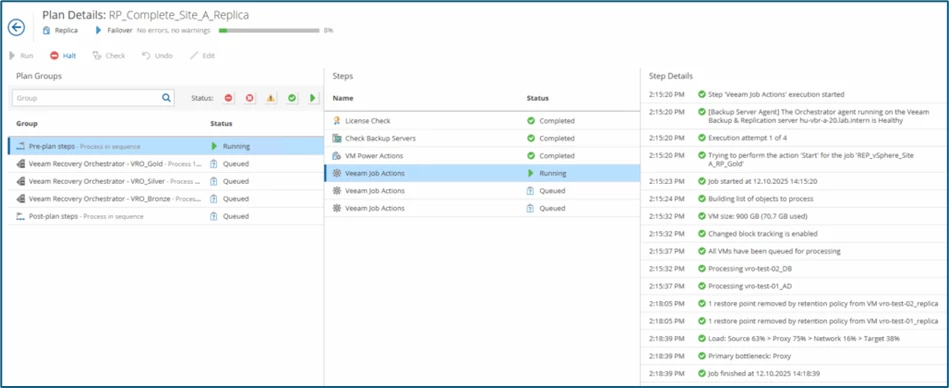
The actions are carried out step-by-step, and the first replication job has now been completed within VBR. On these screenshots, the Silver Plan is now processed:
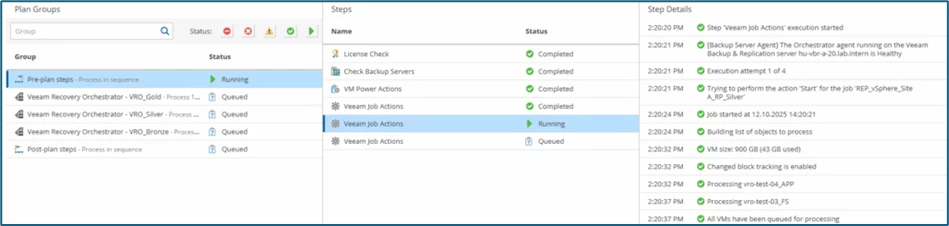

Once replications are complete, the replica systems on the DR-site are booted up. Status within VBR, the first systems are in the failover status:
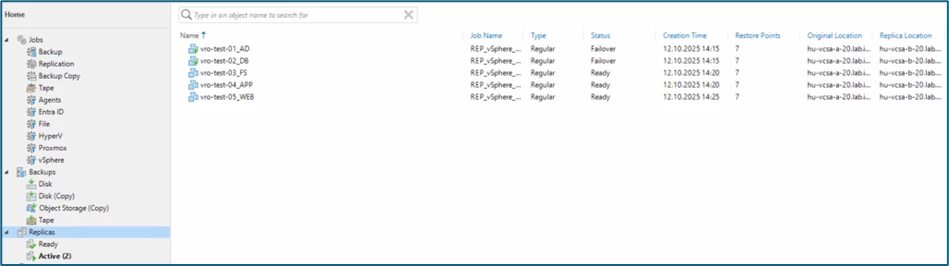
And in the plan details in the Veeam Recovery Orchestrator, it looks like this:
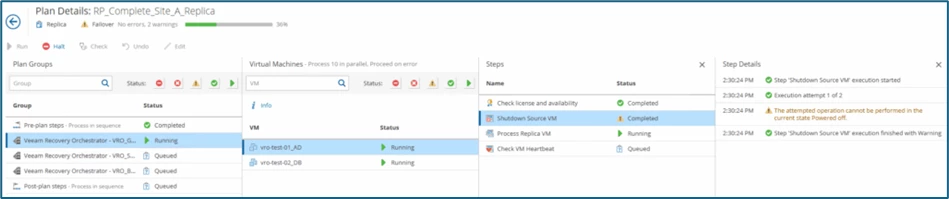
The warning that the source is down is normal in this scenario. Without our planned failover (shutdown, delta sync), the orchestrator would still have shut down the systems. If the site is still accessible / available (just without delta sync)...
In vSphere on the DR-site, the replicated systems can also be seen as started:
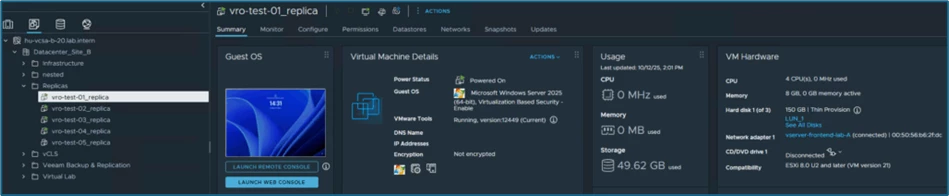
All systems are now accessible again, just hosted on the DR-site.
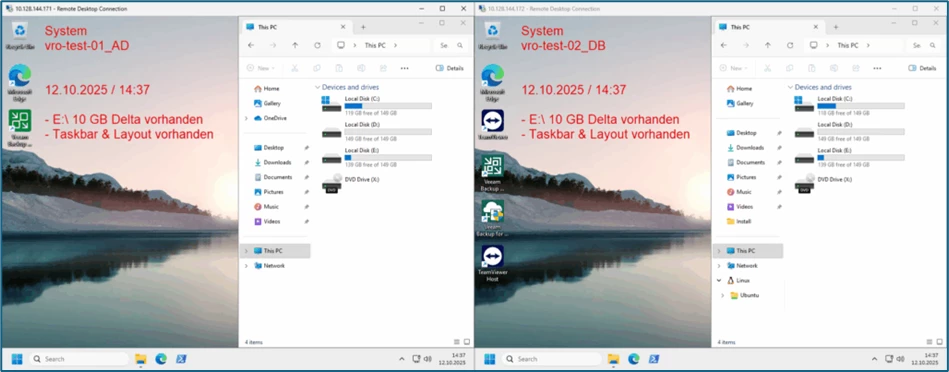
The check for existing delta data shows that it has been transferred correctly. 10 GB of delta data, as well as the layout corresponds to the adjustments from the source.
Within the Orchestrator, the plan has been run through, as mentioned above, the warnings refer to the systems that have already been powered off:
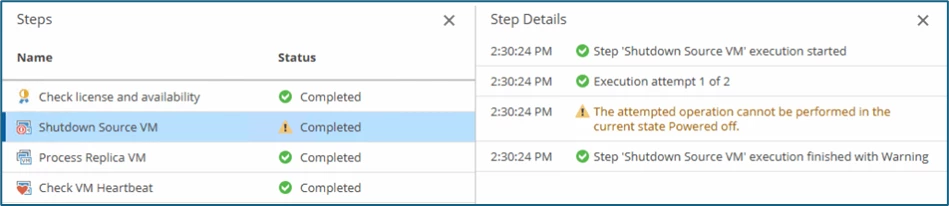
Identical to a planned failover (in VBR), the operation is not yet completed, our systems are functional on the DR-site, but the process still must be finalized in VRO (via Continue or Undo).
Continue
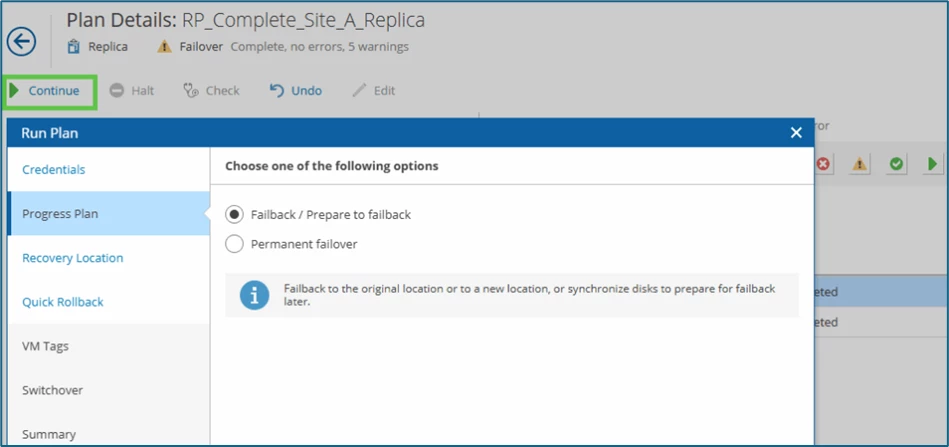
Here, we must distinguish between a permanent takeover by the DR-site as the new primary location (Permanent Failover) or, if the productive site is available again, transferring newly generated delta data from the DR-site back to the source/productive site (Failback).
The Permanent Failover option should be selected if the source site is irretrievably lost (a permanent loss of location). Thus, the replicas in the DR-site would become the final primary system.
Via Failback / Prepare to failback option, the generated delta data from the DR-site is migrated or transferred to the existing production site during the failover.
Note: this scenario shown could correspond to a temporary shutdown of the production site (e.g. a prolonged power interruption) - usually the second / DR-site is then put into production. After the source is available again, you want to switch back to the original site and transfer the data generated in the meantime. Thus, in this example, the choice would be to choose Failback!
I have also made changes for the failback scenario on the DR-site - to show that these are also adopted:
In this example, Original VM Location can be selected as the recovery location.
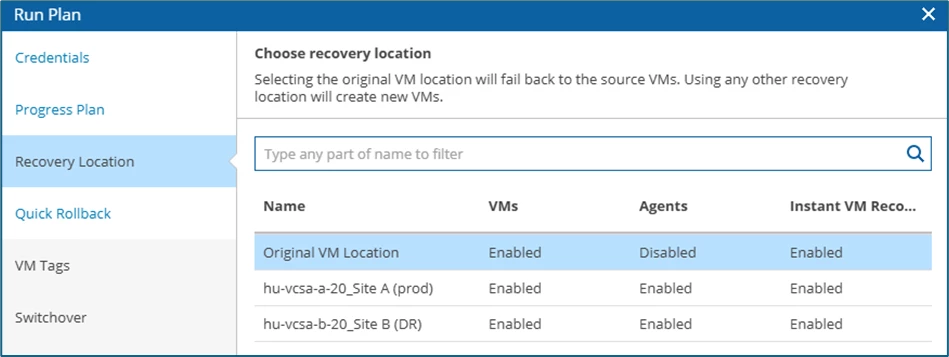
I selected the Quick Rollback function because my scenario was not preceded by a hardware failure or power failure, so I save a bit of time.
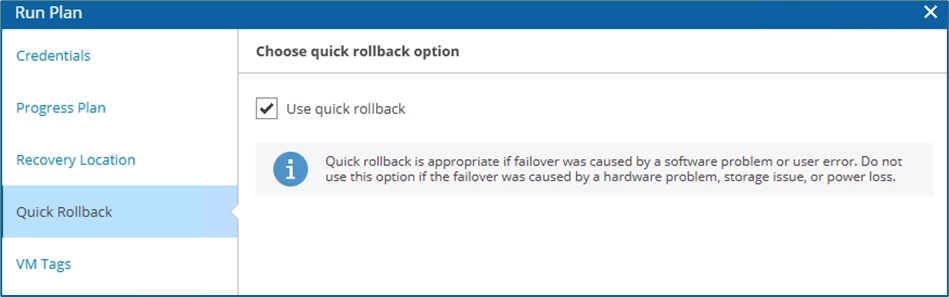
I leave the remaining settings, i.e. VM Tags and Switchover (here Failback now or Prepare for failback) at their Defaults and get an overview of the selected actions.
The process is then started with Finish.
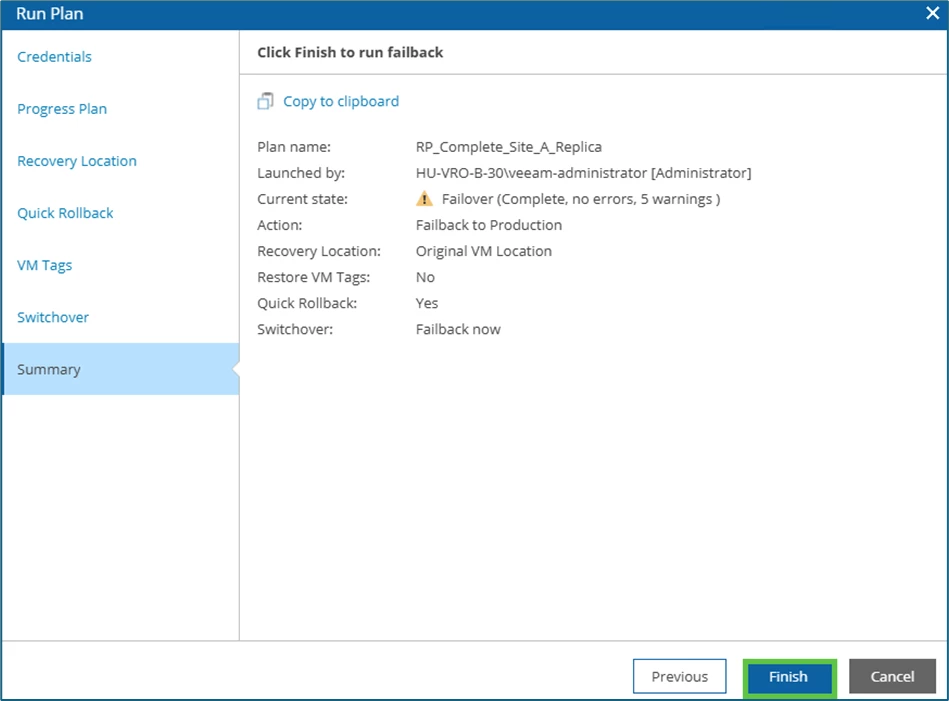
Failback in detail
As soon as the failback process is started, you can see the respective steps in the Orchestrator within the plan details.
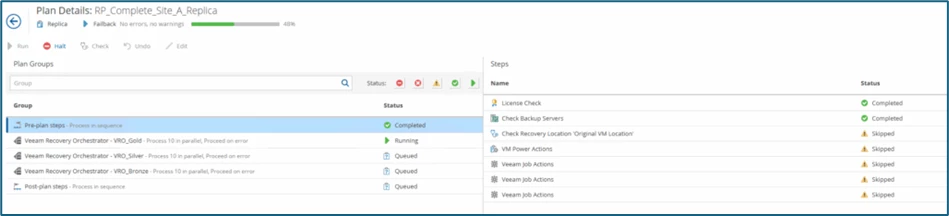
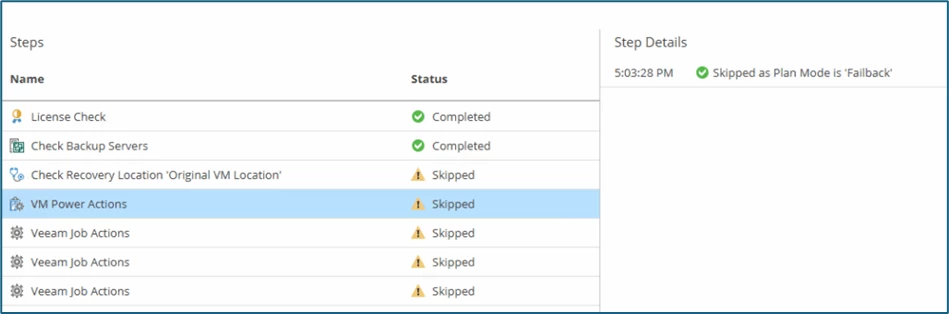
Since the Original VM Location option was selected as the destination, a skipped status (with yellow exclamation marks) is also logged during the check - which is normal.
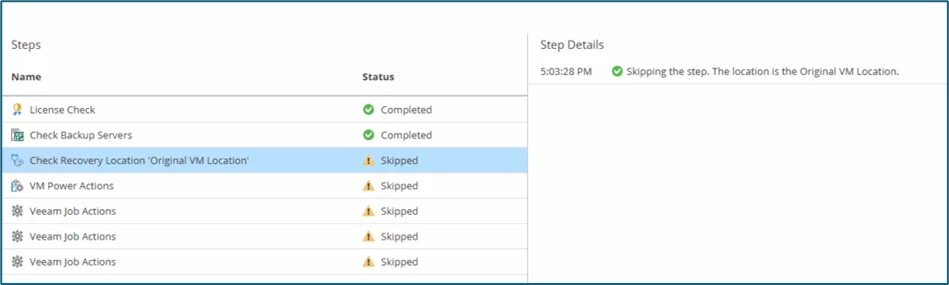
The same applies to the Steps VM Power Actions and Veeam Job Actions, as they were set to Skip in the Recovery Plan:

Within Veeam Backup & Replication, the operation can also be viewed under Running Task as a Restore Session (of the type Failback).
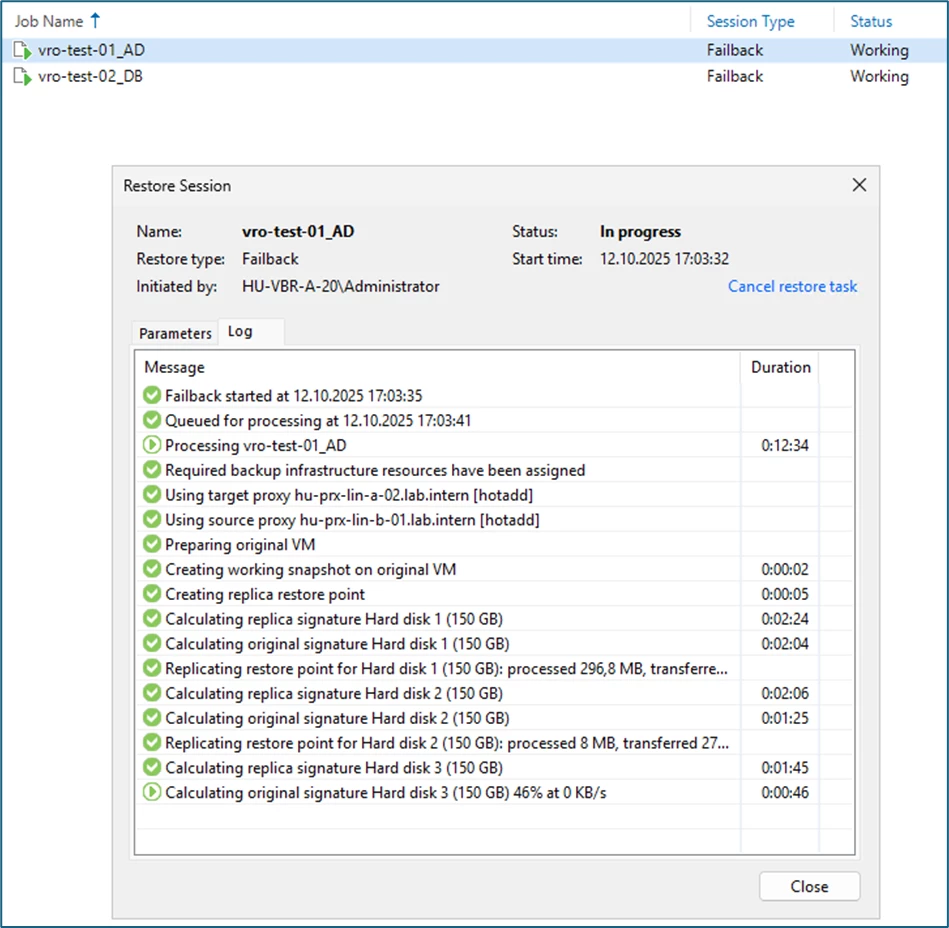
During this step, the systems are still running on the DR-site:

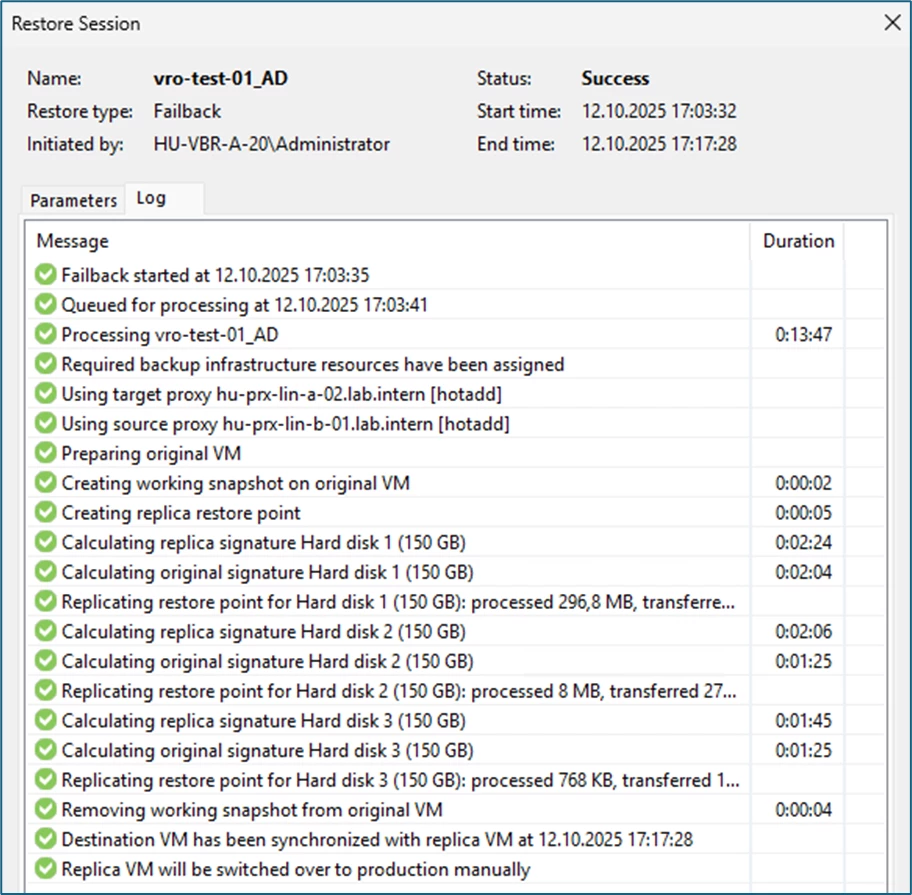
Once the calculation of the original and replica signatures is complete, the replica systems on the DR-site are shut down and the delta data is replicated.
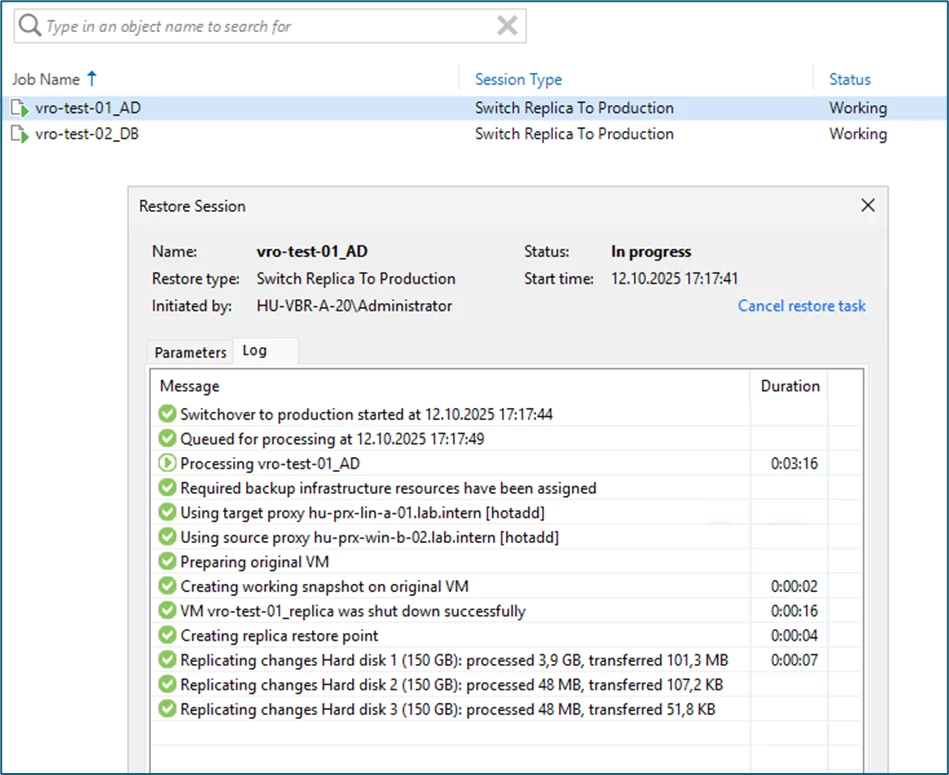
As you can see in the screenshots, the first system is already complete and back online on the original production site, the second system is still being processed:
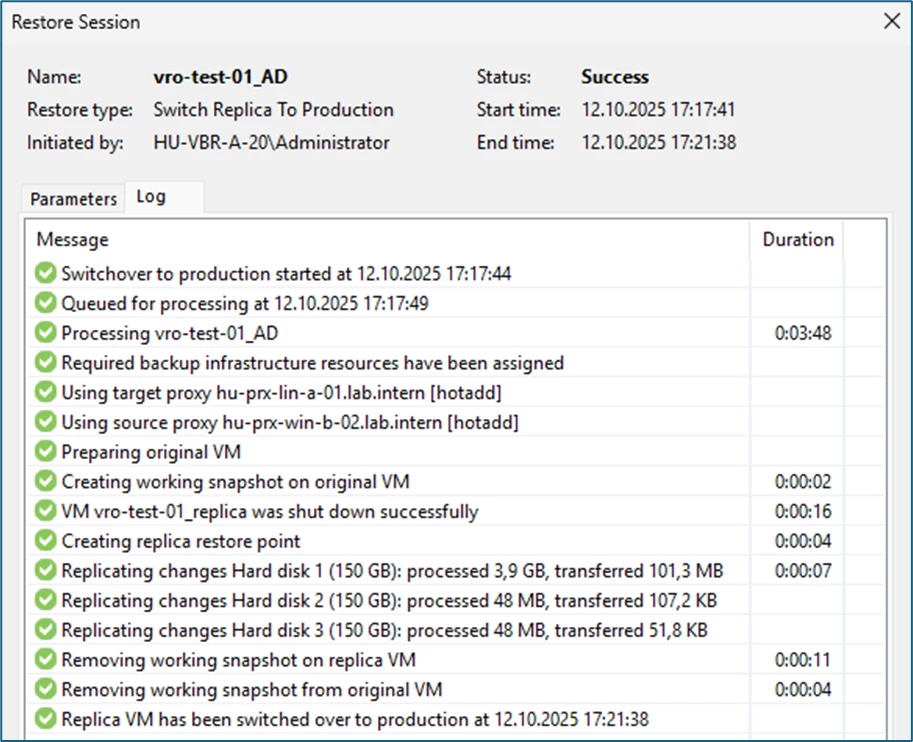

The respective steps can also be traced in detail in the Orchestrator:
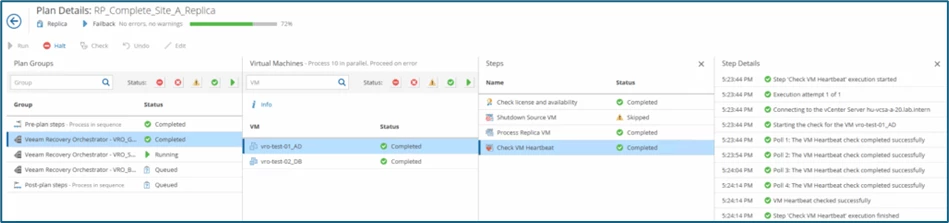
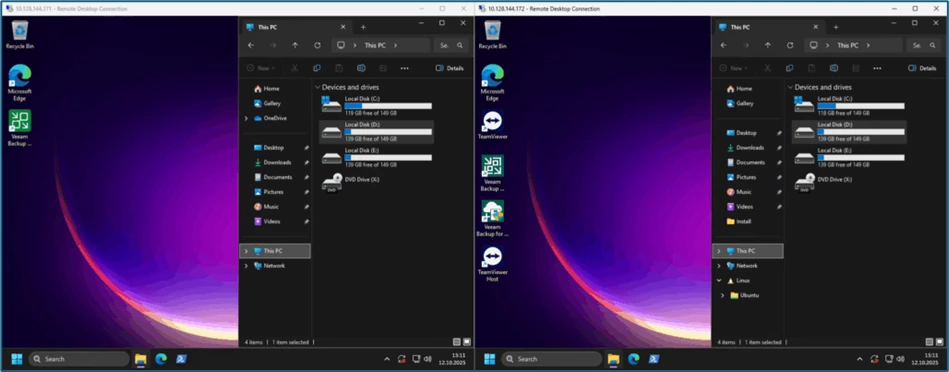
In the meantime, the first two systems from the Gold Level have already been completed, a quick look via RDP shows that the changes and delta data generated on the DR-site are also available:
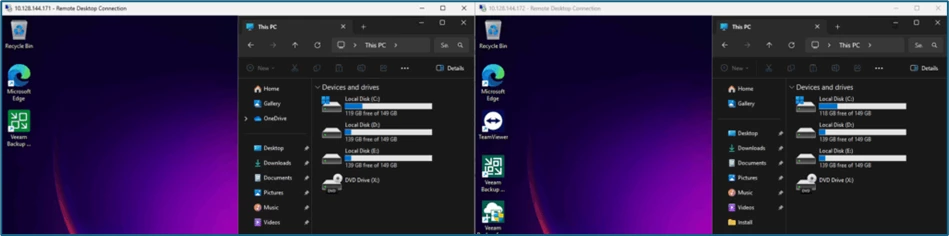
When all steps are completed, we can select Continue, enter our Credentials…
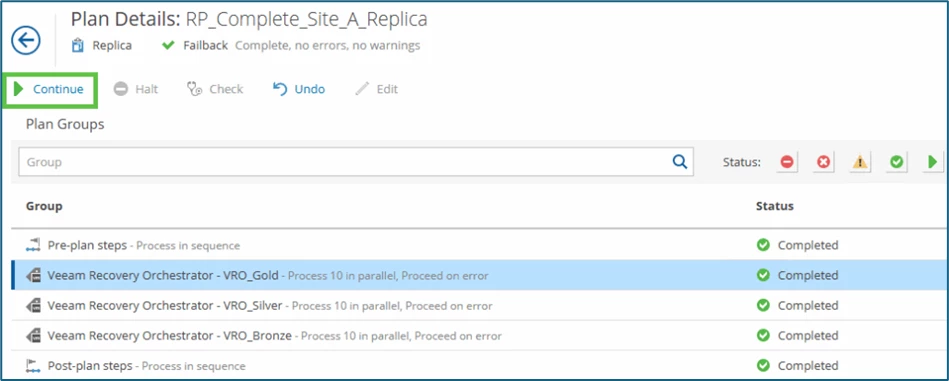
... and click Finish to confirm and complete the operation.
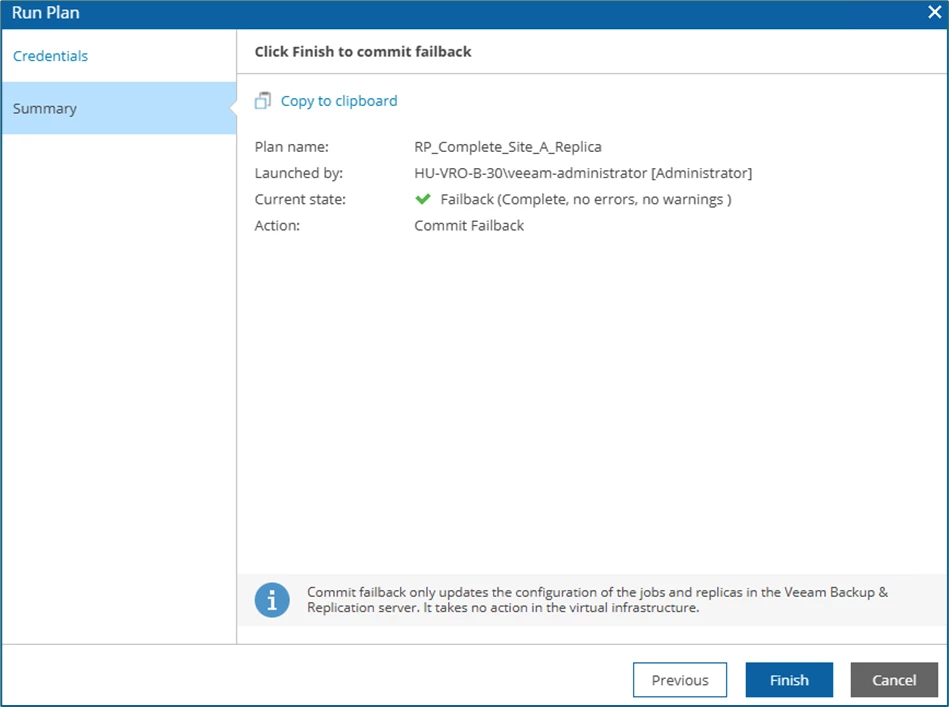
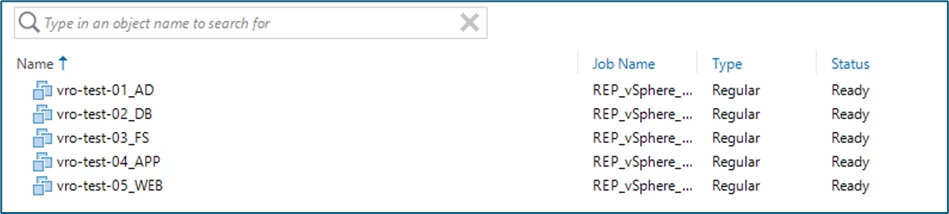
VBR then no longer has a replication or failover task active. The existing replicas are back in Ready state.
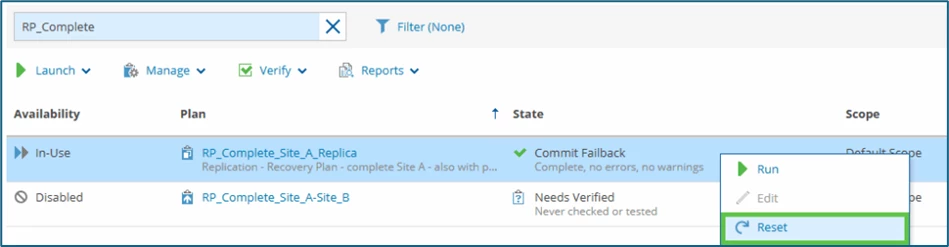
In VRO, the recovery plan (still in the In-Use state) must now be reset. To do this, select the plan and select the Reset option in the context menu.
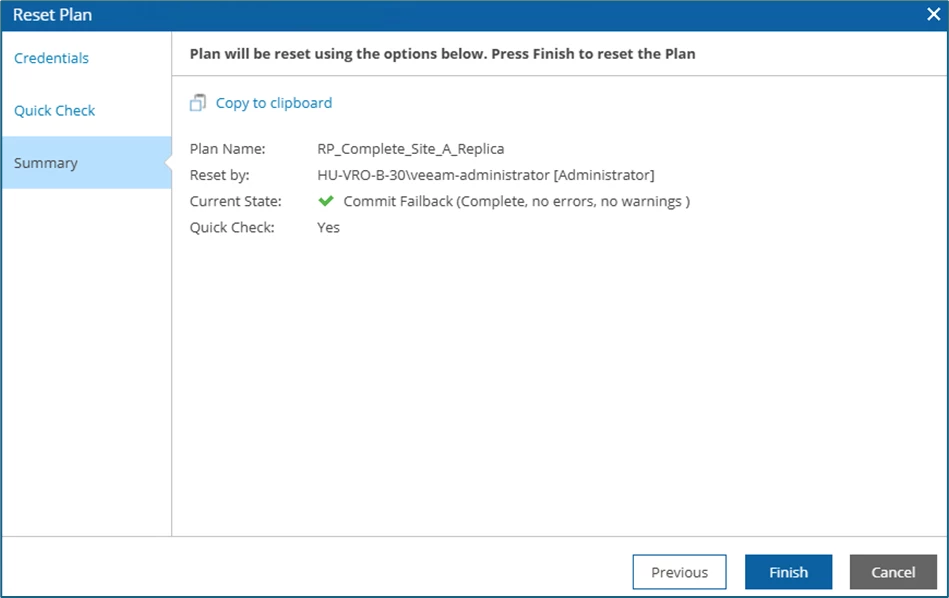
This is followed by entering the Credentials again, the option for a Quick Check (default activated) and the Summary, which will be confirmed with Finish:
These steps have now detailed a step-by-step scenario for a planned failover plan via Veeam Recovery Orchestrator.
Undo
The Undo option is selected if the failover in the DR-site has to be terminated (e.g. the primary site is reachable again) and a transfer of the newly generated delta data is not relevant. The VMs on the DR-site will be shut down again (changes on the DR-site are lost)!
This is not an option for us in this scenario...
Summary
Although a built-in planned failover feature is not currently part of the Veeam Recovery Orchestrator, it is still possible to use it via pre-plan steps .
Compared to a failover plan within VBR, there is the possibility to keep the selection of systems dynamic at all times via tags. The corresponding DataLab tests (which offer more features than a classic SureBackup or SureReplica) also support you in checking your DR scenarios.
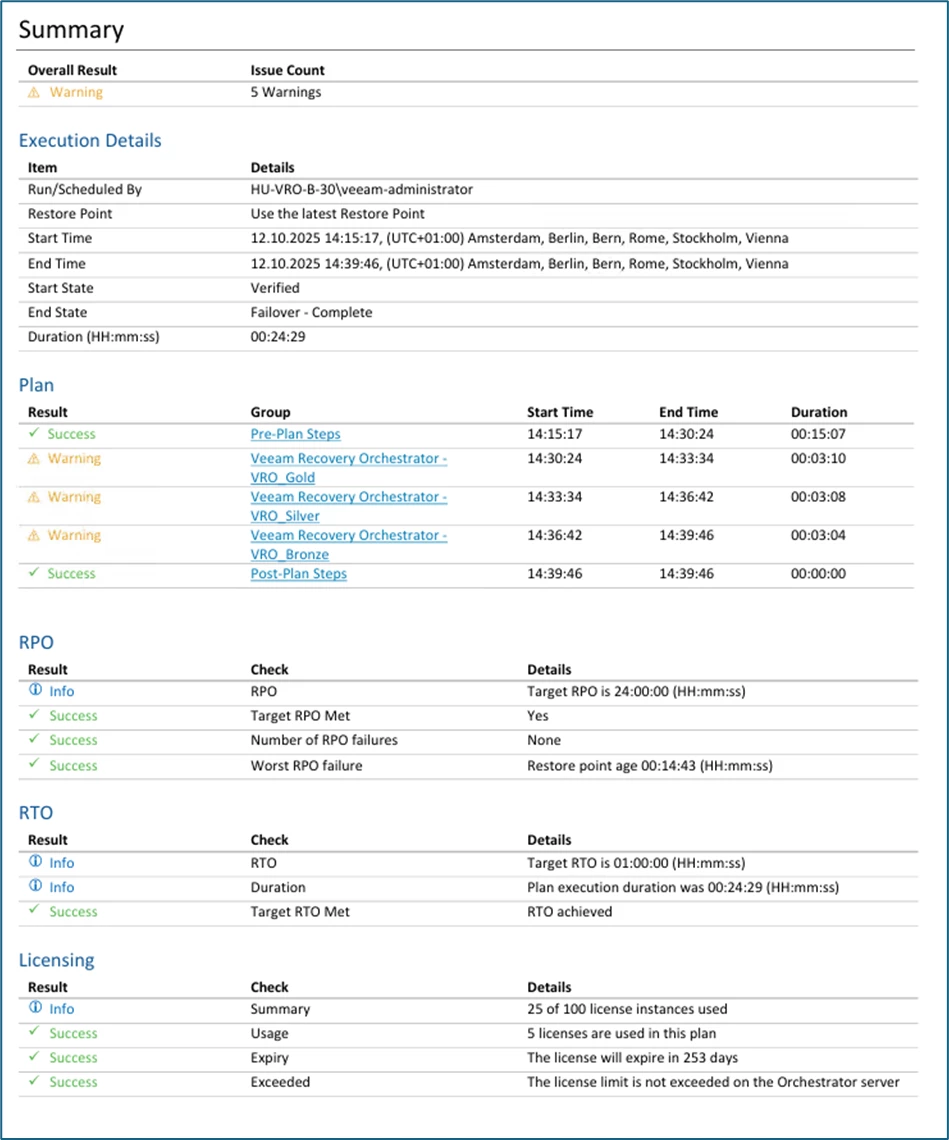
Also worth mentioning is the detailed reporting function integrated into VRO:
Sure, VRO is used to deploy workloads to a DR-site as quickly as possible and not to replicate the delta data from the source side in advance - but there are also such requirements (or customers who want this option).
Have fun trying it out!