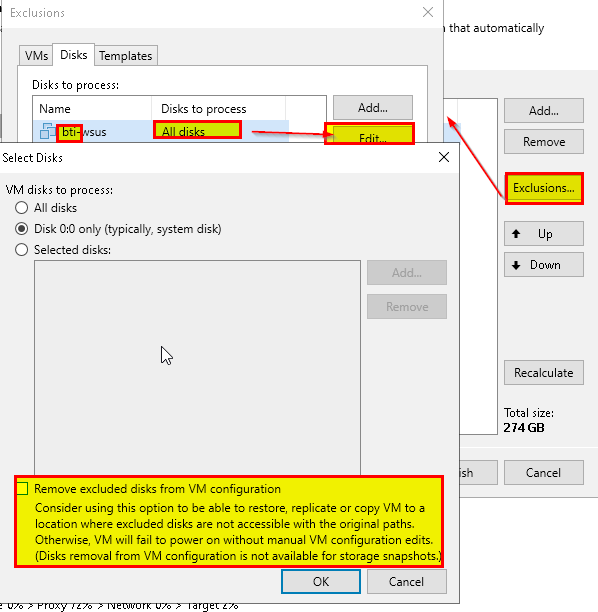
I just had a situation in a customer environment where the customer complained that a restored VM had more disks than the one that was backed up before (6 instead of 5 for a SQL Server VM).
The recovery was done using Entire VM Restore - User Guide for VMware vSphere (veeam.com).
When restoring to the original location, Veeam prompts you that the original VM will be deleted first:
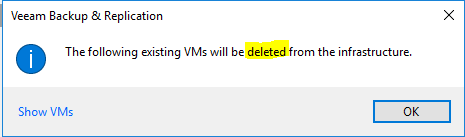
At first, I though this was related to the user that Veeam uses to access vCenter no having the appropriate rights. For example, the user does not have permissions to delete the VM.
But then I noticed that the additional disk to be 200GB in size. The old state the we wanted to restore only had 2x100, 2x300 and 1x500. So where did the 200GB disk come from?
It turns out that the size of this disk was adjusted by the VMware team a few weeks ago (100 → 200). We wanted to restore from an older state with the 100GB still there. Could this be the reason? Does VBR leave resized disks being alone while recovering and adds the older state of those disks on top?
Actually no. I just tested this in my demo environment. So the pure size-adjustment does not give you excess disks.
The real reason is: The VMware team, for some unknown reason, also adjusted the SCSI ID of the same disk (2:0 → 2:1). Veeam actually keeps disks of a VM being overwritten, if none of the disks to be restored has the same SCSI ID.
So the dialog shown above here is misleading. The VM is not deleted, it is just replaced in all the things we have in the backup. Things we don’t have in the backup, like differing SCSI IDs, are left alone.
So no hallucination involved - but still good to know what’s going on. 😎