

Hi Community, time to talk a bit of RAID level, today I will bring to you some number when using R0, R1, R5 and R6, the goal fo this part it is to show how important is to use R6 configured on your RAID controller when you need to use some storage volumes as a DAS repository (using server internal disks, not one external Array)
RAID level 0 - No Fault Tolerance
A RAID 0 configuration provides data striping, but there is no protection against data loss when a drive fails. However, it is useful for rapid storage of large amounts of noncritical data (for printing or image editing, for example).
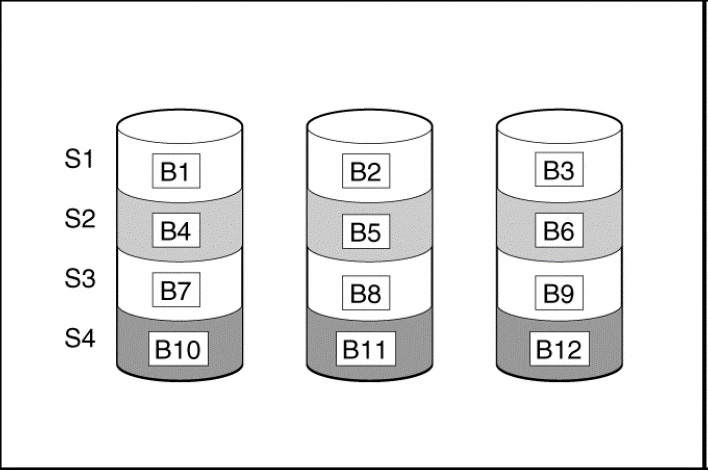
S# = Stripe , B# = Block
Advantages:
• Has the highest write performance of all RAID methods.
• Has the lowest cost per unit of stored data of all RAID methods.
• All drive capacity is used to store data (none is needed for fault tolerance).
Disadvantages:
• All data on the logical drive is lost if a physical drive fails.
• Cannot use an online spare.
• Can only preserve data by backing it up to external drives.
RAID 1+0 (RAID 10)
In a RAID 1+0 (RAID 10) configuration, data is duplicated to a second drive.
When the array has more than two physical drives, drives are mirrored in pairs.
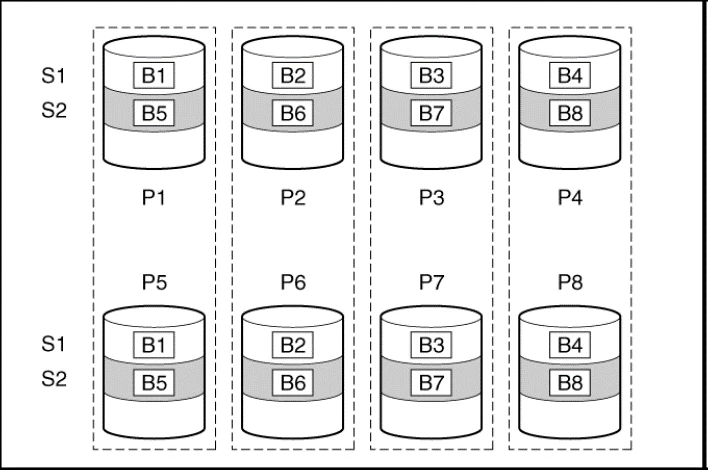
S# = Stripe , B# = Block, P# = Physical Disk
In each mirrored pair, the physical drive that is not busy answering other requests answers any read requests that are sent to the array. This behavior is called load balancing. If a physical drive fails, the remaining drive in the mirrored pair can still provide all the necessary data. Several drives in the array can fail without incurring data loss, as long as no two failed drives belong to the same mirrored pair.
This fault-tolerance method is useful when high performance and data protection are more important than the cost of physical drives.
When there are only two physical drives in the array, this fault-tolerance method is often referred to as RAID 1.
Advantages:
• This method has the highest read performance of any fault-tolerant configuration.
• No data is lost when a drive fails, as long as no failed drive is mirrored to another failed drive.
• Up to half of the physical drives in the array can fail.
Disadvantages:
• This method is expensive, because many drives are needed for fault tolerance.
• Only half of the total drive capacity is usable for data storage.
RAID 5—distributed data guarding
In a RAID 5 configuration, data protection is provided by parity data (denoted by Px,y in the figure). This parity data is calculated stripe by stripe from the user data that is written to all other blocks within that stripe. The blocks of parity data are distributed evenly over every physical drive within the logical drive.
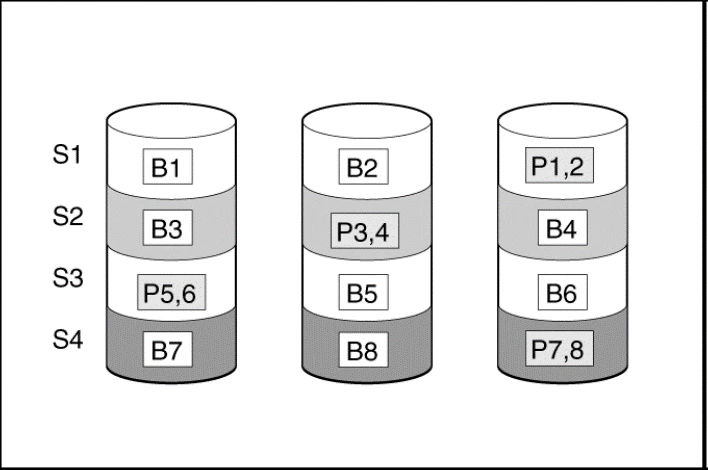
S# = Stripe , B# = Block, Px,y = Parity
When a physical drive fails, data that was on the failed drive can be calculated from the remaining parity data and user data on the other drives in the array. This recovered data is usually written to an online spare in a process called a rebuild.
This configuration is useful when cost, performance, and data availability are equally important.
Advantages:
• Has high read performance.
• Data is not lost if one physical drive fails.
• More drive capacity is usable than with RAID 1+0 — parity information requires only the storage space equivalent to one physical drive.
Disadvantages:
• Has relatively low write performance.
• Data is lost if a second drive fails before data from the first failed drive is rebuilt.
RAID 6 (ADG)—Advanced Data Guarding
RAID 6 (ADG), like RAID 5, generates and stores parity information to protect against data loss caused by drive failure. With RAID 6 (ADG), however, two different sets of parity data are used (denoted by Px,y and Qx,y in the figure), allowing data to still be preserved if two drives fail. Each set of parity data uses a capacity equivalent to that of one of the constituent drives.
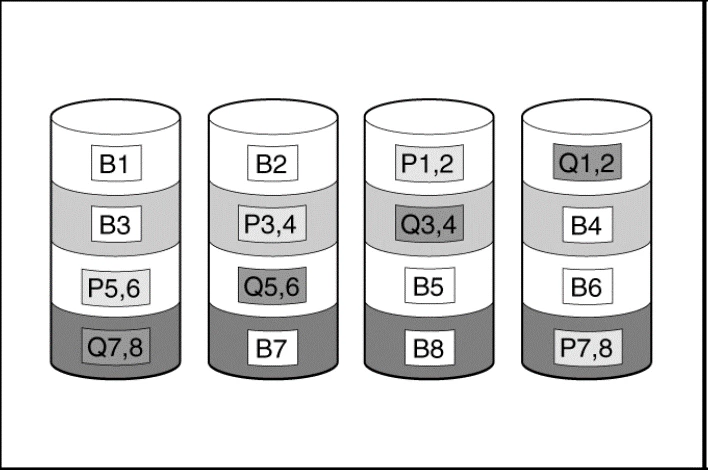
B# = Block, Px,y = Parity 1, Qx,y = Parity 2
This method is most useful when data loss is unacceptable but cost is also an important factor. The probability that data loss will occur when an array is configured with RAID 6 (ADG) is less than it would be if it was configured with RAID 5.
Advantages:
• This method has a high read performance.
• This method allows high data availability—Any two drives can fail without loss of critical data.
• More drive capacity is usable than with RAID 1+0 — Parity information requires only the storage space equivalent to two physical drives.
Disadvantages:
The main disadvantage of RAID 6 (ADG) is a relatively low write performance (lower than RAID 5) because of the need for two sets of parity data.
RAID 50 , RIAD 60 (Nested Array)
Is a nested RAID method in which the constituent hard drives are organized into several identical
RAID 5 or RAID 6 logical drive sets (parity groups). They are organized into two parity groups.
I think explanation of RAID levels up above, will give you relevant information to decide to use RAID6 for DAS Repository (using internal disks)
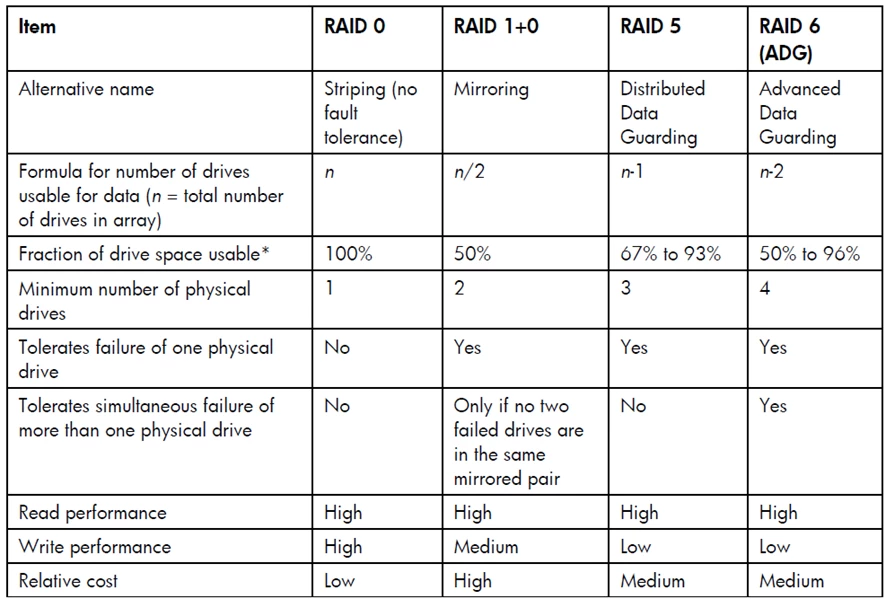
Comparing the hardware-based RAID methods.
Next Topic, I’ll talk about Rebuilding a failed disk!
Hope you enjoy reading :-)
