

So, today I’m gonna show you a simple comparison with 1 VM per job versus 2 or more VM per jobs.
On my scenario I have 2 VM for my Active Directory environment with 40GB size each.
----------------------------------------------------------------------------------------------------------------------------
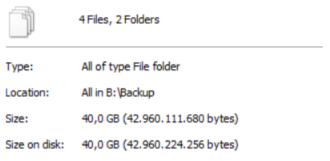
So, in first example I create 1 job per VM:

In this shape it consume exactly 40GB on my repository:
----------------------------------------------------------------------------------------------------------------------------
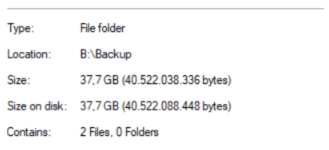
In the second example a create a unique job for the same 2 VM’s:

And in this shape it consume 37GB on my repository:
----------------------------------------------------------------------------------------------------------------------------
How can we see deduplication of Veeam B&R gives a good space on our backups.
In this environment was only 2 small VMs, but now you can imagine how this impact an entire datacenter.
