

Hablamos todo el tiempo de IA. Agentes que automatizan tareas, LLMs que responden tickets, pipelines RAG que conectan nuestros documentos con modelos de lenguaje, clusters de GPUs corriendo fine-tuning a las 3 de la mañana. La IA ya no es un proyecto piloto — es infraestructura productiva.
Y sin embargo, casi nadie en nuestra industria está hablando de lo obvio: ¿qué pasa cuando todo eso falla, se corrompe o desaparece?
El problema no es nuevo, pero el ecosistema sí lo es
Los que llevamos años en el mundo del backup sabemos el mantra: todo lo que importa necesita protección, punto. Eso no cambió. Lo que cambió es el mapa de "qué importa".
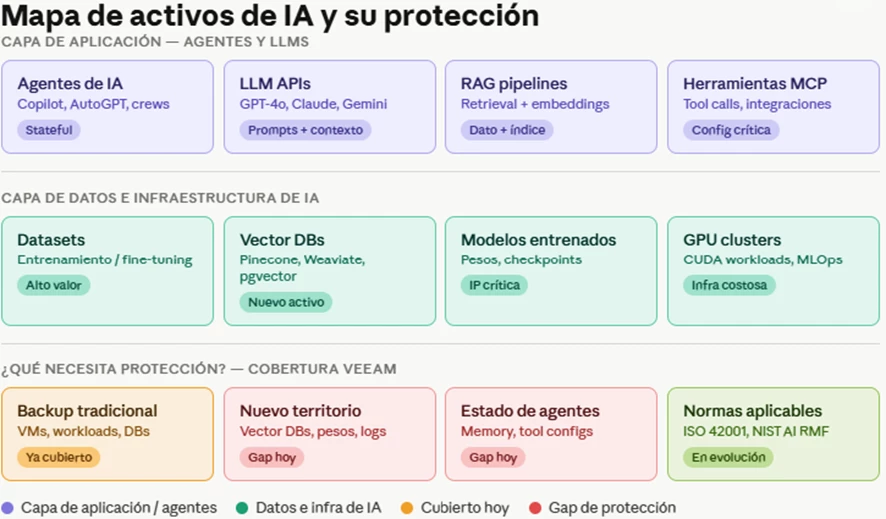
En el ecosistema de IA tradicional, el activo crítico era el dato. Hoy, el mapa se complicó:
Activos de aplicación:
- Agentes con estado (memoria de conversación, configuraciones de herramientas, historial de decisiones)
- Pipelines RAG: el índice vectorial es tan crítico como los datos que lo alimentan
- Configuraciones MCP y tool calls que definen cómo un agente interactúa con el mundo
Activos de infraestructura:
- Pesos de modelos fine-tuneados (esto es IP, no solo datos)
- Checkpoints de entrenamiento — perder un checkpoint puede significar semanas de cómputo tiradas
- Vector databases (Pinecone, Weaviate, pgvector): ¿cuántos tienen un plan de restore documentado para esto?
- Datasets de entrenamiento — curados con meses de trabajo humano
La pregunta que deberían estar haciendo sus equipos hoy: si pierdo mi vector DB de producción, ¿cuánto tarda el restore? ¿Lo probamos alguna vez?
¿Es lo mismo que el backup tradicional?
Parcialmente sí, parcialmente no.
Lo que sigue igual: la regla 3-2-1 sigue siendo válida. La necesidad de RPO/RTO definidos, también. La inmutabilidad del backup como defensa contra ransomware, más vigente que nunca (los datasets de entrenamiento son blancos de alto valor).
Lo que es diferente:
Consistencia transaccional en vector DBs. No es lo mismo que hacer snapshot de una base SQL. Un índice vectorial a mitad de una operación de embedding puede quedar en un estado inconsistente. El backup tiene que ser consciente de esto.
Reproducibilidad vs. restore. En MLOps existe el concepto de "si tengo el código y los datos, puedo reproducir el modelo". Eso es verdad en teoría. En práctica, con dependencias de librerías, versiones de CUDA, y datasets que evolucionan, "reproducible" puede tardar días. Un backup del checkpoint es mucho más pragmático.
Estado de agentes. Un agente con memoria larga (long-term memory) acumula contexto valioso. Ese estado hoy vive en bases de datos propietarias o en archivos ad-hoc. ¿Alguien lo está versionando?
Datasets como activo de compliance. Si tu modelo tomó decisiones basadas en ciertos datos, regulaciones como el EU AI Act van a exigir que puedas demostrar qué datos usaste y cuándo. Eso no es backup operativo, es backup de auditoría.
¿Hay normas que apliquen?
Sí, aunque todavía en maduración:
ISO/IEC 42001:2023 — el primer estándar de sistemas de gestión de IA. Incluye requerimientos sobre ciclo de vida del dato, trazabilidad y gestión de riesgos. No dice "hagan backup" explícitamente, pero la trazabilidad y disponibilidad de datos de entrenamiento es implícita.
NIST AI Risk Management Framework (AI RMF) — el framework del NIST para gestión de riesgos de IA incluye la función "Govern" con controles sobre disponibilidad e integridad de datos.
GDPR / leyes de datos locales — el "right to erasure" vs. la necesidad de mantener datos de entrenamiento para auditoría crea una tensión interesante que el backup strategy tiene que resolver.
SOC 2 / ISO 27001 — ya aplican hoy a la infra de IA si la están corriendo en producción. Los controles de disponibilidad e integridad cubren esta superficie.
La realidad: las normas específicas de IA están llegando, pero los frameworks de seguridad existentes ya son suficiente base para empezar.
¿Qué puede hacer Veeam hoy?
Esto es lo que me parece honesto plantear a la comunidad:
Lo que ya funciona con Veeam en entornos de IA:
- Protección de las VMs y contenedores donde corren los servicios de IA (mismo playbook de siempre)
- Backup de los object storage donde viven los datasets (S3-compatible → Veeam lo cubre)
- Protección de las bases de datos que alimentan los pipelines (PostgreSQL con pgvector, MongoDB, etc.)
- Immutable backups en repositorios SOBR para los datasets críticos
Lo que todavía es territorio a explorar:
- Backup nativo consciente del estado de vector DBs
- Integración con MLflow / DVC para versionar modelos junto con el backup de infra
- Orquestación de restore que incluya re-indexado de embeddings post-recovery
La brecha existe, pero la base que tenemos con Veeam es sólida. El trabajo es mapear los nuevos activos al stack de protección existente, y documentar los gaps para donde la herramienta todavía no llega nativamente.
Ultima pregunta para la comunidad
¿Están protegiendo sus entornos de IA con la misma rigurosidad que el resto de la infraestructura? ¿Tienen un RTO definido para su vector DB? ¿Probaron restore de un checkpoint de modelo alguna vez?
Me interesa saber si esto es un gap real en sus organizaciones o si ya lo tienen resuelto — y cómo.
Glosario para que hablemos el mismo idioma
LLM (Large Language Model — Modelo de Lenguaje Grande) Un programa entrenado con enormes cantidades de texto para entender y generar lenguaje humano. Ejemplo for dummies: es el "cerebro" detrás de ChatGPT o Copilot. Le preguntás algo en castellano y te responde como si fuera una persona.
Agente de IA Un LLM al que le dieron herramientas y autonomía para tomar decisiones y ejecutar acciones por su cuenta, paso a paso. Ejemplo for dummies: no es solo un chatbot que responde — es como un empleado virtual que puede abrir tu email, buscar información, redactar y enviar una respuesta, sin que vos hagas nada.
RAG (Retrieval-Augmented Generation — Generación con Recuperación de Información) Técnica que conecta un LLM con una base de datos propia para que responda con información actualizada y específica de tu organización, no solo con lo que aprendió en su entrenamiento. Ejemplo for dummies: en lugar de que el LLM "adivine" la respuesta, primero busca en tus documentos internos y después responde. Como un consultor que lee tus manuales antes de aconsejarte.
Pipeline Una secuencia automatizada de pasos que procesan datos de principio a fin. Ejemplo for dummies: como una línea de ensamblaje de fábrica — cada estación hace su parte y pasa el resultado a la siguiente.
GPU Cluster Un conjunto de procesadores gráficos (GPUs) trabajando en paralelo para hacer cálculos masivos muy rápido. Ejemplo for dummies: si una CPU es un auto de Fórmula 1 muy veloz, una GPU es un colectivo lleno de pasajeros — no va tan rápido, pero mueve muchísimo más en paralelo. Un cluster es una flota entera de colectivos.
Fine-tuning Proceso de tomar un modelo de IA ya entrenado y entrenarlo un poco más con datos específicos de tu industria o empresa para que sea más preciso en tu contexto. Ejemplo for dummies: comprás un cocinero genial que sabe cocinar todo. El fine-tuning es enseñarle las recetas específicas de tu restaurante.
Vector DB (Base de datos vectorial) Una base de datos especial que no guarda texto plano sino representaciones matemáticas del significado de ese texto (vectores), lo que permite búsquedas por similitud semántica en lugar de por palabras exactas. Ejemplo for dummies: en una base de datos normal buscás "perro" y encontrás solo "perro". En una vector DB buscás "perro" y también encontrás "canino", "mascota" y "labrador" porque entiende que significan cosas parecidas.
Embeddings Las representaciones matemáticas (listas de números) que capturan el significado semántico de un texto. Ejemplo for dummies: es como traducir "feliz" a coordenadas GPS. Palabras con significado similar quedan cerca en ese mapa matemático.
Checkpoint Una "foto" del estado de un modelo de IA guardada durante su entrenamiento, para poder retomar desde ese punto si algo falla. Ejemplo for dummies: como el "guardar partida" en un videojuego. Si el proceso se cae a las 20 horas de entrenamiento, arrancás desde el último checkpoint en lugar de empezar de cero.
MLOps (Machine Learning Operations) El conjunto de prácticas para llevar modelos de IA desde el desarrollo hasta producción y mantenerlos funcionando, de forma similar a como DevOps hace lo mismo con software tradicional. Ejemplo for dummies: los ingenieros que construyen el modelo son como los cocineros. MLOps es la cocina, la logística, la cadena de frío y el delivery que hacen que la comida llegue bien al cliente.
MCP (Model Context Protocol) Un protocolo abierto que define cómo los agentes de IA se conectan e interactúan con herramientas externas (calendarios, bases de datos, APIs, etc.) de forma estandarizada. Ejemplo for dummies: como el puerto USB — en lugar de que cada herramienta tenga su propio conector incompatible, MCP es el estándar que permite conectar cualquier herramienta a cualquier agente.
RPO (Recovery Point Objective — Objetivo de Punto de Recuperación) La cantidad máxima de datos que una organización está dispuesta a perder en caso de un desastre, medida en tiempo. Ejemplo for dummies: si tu RPO es 4 horas, significa que podés tolerar perder hasta 4 horas de trabajo. Si el sistema se cae a las 14:00, el backup de las 10:00 es suficiente.
RTO (Recovery Time Objective — Objetivo de Tiempo de Recuperación) El tiempo máximo que puede tardar en restaurarse un sistema después de una falla. Ejemplo for dummies: si tu RTO es 2 horas, el negocio puede aguantar hasta 2 horas sin ese sistema. Si tarda más, hay un problema serio.
SOBR (Scale-Out Backup Repository — Repositorio de Backup Escalable) Una funcionalidad de Veeam que combina múltiples repositorios de almacenamiento en uno solo lógico, con políticas de tiering automático. Ejemplo for dummies: en lugar de tener 5 discos rígidos separados que tenés que gestionar uno por uno, SOBR los agrupa en un único "pool" inteligente que mueve los datos al lugar más barato o seguro según las reglas que vos definís.
Immutable backup (Backup inmutable) Un backup que, una vez escrito, no puede ser modificado ni eliminado durante un período definido — ni siquiera por un administrador. Ejemplo for dummies: como grabar algo en un CD en lugar de un pendrive. Una vez grabado, nadie puede borrarlo, ni el ransomware, ni un error humano.
ISO/IEC 42001 El primer estándar internacional de sistemas de gestión para inteligencia artificial, publicado en 2023. Define cómo las organizaciones deben gobernar el ciclo de vida de sus sistemas de IA. Ejemplo for dummies: como el ISO 9001 de calidad pero para IA. Un marco que dice "si usás IA en serio, estas son las prácticas mínimas que deberías tener."
NIST AI RMF (AI Risk Management Framework) Un framework del Instituto Nacional de Estándares y Tecnología de EE.UU. que guía a las organizaciones para identificar, medir y gestionar los riesgos asociados al uso de IA. Ejemplo for dummies: una guía práctica del gobierno americano que dice "acá están los riesgos de usar IA y así los podés gestionar". No es obligatorio, pero es muy respetado en la industria.
EU AI Act La primera ley integral de regulación de inteligencia artificial a nivel mundial, aprobada por la Unión Europea. Clasifica los sistemas de IA por nivel de riesgo y establece obligaciones según esa clasificación. Ejemplo for dummies: como el reglamento de tránsito pero para la IA. Si tu sistema de IA toma decisiones de alto impacto (créditos, contratación, salud), tiene que cumplir requisitos estrictos — incluyendo poder explicar y auditar qué datos usó.
GDPR (General Data Protection Regulation) El reglamento europeo de protección de datos personales, vigente desde 2018. Establece derechos para los ciudadanos sobre sus datos y obligaciones para quienes los procesan. Ejemplo for dummies: si un europeo te pide que borres sus datos de tus sistemas, estás obligado a hacerlo. El problema con la IA: si esos datos se usaron para entrenar un modelo, ¿cómo los "borrás" del modelo sin reentrenarlo?
SOC 2 (Service Organization Control 2) Un estándar de auditoría de seguridad para empresas de tecnología que demuestra que sus controles de seguridad, disponibilidad e integridad son confiables. Ejemplo for dummies: es el "certificado de confianza" que un proveedor de software o nube le muestra a sus clientes para decir "auditores independientes verificaron que nuestros sistemas son seguros."
DVC (Data Version Control) Una herramienta open source para versionar datasets y modelos de ML, similar a lo que Git hace con el código. Ejemplo for dummies: Git guarda el historial de cambios de tu código ("ayer el archivo decía X, hoy dice Y"). DVC hace lo mismo pero con archivos de datos gigantes y modelos de IA que Git no puede manejar por su tamaño.
MLflow Una plataforma open source para gestionar el ciclo de vida de modelos de ML: experimentos, versiones, deploy y monitoreo. Ejemplo for dummies: un cuaderno de laboratorio digital que registra cada experimento de entrenamiento — qué datos usaste, qué parámetros probaste, qué resultado obtuviste — para que puedas comparar y reproducir cualquier versión.