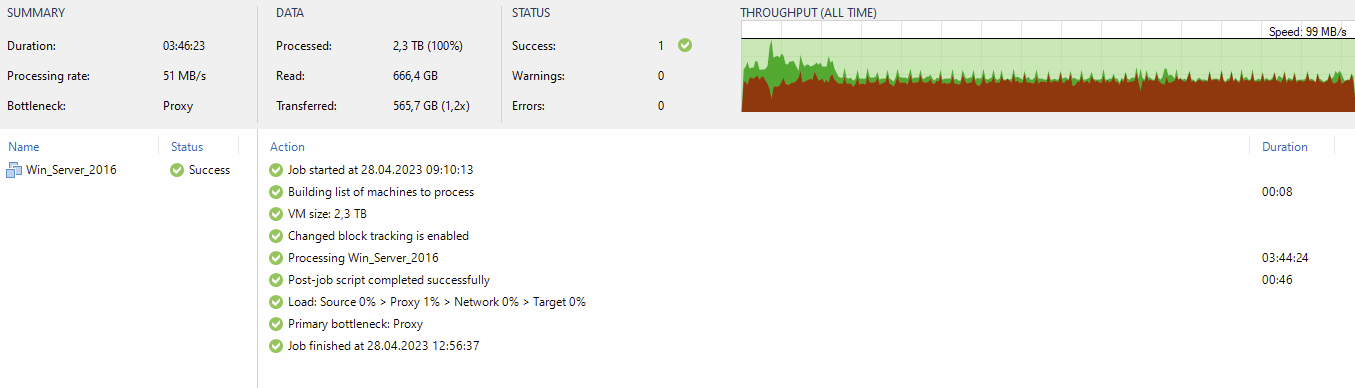
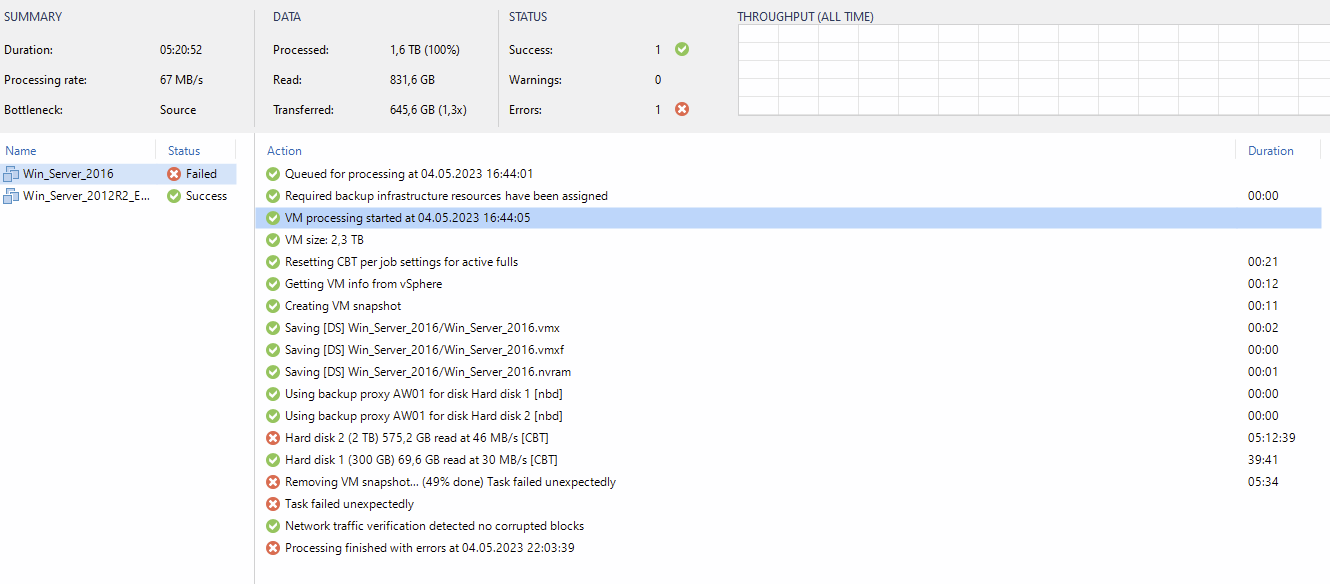
I learned a lot during the last few weeks about Veeam and I am kind of exited about this software. I resolved almost all problems, but there is still one issue I cant get a grip on. Ich have several backup jobs in a chain. No parallel Jobs. I have a lightning fast proxy (Veeam suggests a maximum of 24 parallel jobs).
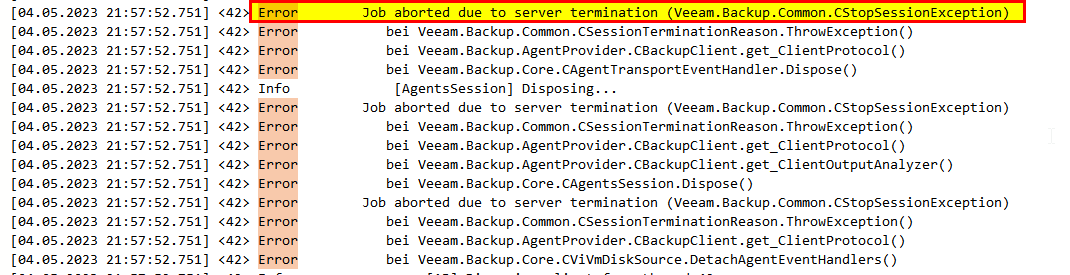
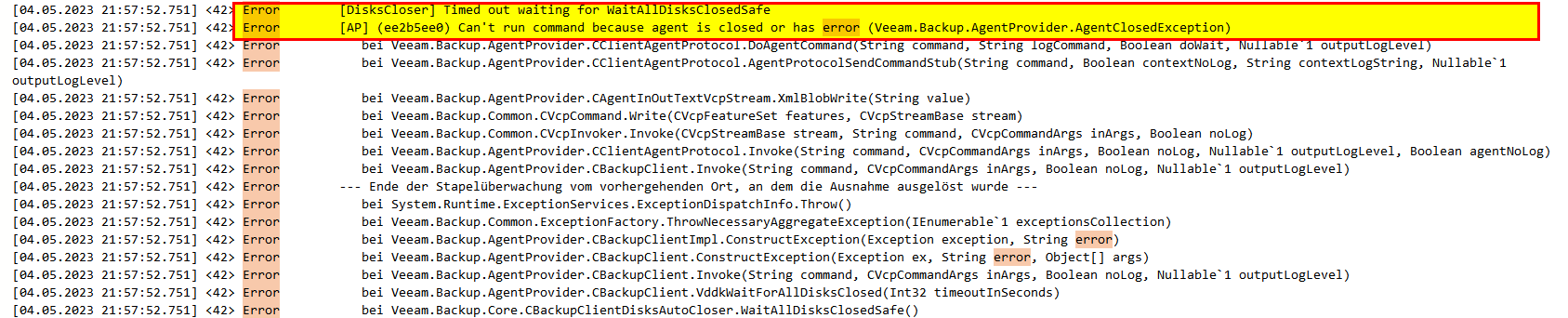
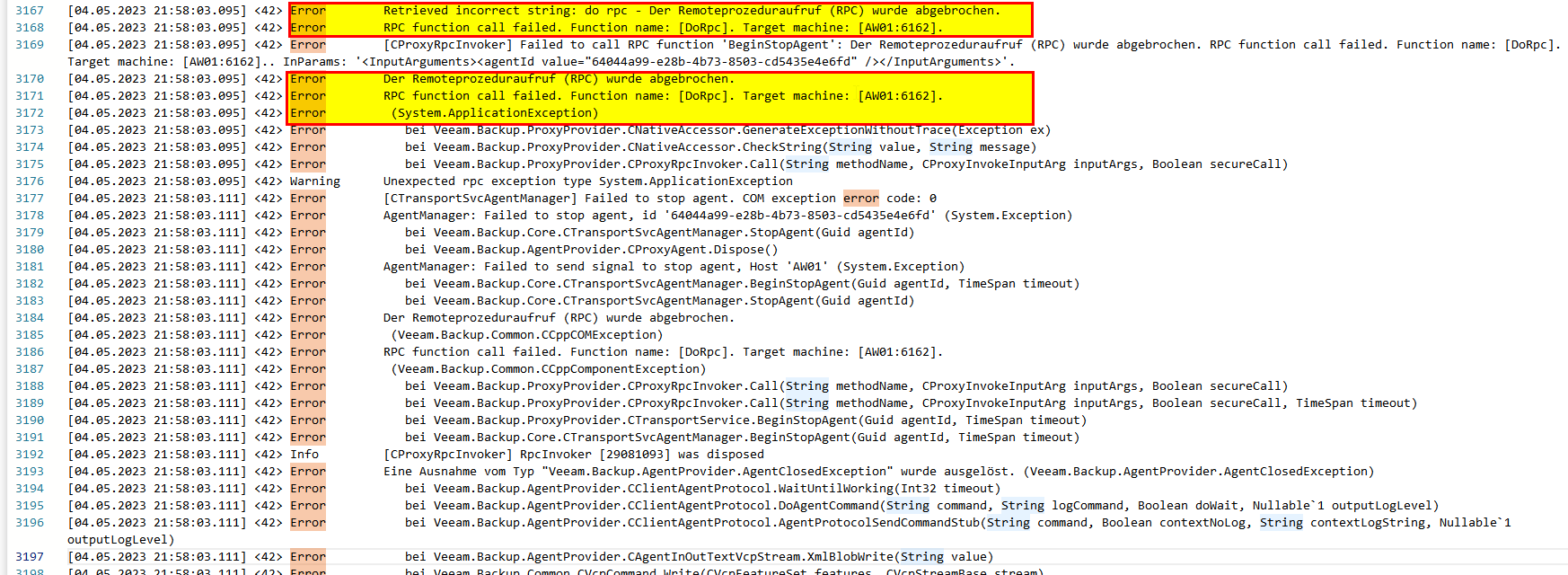
My persisting promlem is, that jobs get stuck absolutly randomly. Sure, after hours the stuck job fails, goes into retry1 and finishes successfull. But thats not satisfying… Is there anything I missed about jobs getting stuck? Just for your information: Jobs launch and run. They get stuck somewhere after 20%, 50% or 90%. So abolutly random… I recognized that the “veeam backup service” gets completly frozen. This service cant be stopped by anything else than a server restart.