

One consequence of the market changes resulting from Broadcom VMware's new positioning of its software solutions and licenses is that the topic of “hypervisors” is now being analyzed in greater technical detail than ever before.
In search of more realistic alternatives that fit IT departments’ budgets, organizations are turning their attention to market options.
On the other hand, there is the open-source software community. I truly have a great admiration for the thousands of programmers, engineers, and software architects who dedicate their efforts to free software communities.
Today, alternatives to the VMware hypervisor are solutions built on a stack of open-source projects, with varying degrees of customization and architectural differences.
The purpose of this post is to analyze how a generic hypervisor architecture, based on QEMU and KVM, handles disk write I/O requests.
It´s a fascinating topic (at least for me).
Let’s explore the rationale behind the development of each component of the QEMU/KVM stack and how they integrate to provide virtualized applications with an optimized architecture that enables maximum disk-write performance.
How Open-Source Virtualization Evolved
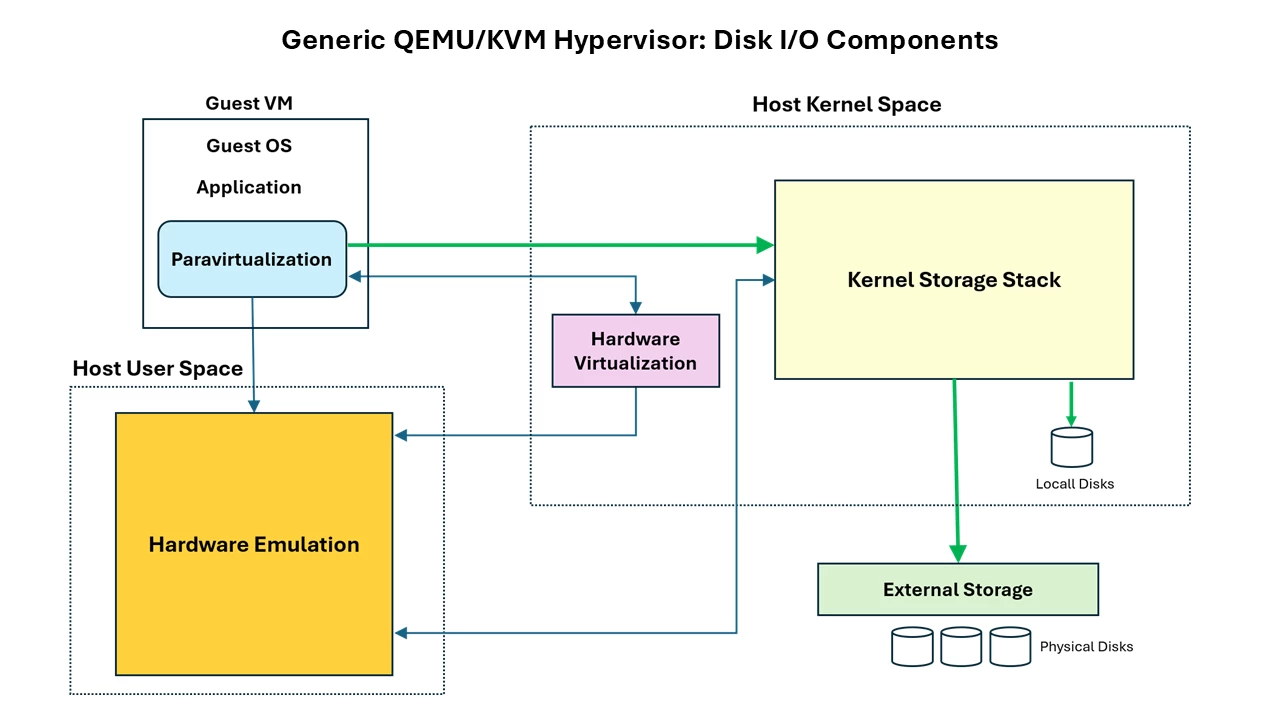
The high-level architecture above represents the data path in a generic hypervisor architecture, specifically the runtime path used by guest workloads for disk I/O.
Let's go back to 2003, two years after the release of VMware ESX.
In that time, software compiled for one CPU architecture could not run on a completely different architecture. So, it was necessary to create a hardware emulation layer to ensure software portability across different CPUs.
The open-source Quick EMUlator (QEMU) introduced dynamic binary translation, allowing guest CPU instructions to be translated on the fly and executed on the host processor.
More importantly, QEMU could emulate not just CPUs, but memory, BIOS, storage controllers, and NICs. As it could emulate a complete computer system, QEMU made it possible to run an entire operating system inside another operating system.
QEMU enabled virtualization on x86 systems, but because it relied primarily on software emulation, it was still slower than native execution for many workloads.
A major change happened around 2005 and 2006 when CPU manufacturers introduced hardware-assisted virtualization technologies. Intel released VT-x, and AMD released AMD-V. These new processor extensions enabled virtual machines to execute privileged instructions directly with hardware support, rather than relying entirely on software.
Hardware-assisted virtualization became practical at scale.
Recognizing this opportunity, the KVM (Kernel-based Virtual Machine) was introduced in 2006, also as an open-source project.
The idea behind KVM was elegant and simple: instead of creating a completely separate hypervisor operating system, Linux itself could become the hypervisor. By adding a small virtualization module into the Linux kernel, each virtual machine could be treated almost like a regular Linux process.
KVM could handle CPU and memory virtualization at the Linux kernel level. But KVM alone could not create a complete virtual machine because it did not provide virtual disks, network cards, BIOS firmware, or PCI buses.
Developers quickly realized that this functionality already existed in QEMU, and it could complement KVM perfectly.
The integration between them started soon after KVM’s creation and became mainstream around 2007.
But a final and important challenge still remained: the I/O performance.
In terms of I/O for disks, the QEMU originally exposed storage devices to guest operating systems, and, for compatibility reasons, virtual machines emulated legacy storage devices, such as IDE and later SATA controllers.
When the guest wanted to write a file, its storage driver communicated with what it thought was a physical IDE controller. QEMU then had to emulate device registers, interrupts, DMA transfers, queue management, and timing behavior before finally sending the request to the host Linux storage stack and then to the real disk.
However, this emulation model introduced significant overhead.
To solve this bottleneck, the concept of Paravirtualization emerged.
Instead of pretending that the guest was interacting with a real physical IDE or SATA controller, paravirtualization introduced the idea that the guest operating systems could be aware that they were running inside a virtual machine and communicate more efficiently with the hypervisor using optimized virtual devices.
This is where the VirtIO open source paravirtualized device framework became fundamental. It was originally developed as part of the KVM/QEMU virtualization stack within the Linux ecosystem.
VirtIO defined a standardized framework for paravirtualized devices, including block storage.
With VirtIO, the guest no longer interacts with a fully emulated legacy hardware controller. Instead, the guest uses a lightweight VirtIO driver designed explicitly for virtual environments.
Communication between the guest and host became based on shared memory ring buffers called VirtQueues, drastically reducing the number of emulation steps required.
This is a very brief overview of the factors that led to the development of these solutions and how they are intrinsically linked.
Numerous developments and improvements have been made, bringing us to the current level of maturity of modern open-source-based virtualization solutions on the market.
Write Disk I/O Path in a QEMU/KVM + VirtIO Stack
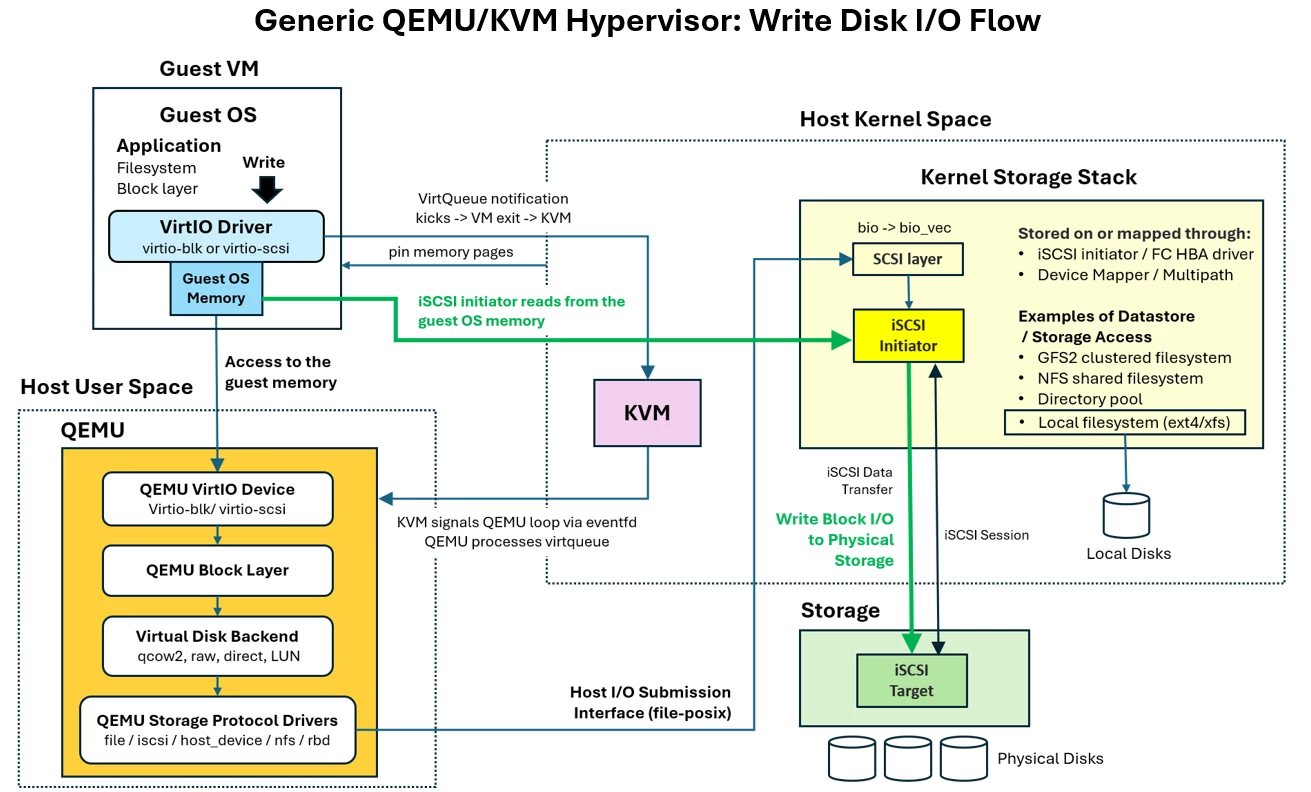
Let’s take a general look at what happens when an application hosted on a virtual server requests a disk block write I/O in a QEMU/KVM-based virtualization solution using VirtIO.
First, the VirtIO drivers must be installed on the guest operating system. Without the appropriate drivers, the guest cannot communicate with VirtIO block or other devices exposed by QEMU/KVM.
For Linux guests, VirtIO drivers are usually already included in the kernel. For Windows guests, you typically install the VirtIO driver package from the KVM/QEMU ecosystem.
When an application inside the VM performs a write operation, the request is first handled by the guest OS block I/O subsystem. The write travels through the guest filesystem and block layer exactly as it would on a physical machine.
At this stage, the guest operating system is unaware of the underlying physical or shared storage implementation and treats the request as a standard block device operation.
The VirtIO Driver Operations
The guest VirtIO driver, typically “virtio-blk” or “virtio-scsi”, converts the block I/O request into a descriptor chain and submits it to a VirtQueue.
According to the VirtIO specification, VirtQueues are the primary mechanism used for communication between the guest driver and the virtual device implementation (for example, QEMU).
The VirtQueue consists of three regions: a Descriptor Table, an Available Ring, and a Used Ring.
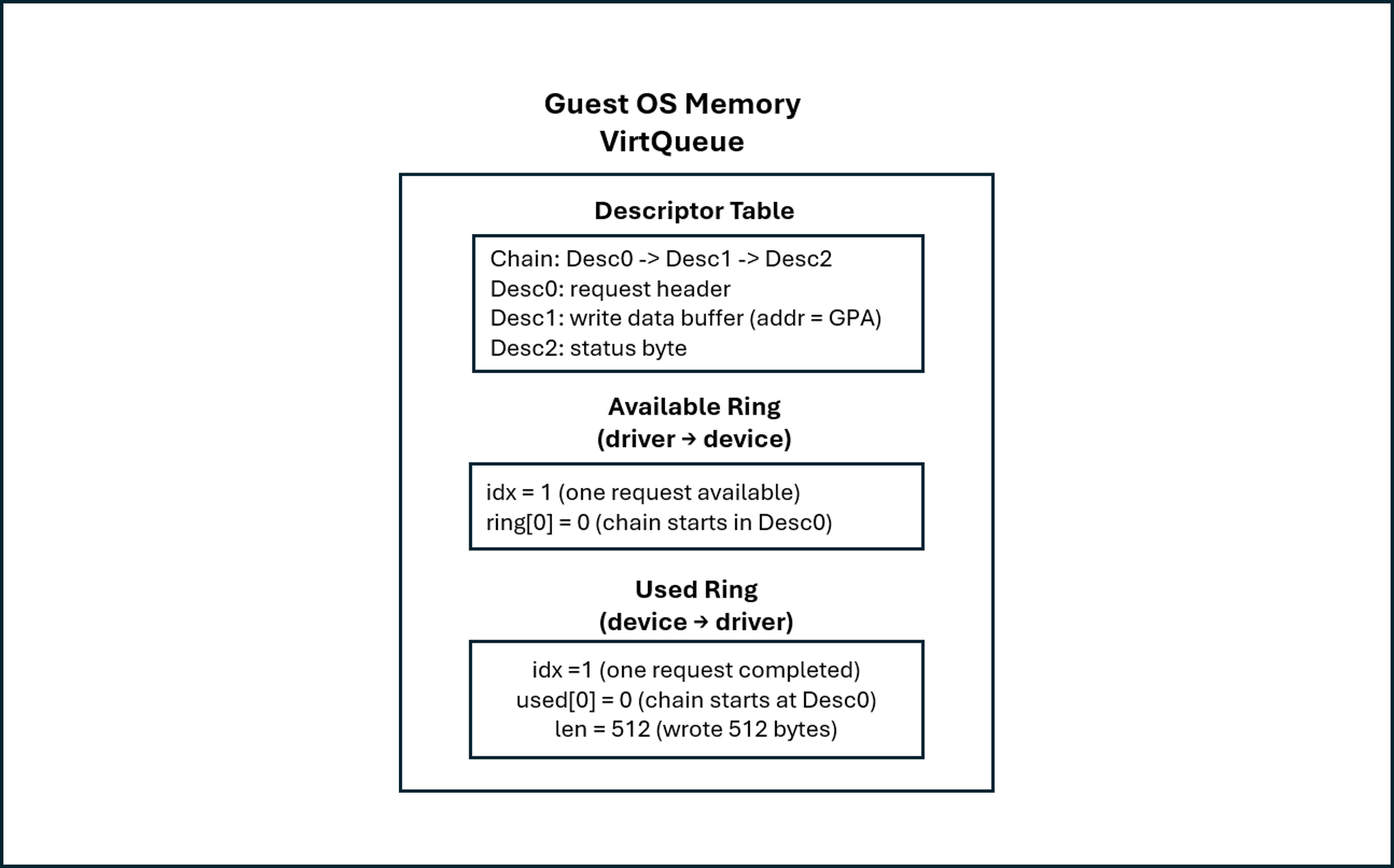
The Descriptor Table contains descriptors (virtq_desc) that describe guest memory buffers through fields such as the guest-physical address (addr), buffer length (len), descriptor flags (flags), and an optional pointer to the next descriptor in the chain (next).
By linking descriptors in the next field, the driver can construct descriptor chains that allow a single I/O request to reference multiple buffers, such as a request header, a data buffer, and a completion status buffer.
The Available Ring is written by the driver and read by the device. Each ring entry stores the index of the head descriptor of a submitted descriptor chain. After placing the head descriptor index into the available ring and updating the available ring index (idx), the driver notifies that a new request is available for processing.
The Used Ring is written by the device (QEMU) and read by the driver. It's used to notify the driver that the kernel storage stack has completed the I/O request.
Using shared guest-memory mappings, it's possible to access the guest buffers directly while minimizing unnecessary data copies and latency.
VirtIO and QEMU: The Near Zero-Copy Path
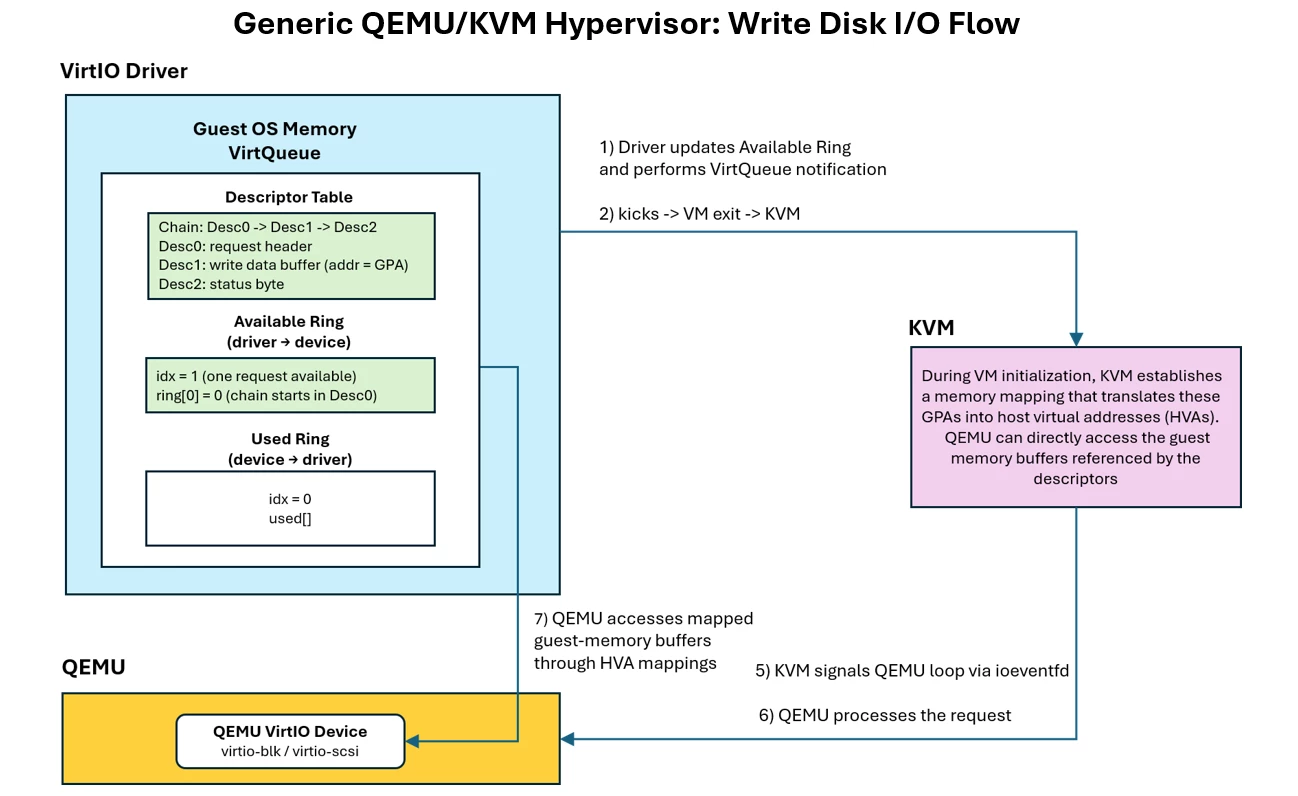
The VirtIO driver does not directly notify QEMU when data becomes available.
Once the guest VirtIO driver updates the Available Ring, it issues a VirtQueue notification by writing to the device notification register, commonly referred to as a "kick".
In traditional implementations, this notification typically causes a “VM exit”, a controlled transition in which the CPU temporarily halts execution of the guest's code and transfers control to the hypervisor layer.
KVM intercepts the MMIO/PIO notification write associated with the VirtQueue kick. Rather than emulating the storage operation directly during the VM exit path, KVM signals an “ioeventfd” to QEMU.
Also, during VM initialization, KVM establishes a memory mapping that translates the Guest Physical Addresses (GPAs) into Host Virtual Addresses (HVAs), effectively mapping the guest OS's RAM pages into QEMU's User Space address.
These mappings are typically stable during normal VM execution unless memory topology changes occur.
Thanks to these GPA-to-HVA mappings, the QEMU VirtIO Device implementation can directly read or write to the guest OS's memory buffers referenced by the descriptors.
After waking up on the “ioeventfd” notification, the QEMU VirtIO Device traverses the Available Ring and descriptor chain and accesses the mapped guest-memory buffers.
At this stage, the request metadata and payload data still reside in guest RAM pages referenced by the VirtQueue descriptors.
This largely zero-copy path significantly reduces CPU overhead and memory bandwidth consumption, which is especially important for high-throughput storage workloads.
QEMU Layers
After QEMU accesses the guest memory buffers referenced by the VirtQueue descriptor chain, the request travels on multiple layers within the QEMU stack before being submitted to the Linux Kernel Storage.
During this process, the guest payload usually remains stored in the mapped guest-memory pages, while QEMU progressively transforms, translates, and orchestrates the I/O request metadata according to the configured storage backend and protocol drivers.
Therefore, the request is forwarded from the QEMU VirtIO Device to the QEMU Block Layer, which serves as the central abstraction and orchestration layer between the virtual machine and the underlying storage backend.
This layer translates the VirtIO block request into internal block I/O operations and routes them through to an internal block graph architecture.
It´s a directed acyclic graph composed of BlockBackend and BlockDriverState (BDS) node objects, where each node can represent a format driver (qcow2, raw), a filter (throttle, copy-on-read), or a protocol driver (iSCSI, RBD).
As the request traverses the block graph, the block layer may split, merge, align, throttle, queue, or reorder it according to backend constraints, configured storage policies, and image format requirements.
For example, if a guest issues several small sequential writes, the block layer may merge them into a single larger I/O operation before submitting to the storage backend, reducing overhead and improving throughput.
The Virtual Disk Backend layer is where the block layer's internal I/O operations are translated into reads and writes against a specific disk image format or storage target.
Its job is to map the guest's logical block addresses into actual byte offsets where data will be stored. How it does this depends on the image format.
It supports multiple formats and targets like QCOW2 images (with features like thin provisioning, snapshots, and internal compression), raw image files (offering direct byte-for-byte mapping with no metadata overhead), host block devices (bypassing the filesystem layer entirely for lower latency), or iSCSI/FC LUNs (exposing remote storage as local block devices).
The QEMU Storage Protocol Drivers layer handles the last mile, delivering the I/O operation from QEMU to the actual storage infrastructure on the host.
At this point, the block layer has already decided what to do (write, in our example), the virtual disk backend has determined where the data lives (the physical offset), and the protocol driver now determines how to get there.
Each driver knows exactly how to talk to a specific type of storage.
From QEMU to the Linux Kernel Storage Stack
Once QEMU's format driver maps the guest OS's logical block address to a byte offset in the host image file, it must hand off the I/O to the Linux Kernel Storage.
This happens in two stages: what to send and how to send it.
For example, the “file-posix” protocol driver does this by passing three pieces of information to the kernel via a system call:
- File descriptor to identify the host image file or block device.
- Byte offset to the exact position in the host file where the data should be written, computed by the format driver.
- “iovec” array provides a list of (address, length) pairs pointing directly to the guest OS's memory buffers via the HVA mappings. This allows gathering data from the guest OS memory.
The “file-posix” driver then chooses a submission backend to deliver that information to the kernel.
The backend is configured via the “aio” option and determines the system call mechanism used: “threads”, “native”, or “io_uring”. All three system calls deliver the same information but differ in how efficiently they transfer it to the kernel.
iSCSI Storage: How the Kernel Processes the I/O
Once QEMU’s file-posix submits the I/O request to the Linux kernel, the host kernel takes ownership of the operation and prepares it for delivery to the storage subsystem.
First, the Linux kernel pins the guest OS memory pages referenced by the “iovec” structures received from QEMU. Once the pages are pinned, the kernel block layer builds a bio request whose “bio_vec” entries reference those pages directly.
Pinning prevents those pages from being moved or swapped while the I/O operation is in progress. Instead of copying the guest data into temporary kernel buffers, the kernel keeps direct references to the original guest memory pages.
Then, the kernel block layer builds a “bio”, the kernel's standard representation of a block I/O request. The “bio” contains: the target block device; the starting logical sector; the operation type (WRITE in our example); and a collection of “bio_vec” entries.
Each “bio_vec” points to one of the pinned guest OS pages, with an offset and length within that page. This way, the kernel describes the entire I/O operation as a set of references to the guest OS's memory.
Therefore, it avoids unnecessary data copies by referencing pinned pages directly.
For example, if the target is external iSCI storage, instead of programming a local disk controller, the kernel forwards the “bio” to the Linux SCSI subsystem. The SCSI layer converts the block request into SCSI commands, such as a SCSI WRITE operation.
The host-side iSCSI initiator then encapsulates the SCSI commands and the associated guest memory data into iSCSI Protocol Data Units (PDUs).
The initiator reads directly from the pinned guest OS memory pages and transmits the data over TCP/IP to the remote iSCSI target.
At this point, the data leaves the host machine's RAM for the first time.
On the storage side, the iSCSI target receives TCP/IP packets, reconstructs iSCSI PDUs, extracts the SCSI commands and data payload, and passes the write request to its local storage stack.
The target storage subsystem then writes the data to physical disks.
Write Completion and Confirmation Back to the Application
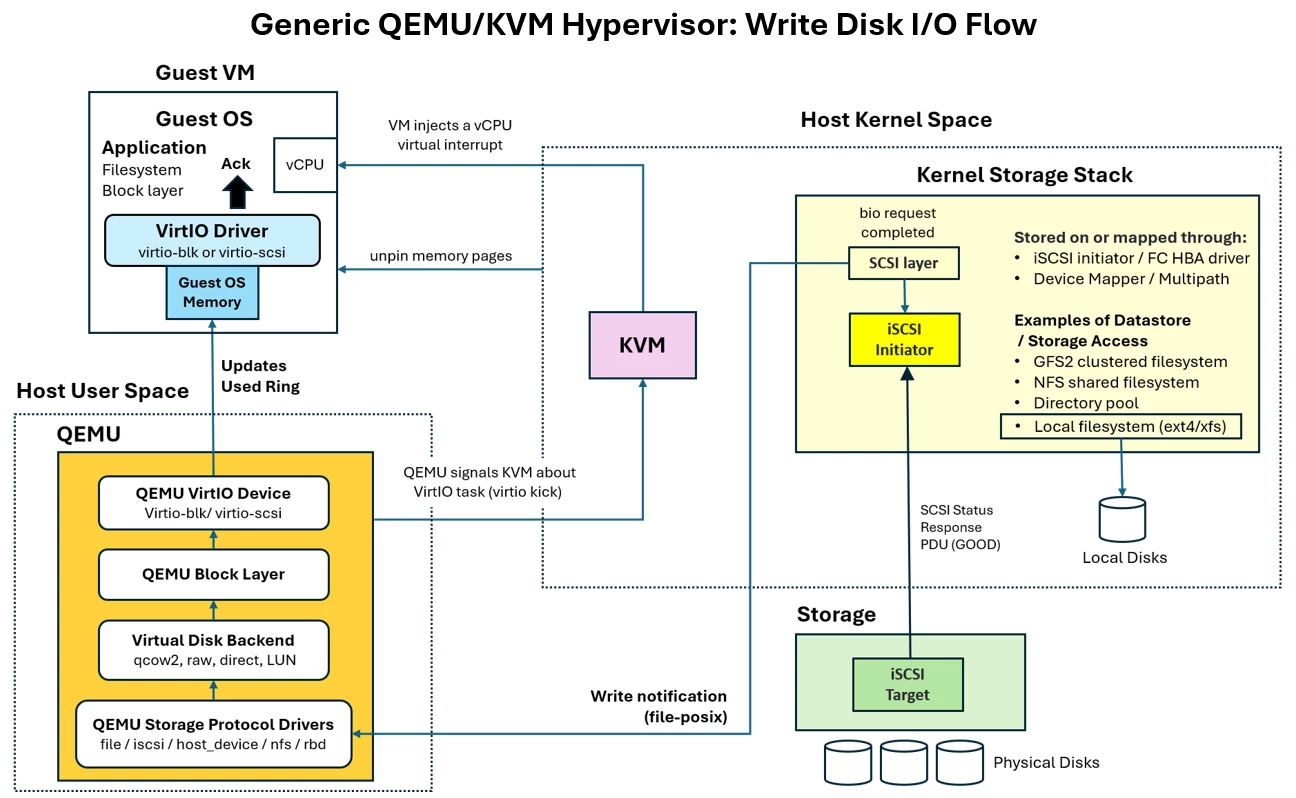
After the iSCSI target has written the data to the physical storage disks, it returns a SCSI status response (PDU) of GOOD to the host-side iSCSI initiator.
After the write operation is processed according to the storage device’s completion semantics, the iSCSI target sends a SCSI response “PDU GOOD” back to the host-side iSCSI initiator.
For a successful write, this means the target has accepted and completed the request in accordance with the storage device's semantics.
The initiator then completes the I/O in the Linux kernel, allowing the completion status to propagate back through QEMU, VirtIO, and finally to the guest operating system and application.
The Linux SCSI layer and block layers then complete the original “bio” request associated with the operation.
As completion propagates upward, the kernel marks the submitted I/O as finished, unpins the guest memory pages referenced by the “iovec”.
After the Linux block layer completes the bio request, the kernel notifies QEMU via the asynchronous I/O completion mechanism used by the “file-posix” driver.
QEMU receives this completion signal, finalizes the corresponding request in its internal block layer, and forwards the completion status to the QEMU VirtIO Device.
The QEMU VirtIO Device updates the VirtQueue Used Ring, including the descriptor chain identifier and the number of bytes processed.
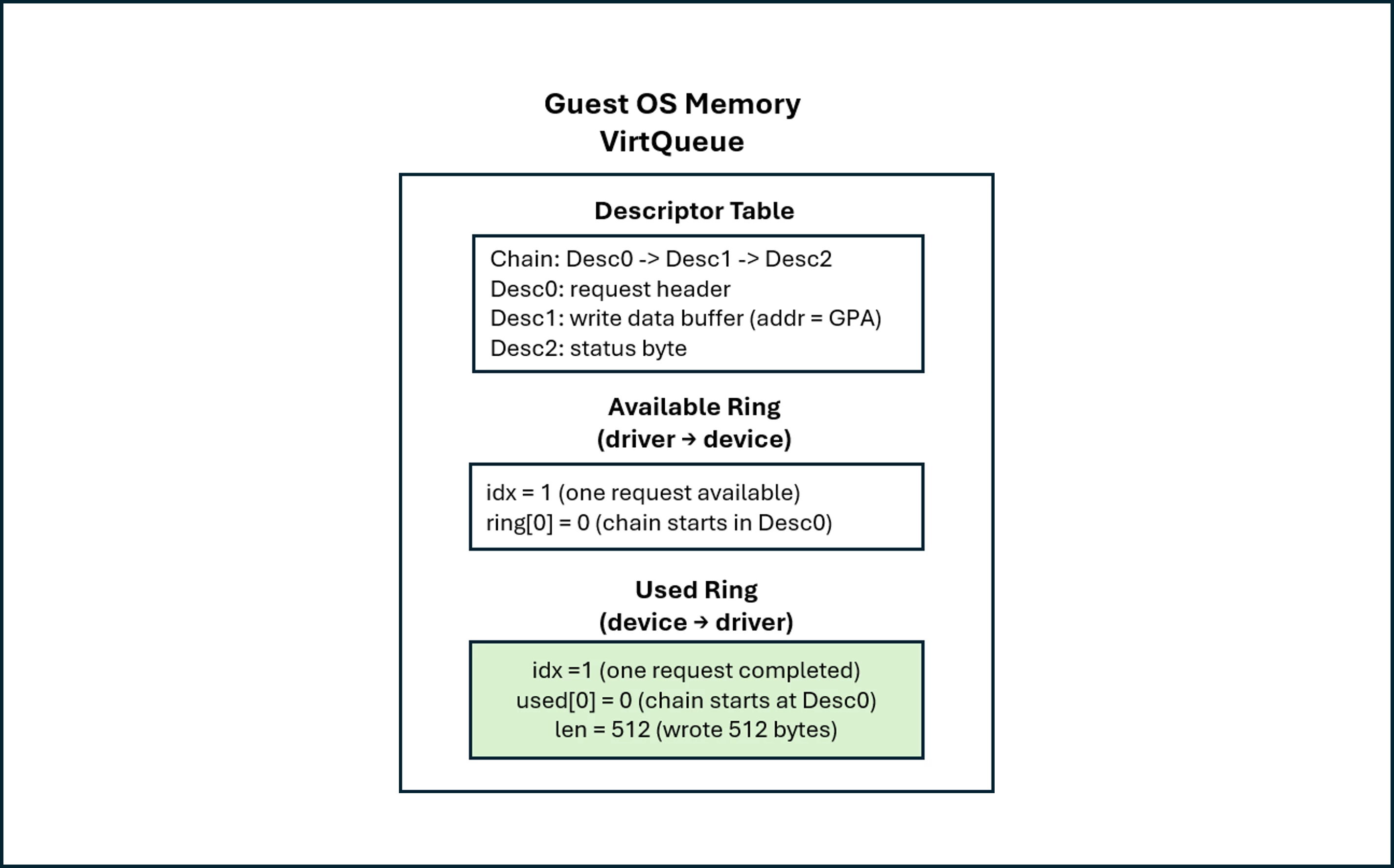
QEMU then notifies the guest VirtIO that completion information is available. This notification is delivered through KVM as a virtual interrupt.
To trigger the notification, QEMU performs a “virtio kick” by signaling the guest VirtIO device's virtual interrupt mechanism, typically via MSI-X or another PCI interrupt delivery method exposed to the VM.
KVM injects the corresponding virtual interrupt into the guest virtual CPU (vCPU).
When the guest vCPU next runs, the guest operating system’s interrupt handler executes and dispatches control to the guest VirtIO driver, which handles the interrupt, reads the Used Ring entry, validates the completion status, and completes the original block request in the guest OS block layer.
After processing the Used Ring entry, the guest VirtIO Driver reclaims the descriptor chain.
Once the block request is completed, the guest OS block layer and filesystem can release, recycle, or keep the used RAM pages in cache, according to guest memory management and caching rules.
Finally, the guest OS wakes any process waiting for that write to complete.
From the application’s perspective, the write is considered complete only after the guest block layer propagates the successful completion status back through the filesystem and system call layers to the application itself.
How the Guest Application Sees the iSCSI Volume
From the application's perspective, the iSCSI volume is entirely transparent, appearing as a plain block device such as “/dev/vda” or “/dev/vdb”.
The VirtIO Block Driver registers it with the guest OS kernel's block layer as a generic disk, indistinguishable from a local or a file-backed virtual disk.
IN our example, the application has no awareness of the underlying VirtIO descriptor chains, the QEMU layers, the iSCSI initiator, the network transport, or the remote storage target behind it.!-->
Additional Notes
The write I/O path described in this article follows the standard QEMU VirtIO backend model, where QEMU's event loop processes VirtQueue entries in userspace.
In high-performance or latency-sensitive deployments, two alternative backends can bypass the QEMU event loop entirely:
- “vhost-blk”: A kernel-resident backend that processes VirtQueue descriptors directly inside the host kernel, eliminating the QEMU userspace context switch.
- “vhost-user-blk”: A separate userspace daemon (outside QEMU) that handles VirtQueue processing, commonly used with storage frameworks like SPDK.
In both cases, the VirtQueue shared-memory layout and the guest VirtIO driver remain identical. Only the host-side consumer of the descriptors changes. The standard QEMU path described in this post remains the baseline and most widely deployed model.
Also, this post describes the VirtQueue as a separate format (a separate Descriptor Table, Available Ring, and Used Ring).
Virtual I/O Device Version 1.3 introduced a Packed VirtQueue format that unifies these into a single descriptor ring, improving cache locality.
Conclusion
QEMU/KVM, combined with VirtIO, provides a strong foundation for open-source virtualization, combining performance, flexibility, transparency, and broad ecosystem support.
KVM benefits from the maturity of the Linux scheduler, memory management, networking, and storage subsystems, avoiding the need for a separate proprietary hypervisor stack.
VirtIO is one of the key advantages of this architecture. Instead of emulating full physical hardware, it provides a paravirtualized interface in which the guest and host cooperate via efficient shared-memory VirtQueues.
This reduces VM exits, avoids unnecessary data copies, lowers CPU overhead, and delivers near-native I/O performance for block and network devices.
On the other hand, QEMU can connect the same guest-facing VirtIO disk to multiple backends, including raw files, QCOW2 images, host block devices, iSCSI, NFS, Ceph, and other storage systems, without changing the application or the guest operating system.
These qualities make it one of the most important building blocks for modern open-source hypervisors and cloud platforms, enabling scalable virtualization without vendor lock-in.
References:
https://www.kernel.org/doc/html/latest/virt/kvm/api.html
https://www.qemu.org/documentation/
https://www.qemu.org/docs/master/system/
https://www.qemu.org/docs/master/system/introduction.html
https://libvirt.org/drvqemu.html
Virtio on Linux — The Linux Kernel documentation
Virtual I/O Device (VIRTIO) Version 1.3
Writing VirtIO backends for QEMU — QEMU documentation
virtio - Linux Kernel Internals
Block Device Drivers — The Linux Kernel documentation
Immutable biovecs and biovec iterators — The Linux Kernel documentation
aio-posix.c - qemu - Git at Google
iSCSI initiator (or client) - Ubuntu Server documentation
Live Migrating QEMU-KVM Virtual Machines | Red Hat Developer
QEMU vs. KVM: Exploring the Virtualization Giants · Cloudzy Blog


