

AI in Production on OpenShift: Designing for Resilience, Portability, and Control
At Red Hat Summit 2026 in Atlanta, Veeam delivered a lightning talk that reframes how platform engineers should think about AI workloads on OpenShift.
The core shift: AI placement is no longer a technical decision — it's a business and risk decision.
"The question is no longer 'Can I run AI here?' — it's 'Where should this workload run, and under whose control?'"
This post covers the key architectural principles from that session, the data that backs them up, and a concrete use case that shows what this looks like in practice.
Why Placement Matters More Than Ever
The assumption that AI lives in the public cloud is already outdated. The actual distribution of AI/ML workloads today:

- 65% on-prem, colocation, specialist GPU clouds, or network operators
And placement has real operational consequences:

The driver behind this is a shift toward AI sovereignty — and it goes well beyond data residency.
Sovereign AI: Control + Proof + Recoverability
Sovereignty is often reduced to "where does the data live?" That framing misses most of the problem. A complete sovereign AI posture requires three layers:
1. Technical Sovereignty
Control of the platform, infrastructure, AI models, runtimes, software supply chain, and deployment portability.
On OpenShift this means: controlling which operators are deployed, which model runtimes are approved, how images are signed and scanned, and whether the full stack can be replicated to another location.
2. Data Sovereignty
Control over data classification, residency, access, processing, encryption, and AI usage boundaries.
On OpenShift this means: ODF encryption at rest, customer-managed keys, namespace-scoped access policies, and audit trails for who accessed which dataset and when.
3. Operational Sovereignty
Control of identity, privileged access, automation, observability, audit evidence, continuity, and recovery.
This is the layer most teams underinvest in — and the one that matters most when something goes wrong.
Key insight: You can have full technical and data sovereignty and still lose operational sovereignty if you can't prove, audit, and recover the full AI operating model under pressure.
Design Principle: Resilience Is an Architecture Pattern
The session was direct about this:
"OpenShift AI resilience is an architecture pattern, not a feature bolted on after production."
The implication for platform engineers: recovery must understand the full dependency graph of an AI system — not just the storage layer.
What That Graph Looks Like
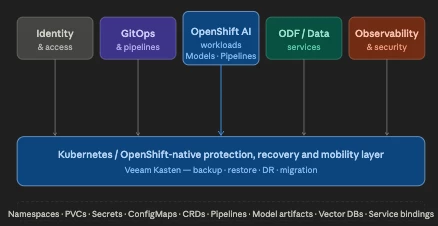
Each of these layers has state that needs to be captured as a single recoverable unit — not backed up independently. A recovery that restores the model weights but not the serving config, or the pipeline but not the secrets, is not a real recovery.
What Needs to Be Protected as a Unit
| Component | Why It Matters |
|---|---|
| Persistent Volumes | Model weights, training data, checkpoints |
| Namespaces + K8s Objects | Deployments, Services, InferenceServices |
| Secrets + ConfigMaps | API keys, endpoint configs, feature flags |
| Pipelines, Notebooks & Jobs | Reproducibility of training runs |
| Model Artifacts + Metadata | Versioning, lineage, experiment tracking |
| Vector DBs & Feature Stores | RAG context, embeddings, feature snapshots |
| Data Services & Dependencies | External connections, S3 bindings, DB credentials |
Concrete Use Case: Protecting a Fine-Tuning Pipeline on OpenShift AI
Let's make this concrete. Consider this scenario:
Environment: OpenShift AI (RHOAI) + ODF
Workload: A Llama 3 fine-tuning pipeline running weekly on a dedicated GPU node pool
Requirements: Reproducible training runs, DR to a secondary cluster, 4-hour RTO
The Problem Without Proper Protection
Without a Kubernetes-native protection layer, a typical team would back up:
- The ODF persistent volumes (raw storage snapshot)
- Maybe the namespace manifests via
oc exportor a GitOps repo
What they'd miss:
- The exact state of the
DataScienceClusterandInferenceServiceCRDs at backup time - The Kubeflow Pipeline run state and artifact references
- The vector database state (if using RAG) — often a separate PVC with no snapshot policy
- Secrets bound to the training job (S3 credentials, Hugging Face tokens)
- The model registry entry pointing to the correct artifact version
When you try to restore to a secondary cluster, the pipeline starts but fails because the secret references are broken, the model registry points to a stale version, and the vector DB is three days behind.
The Solution With Kasten
Kasten treats the entire namespace — including all the CRDs, secrets, PVCs, and service bindings — as a single logical application. The protection policy looks like this:
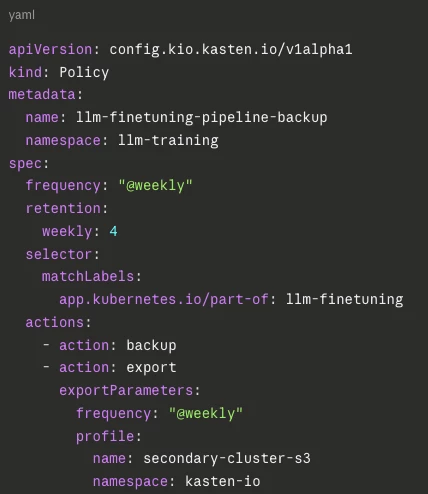
This single policy captures:
- All PVCs in the namespace (model checkpoints, training datasets, vector DB)
- All Kubernetes objects (Deployments, Jobs, InferenceServices, DataSciencePipelines CRDs)
- All Secrets and ConfigMaps
- Custom Resources from RHOAI operators
On restore to the secondary cluster, Kasten replays the full namespace state — secrets, CRD instances, PVC data — in the correct order, respecting dependencies.
What Changes With Kasten v9.0 in This Scenario
Before v9.0: Each weekly backup snaps the full PVC for model checkpoints — which, for a fine-tuned 7B model, can be 15-20 GB per checkpoint. Four weekly backups = 60-80 GB just for checkpoints.
With v9.0 incremental backup (OCP-V VMs): If any part of the pipeline runs inside a KubeVirt VM (common in air-gapped or regulated environments where the training node is a hardened VM), the incremental API reduces each weekly export to only the changed blocks since the last snapshot — potentially 80-90% smaller after the first full backup.
Additional v9.0 improvements relevant to this use case:
- AI Blueprints for application-consistent snapshots of vector databases before backup
- Export to multiple simultaneous locations (primary S3 + Veeam Vault) in a single policy
- Admission controller enforcement to prevent unprotected namespaces from being created
Meeting the 4-Hour RTO
With Kasten exporting to a secondary cluster's S3 location:
- Trigger restore from Kasten dashboard on secondary cluster (~2 min)
- Namespace and all K8s objects recreated in correct order (~5-10 min depending on CRD complexity)
- PVC data restored from export location (~varies by size, parallel restore per PVC)
- InferenceService comes online, readiness probe passes (~5 min)
For a typical RHOAI fine-tuning namespace with 20-30 GB of PVC data and moderate CRD complexity, total restore time is well within the 4-hour RTO — often under 60 minutes with a well-configured S3 export profile.
The Consistent OpenShift AI Operating Model
The architectural takeaway from the Summit session: the goal is a consistent operating model across locations — private/on-prem, sovereign cloud, edge, and public cloud.
Control / Sovereignty
▲
│
Private / │ Sovereign
on-prem │ cloud
│
Data gravity/latency ───────┼─────────────────── Global scale
│
Edge │ Public
│ cloud
│
▼
Speed / Elasticity
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Consistent OpenShift AI operating model across
all four deployment venues — backed by Kasten
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Kasten's role is to make sure that a workload that was running in private cloud can be recovered, migrated, or replicated to any other location — without manually rebuilding the application topology.
Key Takeaways for Platform Engineers
-
Back up the system, not the container. Storage snapshots alone are not sufficient for AI workloads. The K8s object graph, CRDs, secrets, and data services need to be captured together.
-
Sovereignty requires recoverability. Technical and data controls mean nothing if you can't recover the full operating model under a real incident.
-
Placement flexibility requires protection portability. If your backup can't follow the workload to a different location, you've constrained your placement options.
-
Incremental backup changes the economics for VM-based workloads. For teams running GPU training nodes as KubeVirt VMs (air-gapped, regulated, or hardened environments), Kasten v9.0 makes recurring backup costs manageable.
-
Policy-driven protection at the label level. Dynamic label selectors mean new namespaces and VMs are automatically enrolled in the right policy without manual intervention — critical for teams deploying new experiments frequently.
Conclusion : Protection for OpenShift Workloads. Anywhere.
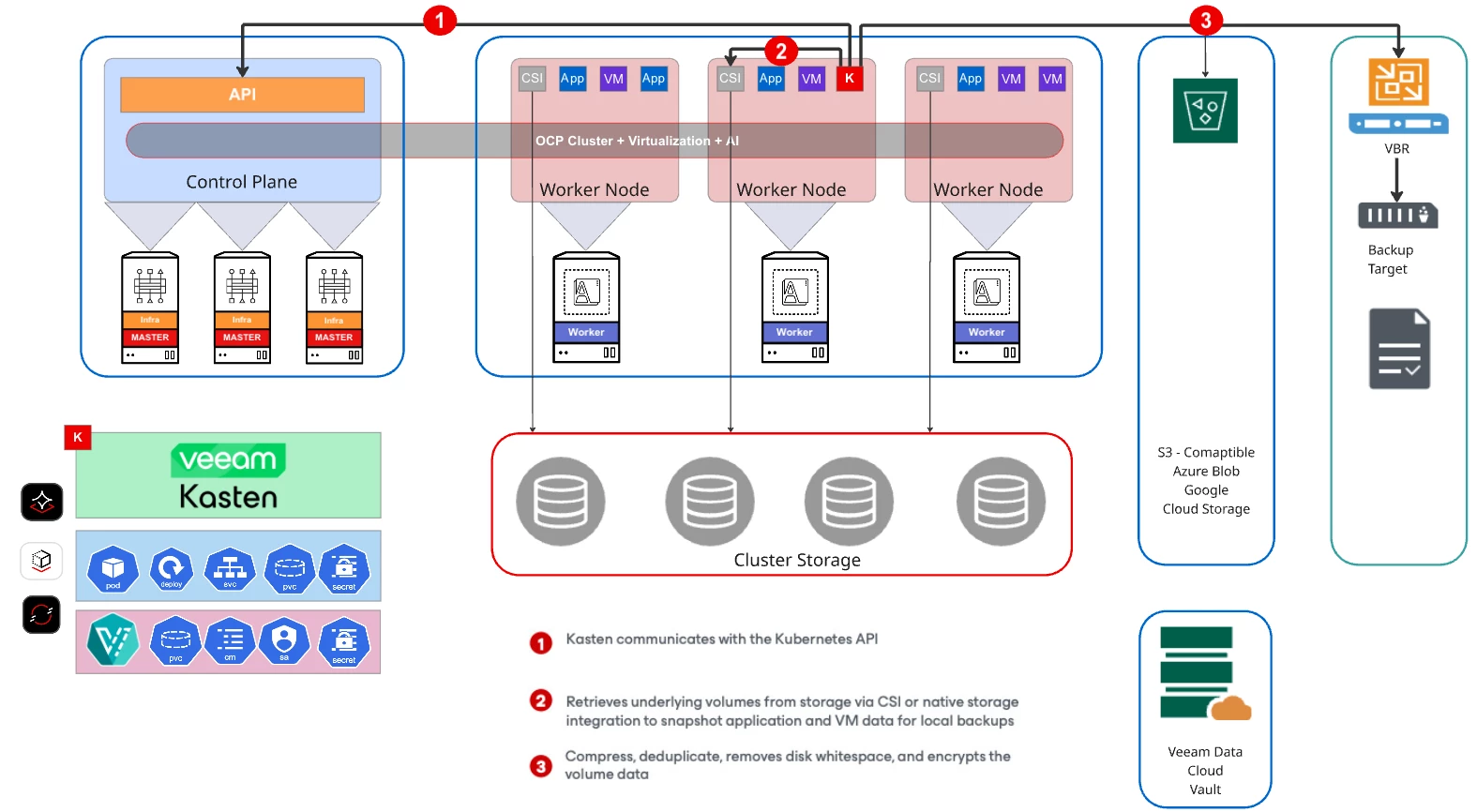
"If you're running AI/ML workloads on Kubernetes today — how are you protecting the full application boundary? Not just the storage layer, but pipeline state, model artifacts, secrets, and CRDs as a single recoverable unit?"

