

Disaster’s happen and businesses need to be ready for them. If 2020 taught us anything, it might be to expect the unexpected. Sometimes we can’t plan for the unexpected, but when it comes to data and applications businesses depend on, planning for the unknown is critical. Whether it be a natural disaster, a data outage or a ransomware attack, businesses need to remain online, and by creating a Disaster Recovery and Business Continuity plan now, it can save us later. One technology that is included in this type of plan is failover. Utilizing replica failover can help achieve the best Recovery Time Objectives (RTOs) by having a copy of your VM in a ready to start state. If your new to Veeam, you might be unsure of the different failover capabilities it has to offer. Throughout this post, I will walk through Veeam’s failover capabilities and describe their meanings and benefits of each.
Introduction to Failover
Failover is a process in which you seamlessly switch operations from the source machine to a reliable replica on a target host, or one that resides offsite. Replica failover is initiated when the original VM is no longer available, whether it has been destroyed or is experiencing an outage. Failover planning is necessary when planning for an unexpected disaster and should be part of any business’s BCDR planning.
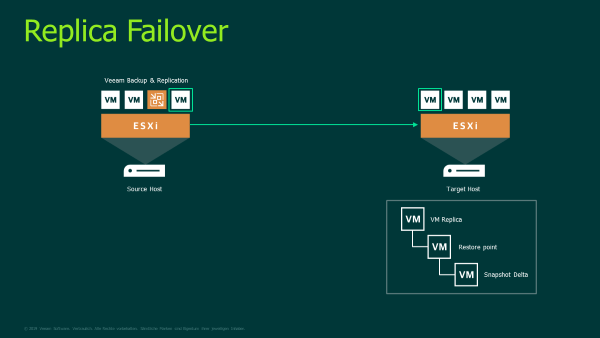
When understanding how Veeam Backup & Replication performs failover, it’s important to explain how Veeam replicates machines. When Veeam creates a replica, it leverages VMware vSphere snapshot capabilities. A snapshot is considered a point-in-time copy of the VM, including its configuration, OS applications, and any of its associated data. This snapshot is used as the source for replication.
Veeam’s Replica Failover Process
Replication is a part of failover, allowing you to have a machine ready to fail to when a disaster happens. When you perform a failover, a fully functional VM is recovered by failing over to its replica at a target site. When this is done, the replica VM takes over for the original VM. This is a temporary step and needs to be further finalized through either permanent failover or failback. Now the question might be, when do I decide that I should permanently failover or perform a failback? This all comes down to the situation you are in, and if the DR site resources can operate the machine(s) at the level required.
Permanent Failover
Permanent Failover should be considered if you have totally lost the production site. It can be considered as “committed” because it permanently switches from the original VM to the replica VM. Hence, the replica VM will no longer exist, and takes the role of the original VM. Now this might not be the best decision for every environment, and depends on what resources are available at the DR site to sustain the machine. When creating a DR site, both should be nearly equal in the number of resources, so when you perform a failover of the replica, it can sustain the workload. However, in some situations this is not possible, therefore a failback to production might be the better option.
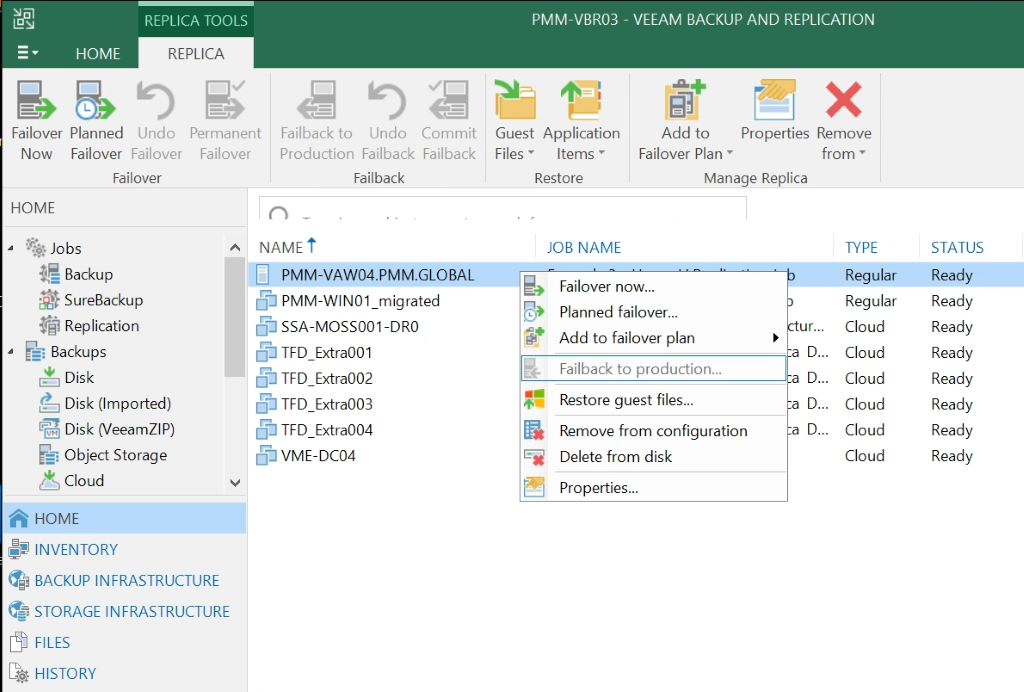
When you right click on the replica you plan on failing over, there are different options available. The failover now option means that the VM selected will immediately start the failover process. This powers on the VM replica at the target site. It is important to note that in this case, the last time the replica job ran will be the current state of the machine. This means that any changes that were made to the source VM between the time the last replica job ran and the failover now operation, will not be migrated to the target replica.
This process would need to be further finalized by either permanently failing over or performing a failback.
Other operations include performing a planned failover, or adding the VM to a failover plan. Let’s discuss both of these a bit more.
Failover Plans
In any environment, you might have VMs or applications that rely on each other, and therefore need to be powered on in a certain order. For this, you have the option to create a failover plan. This should be done in advance, so if the primary VM group goes offline, you can start the VMs in the plan simultaneously (according to the required order). When creating a failover plan, you prearrange the order in which each VM is processed and powered on. Additionally, you gain the option to set a time delay, meaning you can ensure a VM is running and powered on before powering on a dependent VM.
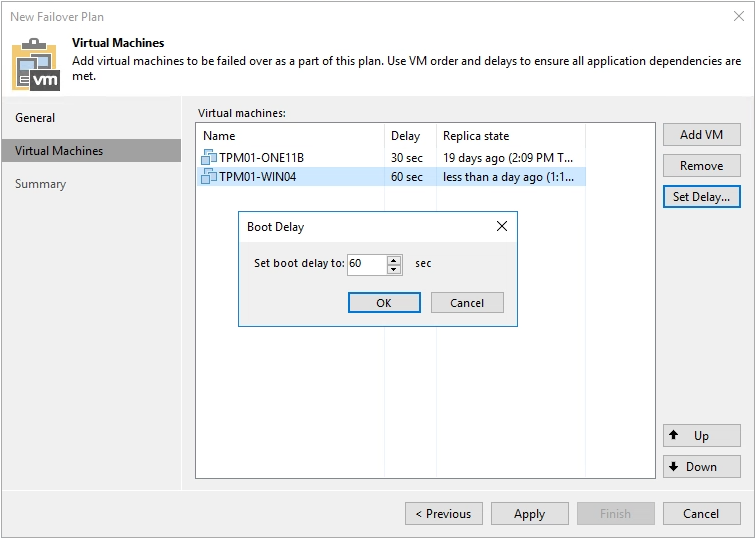
Using a failover plan is a temporary step, and would need to be finalized. For this you can either permanently failover, undo failover, or perform a failback.
Undo Failover
When you undo failover you switch back from the VM replica to the original VM. Undoing a failover can be an option when performing testing or troubleshooting.
If you decide to undo failover, the VM replica goes back to its original, pre-failover state. This means all the changes that occurred during the failover on the replica VM are discarded. The original VM resumes on the source host, and the replica remains intact and the jobs can continue to run. Since it discards the changes made when the replica is powered on, if done in an actual disaster scenario, this might not be the best option, as you could incur data loss.
Failback
Failback is performed when you want to shift operations back to the production VM from the VM replica. This is an option if your DR site cannot sustain the operations of the VM replica when it is powered on (and your production resources are now available). This ensures that the changes occurred during the time the VM replica is powered on, they are migrated to the original VM.
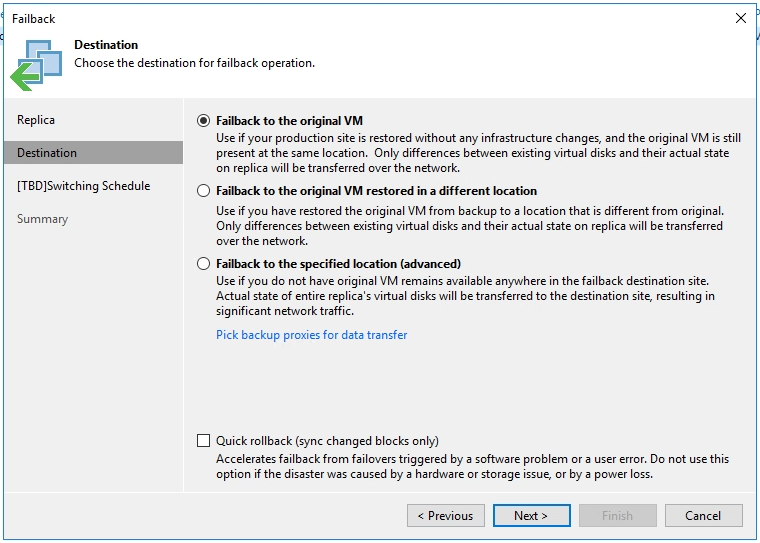
As you can see in the figure above, there are three failback options:
- Fail back to a VM in the original location on the source host
- Fail back to a VM that has been restored to a new location
- Fail back to an entirely new location
This should be followed by the commit failback operation. This ensures that all the changes that occurred while the VM was in the failover state are transferred back into the original machine.
When you commit failback, the original replication job remains intact. Especially when failing back to the original location, the replication job continues to process the VM normally. If you choose to fail back to a new location, Veeam Backup & Replication will reconfigure the replication job, adding the new VM from the new location and excluding the original VM.
Undo fail back should be considered if the original VM is not working or performing as expected after the failback operation. This will take you back to the VM replica and put that replica back into the failover state.
Planned Failover
Planned failover is an operation you use when you know that the production VMs are about to go offline. This is performed manually, and switches operations from the primary VM to its replica with minimal interruption. This can be done in a number of scenarios, including:
- If you know a disaster is coming and need to take the primary servers offline
- You’re planning a data center migration
- Maintenance or software updates need to be performed
To finalize planned failover, the options are the same; undoing failover, permanent failover, or failback.
Now you may be wondering, doesn’t Veeam provide a product that makes orchestrating failover plans even easier. That’s right, this is where Veeam Availability Orchestrator comes in.
BCDR planning made easy with Veeam Orchestrator
If you are not familiar with Veeam Orchestrator, it allows you to orchestrate DR processes in VMware vSphere environments. Orchestrator gives you the ability to create Replica Orchestration Plans to protect your machines and applications. DR Documentation is a capability of Orchestrator, giving summary information on the recovery process, check plan configuration, and obtaining the results of the plan testing and execution. Veeam Orchestrator can be very useful when it comes to disaster recovery.
For more helpful resources, I suggest the following:
- https://www.veeam.com/videos/perform-replication-failover-17402.html
- https://www.veeam.com/videos/dr-plan-missing-2021-17501.html
- https://vmiss.net/the-ultimate-guide-to-veeam-availability-orchestrator/
- https://www.veeam.com/blog/replicating-vmware-vms-with-veeam-everything-you-need-to-know-about-replica-failover.html



