
Policies in Veeam Kasten are at the heart of protecting and managing your Kubernetes workloads. They allow you to automate backups, snapshots, and exports to keep your data secure and recoverable. In this module, you’ll explore how to create and run policies and learn about Blueprints, advanced scheduling, policy presets, and manual actions, which are all essential for scalable and efficient data management.
Before exploring the specifics of creating and running policies, it's important to understand the foundational tools that make policies in Kasten flexible and scalable. One key tool is Blueprints, which enables tailored protection workflows for applications with unique requirements.
What are Blueprints?
Blueprints in Veeam Kasten are designed to provide tailored protection for workloads, ensuring that the specific needs of different applications are met during backup and recovery processes. Workloads refer to the applications or services running in a Kubernetes cluster. This could include databases, stateful applications, or microservices with complex dependencies. Each workload may have unique requirements for ensuring data consistency and integrity, especially during snapshot or backup operations. Blueprints address these needs by enabling administrators to integrate workload-specific behaviors into the data protection workflow.
By leveraging Blueprints, you can define how a workload is treated before and after snapshots are taken, ensuring that backups are consistent and recoverable. For example, a database workload might require a pre-snapshot action to pause transactions and flush in-memory data to disk to ensure the snapshot captures a consistent state. Similarly, a post-snapshot action can be configured to resume the database's activity after the snapshot is complete.
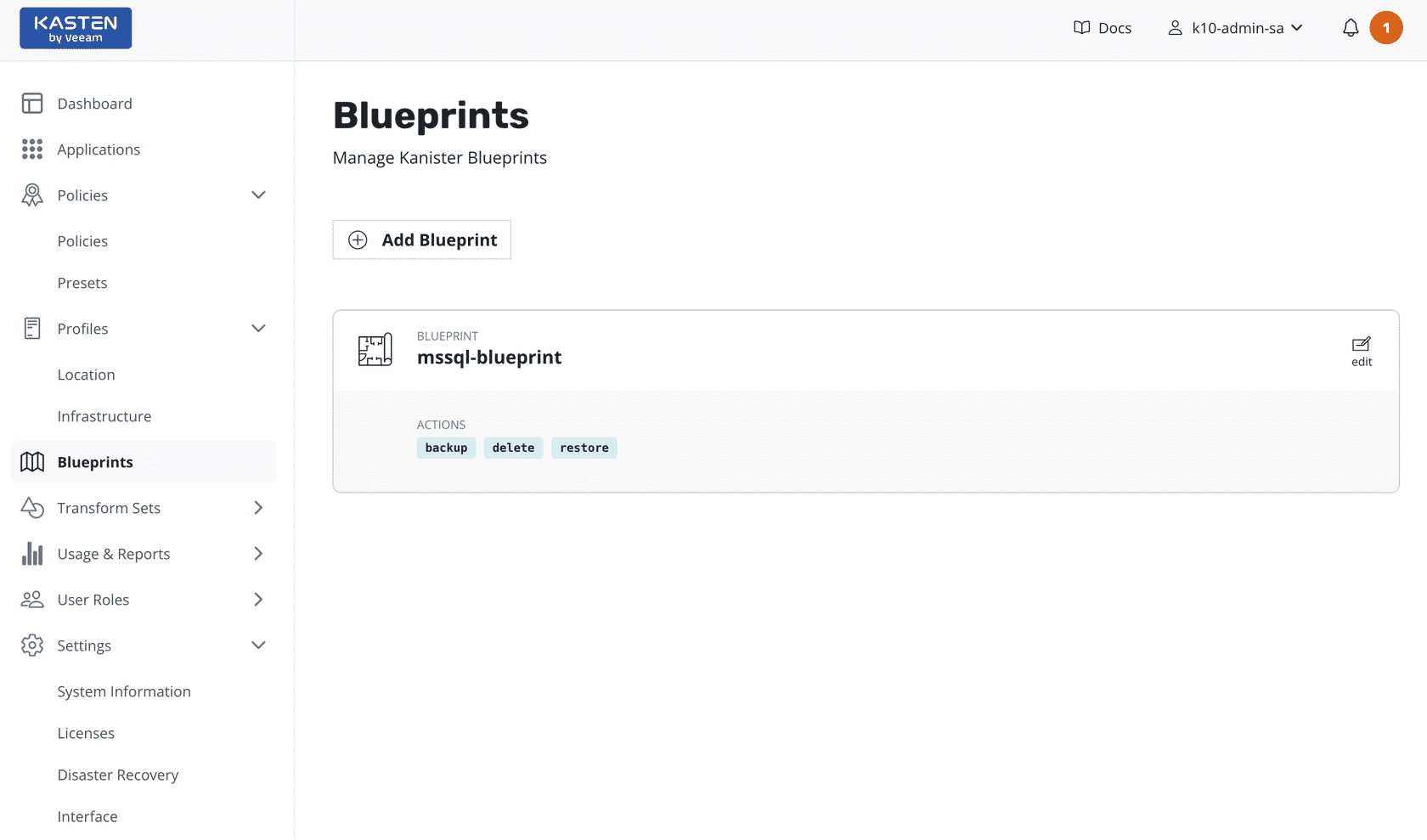
These pre- and post-snapshot commands, known as action hooks, are at the core of Blueprints and allow for fine-tuning of protection workflows based on the operational characteristics of each workload. This capability is critical for applications where default policies may not account for the intricacies of the workload, reducing the risk of data corruption and ensuring reliable recovery. Through Blueprints, Kasten provides a powerful mechanism for customizing policies to meet the diverse and complex requirements of Kubernetes workloads.
Advanced Scheduling for Kasten
Advanced scheduling in Veeam Kasten allows you to tailor protection workflows to meet your organization's specific needs, optimize resource usage, and align operations with Service Level Agreements (SLAs). With advanced scheduling, you can define specific intervals for backups, such as every hour, twice a day, or only on weekdays.
This level of customization can be useful for organizations with workloads with varied protection needs. For instance, a high-priority application may require frequent snapshots during business hours for rapid recovery, while less frequent daily backups are sufficient during off-hours. Advanced scheduling allows the implementation of such strategies, ensuring resources are used efficiently without compromising protection.
Optimizing Backup Operations with Advanced Scheduling
Step 1: Define Custom Schedules
Custom schedules ensure critical applications are frequently protected while lower-priority workloads are still backed up without unnecessary resource consumption. Tailor backup intervals to match your applications' criticality and activity. Use Kasten’s flexible scheduling options to set precise backup times.
How to Do It:
-
Create schedules that meet operational demands. Examples include:
-
Hourly snapshots for high-priority applications during business hours.
-
Nightly backups for less time-sensitive applications.
-
Weekly or monthly backups for long-term retention.
-
Step 2: Pair with Retention Policies
Pairing schedules with retention policies ensures a balance between meeting compliance needs and optimizing storage use, avoiding unnecessary costs. Combine your schedules with retention policies to determine how long snapshots and backups are stored.
How to Do It:
-
Configure retention rules that comply with your organization’s regulations or internal policies.
-
Examples:
-
Retain hourly snapshots for one day.
-
Keep daily backups for one week.
-
Archive weekly backups for six months to meet compliance requirements.
-
Step 3: Use Event-Based Triggers
Event-based triggers provide proactive protection for dynamic environments, ensuring that changes are always backed up and recoverable. Automate backups or snapshots based on specific events to ensure real-time protection.
How to Do It:
-
Set up triggers for application updates or deployments to capture the state of an application before and after changes.
-
Configure Kasten to perform a snapshot whenever an application is scaled or a significant configuration change occurs.
Step 4: Test and Optimize
Continuous optimization ensures that your backup strategy remains effective as your environment grows or changes, maintaining reliable protection without overburdening resources. Regularly test your advanced schedules to ensure they meet recovery objectives and operational requirements.
How to Do It:
-
Monitor resource usage during scheduled backups to ensure they don’t disrupt workloads.
-
Use metrics and reporting tools to identify bottlenecks and refine your schedules for efficiency.
Creating a Policy in Kasten
Policies in Veeam Kasten are the cornerstone of automated data protection and recovery within Kubernetes environments. They define the rules and actions for protecting your applications, including backup schedules, retention periods, and export configurations. By leveraging policies, you can standardize data protection across your workloads, ensuring consistency and compliance with organizational requirements.
Kasten policies work by integrating seamlessly with Kubernetes to identify, manage, and execute protection tasks. Once configured, policies automate processes like snapshots, exports to off-cluster storage, and application restores. They also provide flexibility through customization, allowing you to tailor schedules and settings to meet the unique needs of your workloads. This ensures operational simplicity while maintaining robust protection for critical applications.
What about policy presets?
Operations teams can define multiple protection policy presets (specifying schedule, retention, location, and infrastructure). A catalog of organizational policy presets and SLAs can then be provided to the development teams with an intimate knowledge of application requirements without disclosing credential and storage infrastructure implementation. This ensures the separation of concerns while scaling operations in a cloud-native environment.
For example:
An operations team might create a policy preset for high-priority workloads that require daily backups retained for seven days and weekly snapshots archived for six months in a secure object storage location. Another preset might cater to less critical applications, specifying backups every three days with a one-month retention period.
A development team working on a new application could then select the high-priority preset for their production environment to ensure compliance with organizational SLAs while using the lower-priority preset for staging or testing environments.
This division of responsibilities allows organizations to scale their cloud-native operations efficiently. It ensures that every team has the tools they need to protect their applications while maintaining consistent security and operational practices across the organization.
Restoring and Migrating Applications
After applications have been protected through a policy or manual action, you can restore them in-place or clone them into a different namespace. Restoring applications can be necessary in situations such as recovering from accidental data loss, system failures, or corruption that may have occurred. You can also use application restores for testing and development purposes, where a cloned environment in a separate namespace can replicate the production application without affecting live operations.
Handling Application Migration with Kasten
The ability to move an application across clusters is an extremely powerful feature that enables a variety of use cases, including Disaster Recovery (DR), Test/Development with realistic data sets, and performance testing in isolated environments. This feature provides flexibility in managing applications across multiple Kubernetes clusters, ensuring operational continuity and scalability.
One of Kasten's most powerful features is the ability to move an application across clusters, enabling various critical use cases. It supports disaster recovery by restoring applications in a different cluster after a failure, ensuring operational continuity. For test and development purposes, it allows users to clone applications with realistic data sets, creating accurate testing environments. Additionally, it facilitates performance testing in isolated environments, enabling thorough evaluations without impacting production systems.
Let’s explore the key components of application migration, including Import, Import + Restore, and Transforms.
| Import | Importing enables you to bring data or applications from external clusters or backups into the current cluster. This is critical for setting up new clusters, transferring workloads between regions, or initializing environments. This ensures data consistency and availability when transitioning between clusters. Example Use Case: |
| Import + Restore | It combines importing external data and restoring the target cluster's full application state. This is particularly valuable for disaster recovery, enabling complete application recovery after importing backup data. Ensures operational continuity by bringing applications back online quickly and effectively. Example Use Case: |
| Transform | Transforms allow you to modify application data during migration or restoration, tailoring it for the new environment. They are ideal for adapting applications to different environments for testing or updating configurations to meet specific cluster requirements. Transforms ensure the migrated application is fully optimized and ready to operate in its new environment. Example Use Case: |
With features like Import, Import + Restore, and Transforms, Kasten provides a seamless and flexible solution for moving applications across clusters. Whether for disaster recovery, testing, or scaling, these capabilities ensure operational efficiency and data integrity during migrations.