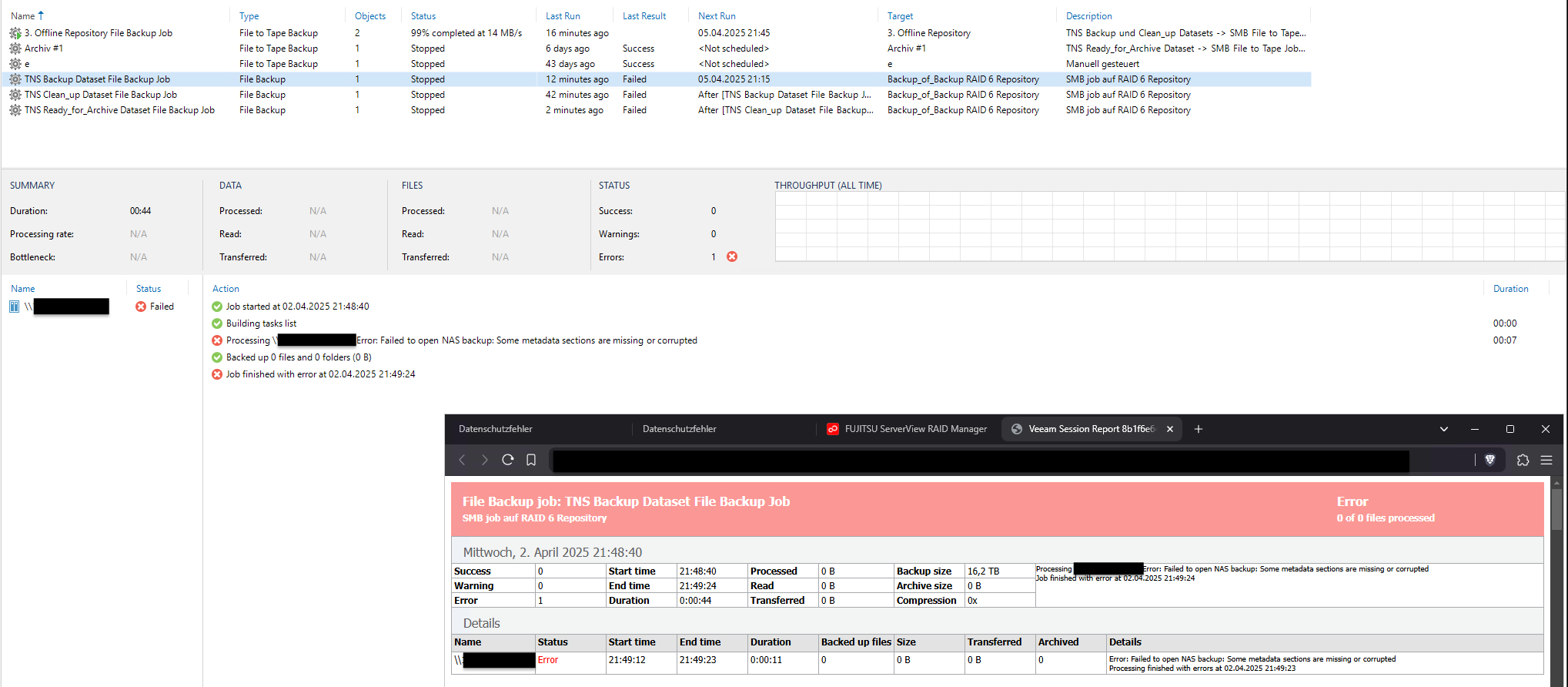
I don’t know what to do anymore, perhaps somebody knows to help.
There were a minor problem on the local target RAID6, which was solved by the RAID controllers patrol read.
Before i noticed the issue the 3 chained B2D job were already running, failing and stopping. I remember hard stopping one because it was hanging in infinite loops.
From that time i was trying since a few days now to get those 3 chained B2D jobs running again.
But doesn’t matter what i do, if i try to run the job(s), run a health check, try to use the repair option which is given for the 1st of the chained group, if i try to disable the job and try all again…. it always ends very fast with the error:”Some metadata sections are missing or corrupted”.
It’s the same on all 3 jobs in the chained B2D group.
The source isn’t the problem, cause a backup to tape job running without any issue.
From my understanding since i didn’t find any other repair option in Veeam, the only route left is to delete and loose all restore points in this chained B2D group, or did i miss something?