

Something New!
I am creating a new series of blog posts with the goal of highlighting a feature or capability that one of our object storage partners has which can benefit the Veeam community. I will continue to publish new blogs as part of my ongoing Veeam Amazing Object Storage Tips & Techniques, which will focus on non-vendor specific topics.
Optimizing OSNEXUS QuantaStor for use with Veeam
Storage Class Auto-Tiering Rule:
When Veeam Backup & Replication (VBR) v9.5.4 added the S3 compatible object storage backed Capacity Tier to its Scale-Out Backup Repository (SOBR) back in January of 2019, it was the start of my object storage journey within Veeam. During this 5 ½ year journey I have had the opportunity to work with many of our object storage partners and I have witnessed the work they have done to enable their object storage to work more efficiently with VBR and Veeam Backup for Microsoft 365 (VB365).
One of those object storage partners, OSNEXUS, recently released version 6.4 of their QuantaStor object storage. Within this latest version of QuantaStor, OSNEXUS has introduced a new performance feature Storage Class Auto-Tiering Rules which greatly improves the performance of QuantaStor when used with Veeam’s VBR. This performance increase is achieved by QuantaStor as it dynamically assigns Veeam objects during the S3 PUT to place objects into different Storage Classes (data pools) based on criteria like object size.
Traditionally there are three methods to protect data when it is written to object storage, Erasure coding, RAID, and Replication. Note:Some will argue RAID1 = Replication, but that is a possible topic of a future blog. Each has its own benefits and drawbacks.
There are many great resources that you can use to get a deep dive understanding of these data protection methods. For the purpose of this blog, I will give you a quick intro to Erasure Coding and Replication (Replica3 specifically).
What is Replica3? The name sort of gives it away. You simply make 2 replicas of the original object so that you now have 3 copies. The Replication data protection method when using Replica3 allows you to lose 2 copies of the object and still have 1 intact copy of the object. The main drawback to this data protection method is it requires more space compared to Erasure Coding. For example, if you had a 1GB object that you were to apply Replica3 to you would end up using 3GB of storage.
What is Erasure Coding? It actually has been around since the 1960s and has been used in satellite communication, aerospace, Blu-ray discs, and QR codes. From an object storage perspective, erasure coding is a data protection method. The protection is achieved by first dividing an object into smaller fragments. Then those smaller fragments are encoded with parity data. The encoded fragments are then distributed across multiple nodes and/or disks to ensure that the original data can be recovered even if some of the encoded fragments, disks, or even nodes are lost or corrupted. Erasure coding (EC) and RAID are both based on the Reed-Solomon algorithm but systems using EC are generally distributing the data and protective coding blocks across many systems (servers) in a scale-out architecture.
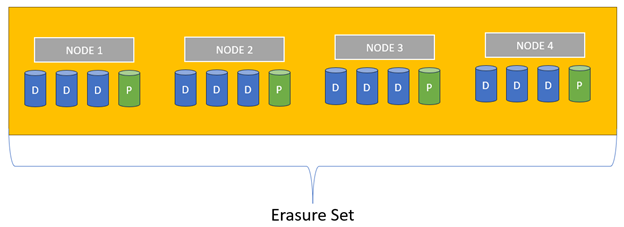
For example, let’s say I have 4 nodes each with 5 disks giving us a total of 20 disks:

Now if we add Erasure Coding to protect the data we now have what is called an Erasure Set. In this example we have 16 Data disks + 4 Parity disks and is referred to as EC16+4. This allows us to lose up to 4 disks or a complete node before any data is lost. Here is what the previous diagram looks like after erasure coding is applied:
To calculate the storage consumed by an object using Erasure Coding you need to use this formula:
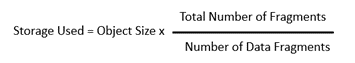
In our example of a 1GB object using EC16+4 the total amount of storage required is:
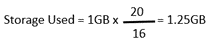
When compared to the 3GB storage required for Replica3, Erasure Coding saves us over 58% in storage required while also providing twice the data protection of handling the loss of 4 copies vs just 2.
One drawback of using Erasure Coding (EC) is when you have a large number of small objects that when fragmented result in fragments that are smaller than the block size of the disk used for the object storage. This can lead to wasted space and I will explain that soon.
First let’s calculate the size of the fragment for the EC16+4 example. In this case we will use the Veeam Backup & Replication best practice object size of 1MB.
The formula is:
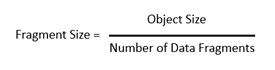
Using the 1MB object size we get:
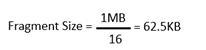
Assuming the object storage disks are formatted with a 4KB block size, there isn’t going to be an issue. But object written by VBR typically are smaller than the 1MB setting due to compression and deduplication. Using the same formula we can calculate that a resulting 4KB EC fragment will created when the original object is 64KB in size. So any object less than 64KB in size will result in data fragments less than 4KB in size. When writing those smaller fragments to the disk using the formatted 4KB block size, you will be wasting space. For example if the fragments are 2KB in size, then the 4KB block written to disk will have 50% whitespace resulting in 50% wasted space (also referred to as padding). Additionally these extremely small fragments can negatively effect performance of the Erasure Coding due to the increased metadata overhead. Also, the smaller fragments can negatively impact network bandwidth usage die the increased number of network requests.
With QuantaStor 6.4 you can create a Storage Class Auto-Tiering Rule that will determine based on object size whether to use EC or Replication. For VBR this is done by creating two storage classes STANDARD and STANDARD_IA. The STANDARD class is configured to use Replica=3 (triple mirroring) and the STANDARD_IA is configured to use Erasure Coding such as 8k+3m or 16k+4m as in the example above.
Within the Storage Class Auto-Tiering rule, the recommended Capacity Threshold for directing a given object to the EC storage tier is 64 KiB for VBR workloads. This is based on the math done above:
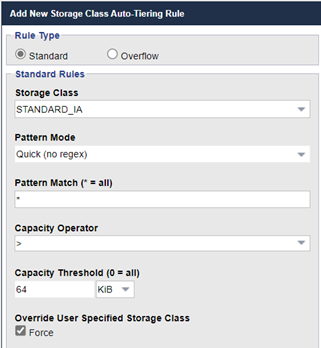
By using this Storage Class Auto-Tiering rule, any objects that would result in fragments being less than 4KB are going to use Replica3 storage (ideally all-flash) instead of Erasure Coding. This division of labor where the all-flash replica=3 storage covers our small objects and the lower cost EC storage covers our larger objects is really ideal and makes a huge difference in the overall performance of your backup infrastructure. OSNEXUS customers consistently report that they see a 5x performance increase int their write IOPS, significantly reducing the time required to backup or offload backup data to the QuantaStor backed VBR repositories.
Hopefully you can see where OSNEXUS’s implementation of the Storage Class Auto-Tiering rules can help with both increasing performance and storage utilization when using QuantaStor with Veeam Backup & Replication. If so, the following section will help you setup your QuantaStor to work with VBR and VB365.
QuantaStor Setup for Veeam:
The following takes you through the basic setup of QuantaStor with an auto-tiering rule to optimize performance with Veeam. The first thing we will do is create an object storage group which forms our S3 object storage zone and our initial replica=3 data pool which we’ll use for all the small objects:
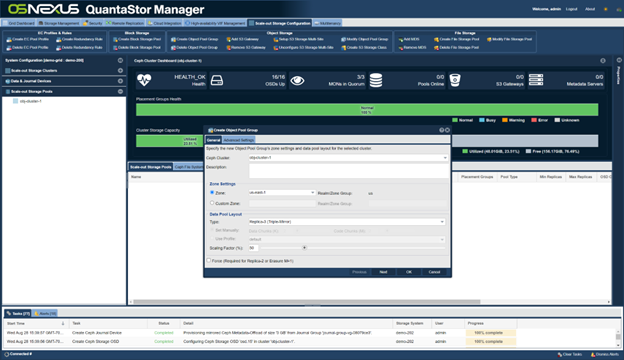
We will set the zone name of “us-east-1” since it is the S3 default:
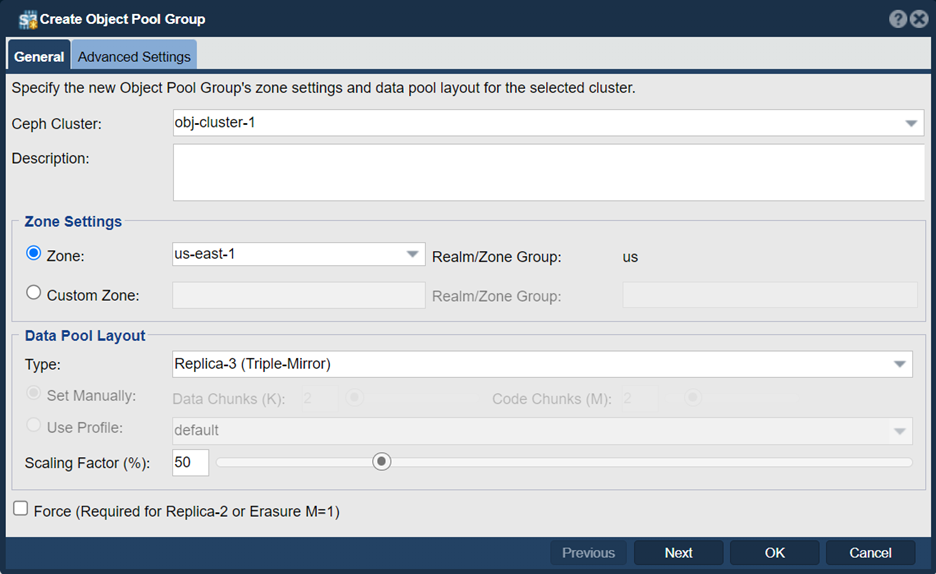
Now that our zone is created we need to activate S3 gateways on all the nodes and the built-in load balancer which is done with this “Add S3 Gateway” dialog:
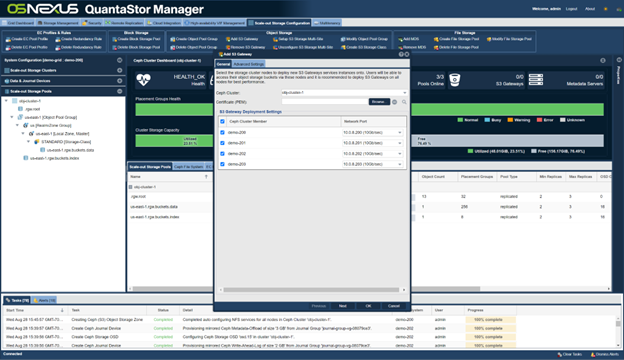
Now that we have our object storage zone setup with a default replica=3 storage class of “STANDARD” we need to add the EC storage class which we’ll call “STANDARD_IA”. This is done via the “Create S3 Storage Class” dialog:
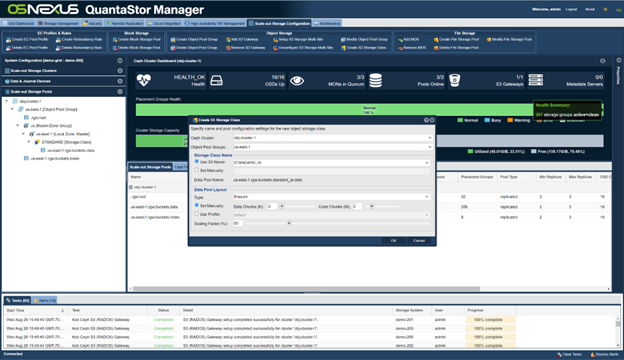
After that you’ll see both STANDARD and STANDARD_IA storage classes listed in the pools section:

Now we’re ready to optimize things for Veeam by adding a simple rule here to route all objects greater than 64K to our erasure-coded storage tier which is STANDARD_IA:
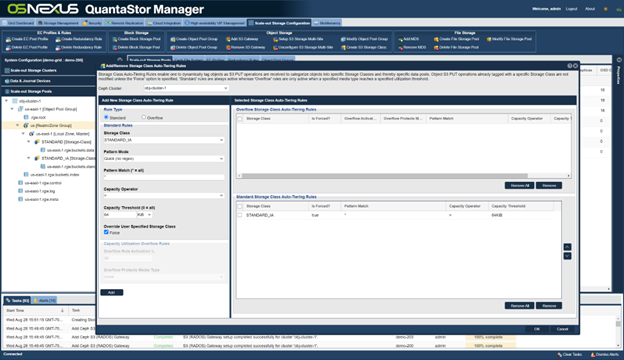
Note how we’re using the “Force” option. VBR uses the “STANDARD” storage class for all S3 PUT operations and by enabling the “Force” option QuantaStor will PUT the objects using the “STANDARD_IA” storage class. This won’t interfere with any VBR operations because when VBR performs any S3 operations on the objects, QuantaStor will return the object to VBR with the “STANDARD” storage class.
Now the object storage zone is setup, optimized and ready to go. So now we need to create a S3 user account and a S3 bucket so we can start doing backups to it. Here we’re creating a S3 user account and for this just enter a user name and press OK:
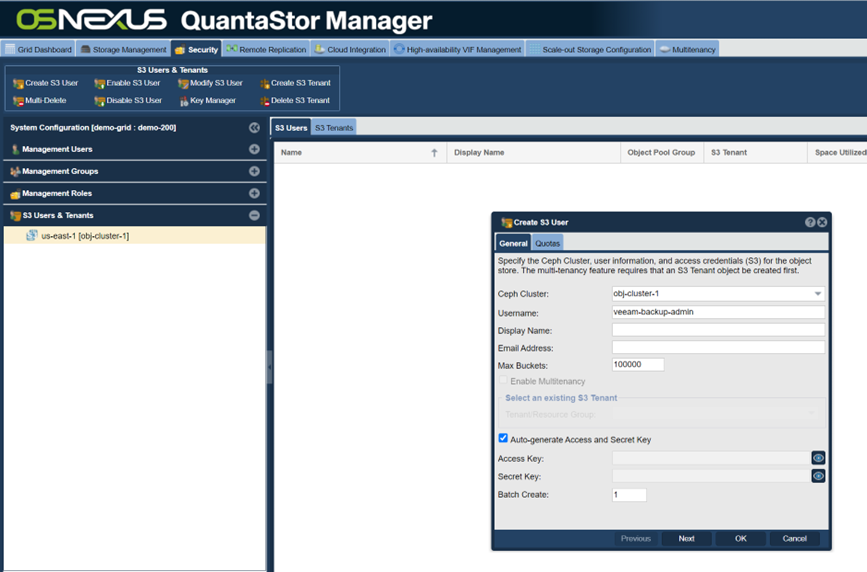
Now that we have our S3 user “veeam-backup-admin” we can now create a S3 bucket for our backups which we’ll call “veeam-backups”. VBR can generate many objects depending on your workloads. To prepare for this we are pre-estimating the bucket size at 100M+ objects. QuantaStor can scale to billions of objects, but by pre-sizing the bucket we’ll reduce the amount of work QuantaStor would normally need to do on the fly and this will improve the QuantaStor performance.
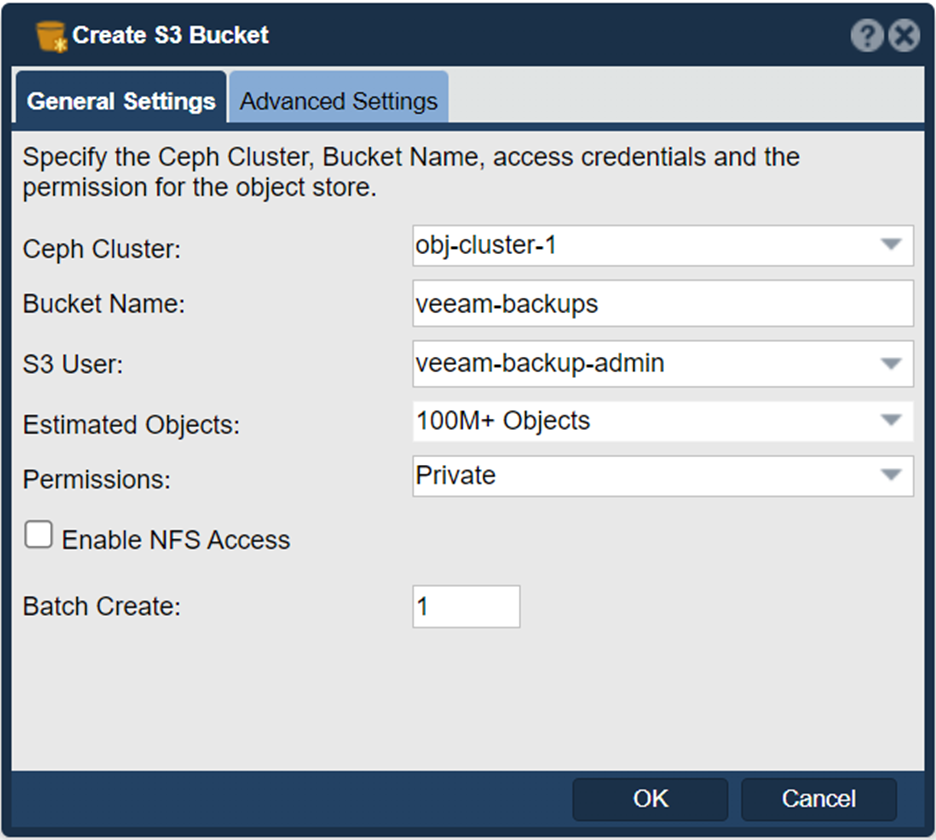
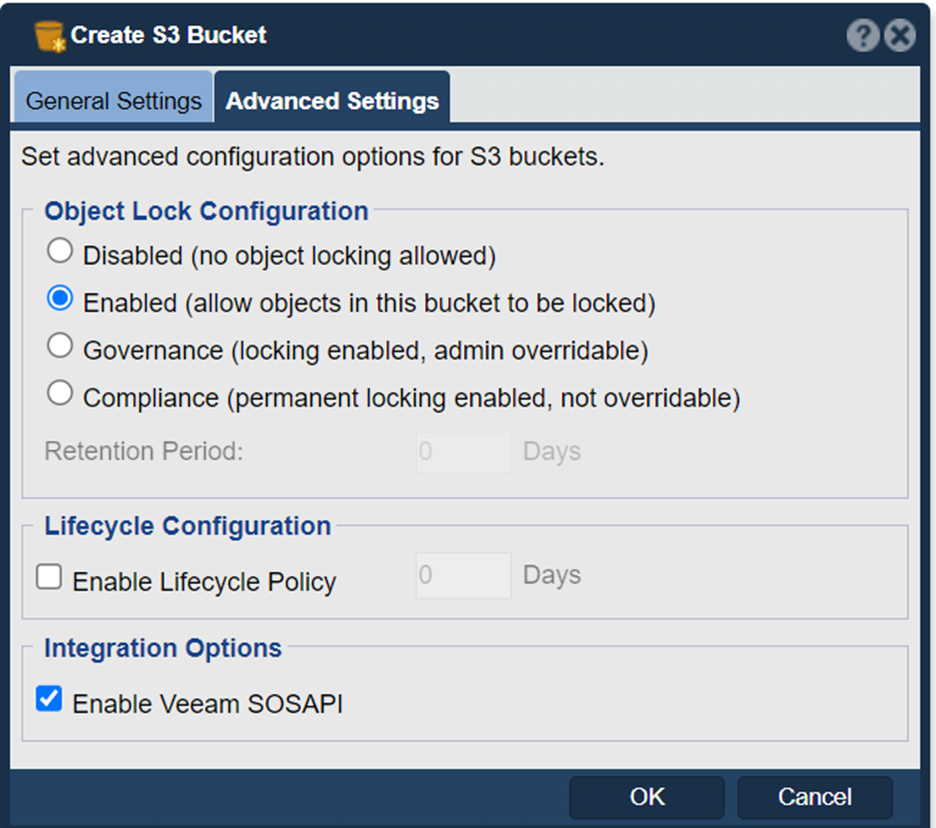
Before you press OK and create the bucket, go to the Advanced Settings page and “Enable Veeam SOSAPI”. This tells QuantaStor to communicate with Veeam via the SOSAPI to let it know things like how much QuantaStor free space is available.
You can add layer of protection against ransomware and other cyberattacks by enabling immutabilty. This is done by setting the Object Locking to ‘Enabled’ so that VBR is able to lock objects:
You need to capture the S3 credentionals when creating the object storage repository within VBR or VB365. To do this right-click on the S3 user account and choose “View S3 User Access Keys” from the menu:
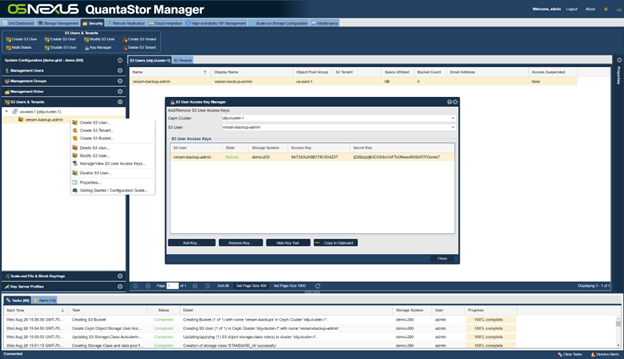
At this point the QuantaStor S3 object storage is accessible to VBR/VB365 using HTTPS via port 8580. For instructions on how to configure HTTPS on the QuantaStor as well as a full guide of how to set up QuantaStor to work with VBR/VB365, please checkout this comprehensive Veeam Deployment guide.
For any questions on getting your own QuantaStor object storage zone setup for Veeam you can contact veeam@osnexus.com for more information.
I hope you find this new alliance partner content valuable and I look forward as always to your feedback and comments.