Block Sizes
As can be seen from the field, optimal value for the stripe size is often between 128 KB and 256 KB. However, it is highly recommended to test this prior to deployment whenever possible.
During the backup process data blocks are processed in chunks and stored inside backup files in the backup repository. You can customize the block size during the Job Configuration using the Storage Optimization setting of the backup job.
By default Veeam’s block size is set to Local Target, which is 1 MB before compression. Since compression ratio is very often around 2x, with this block size Veeam will write around 512 KB or less to the repository per Veeam block.
This value can be used to better configure storage arrays; especially low-end storage systems can greatly benefit from an optimized stripe size.
There are three layers where the block size can be configured: Veeam block size for the backup files, the filesystem, and the storage volumes.
Let’s use a quick example: 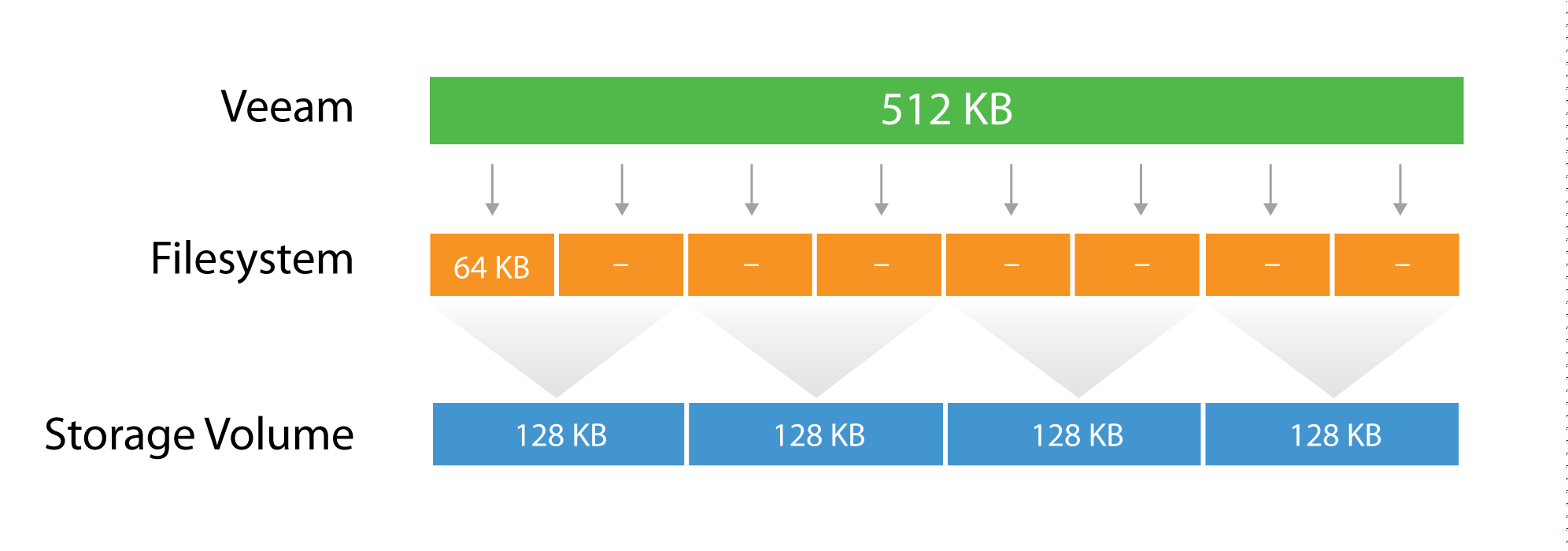
The Veeam block size (after compression) of 512KB is going to be written in the underlying filesytem, which has a block size of 64k. It means that one block will consume 8 blocks at the filesytem level, but no block will be wasted, as the two are aligned. If possible, set the block size at the filesytem layer as close as possible to the expected Veeam block size.
Then, below the filesytem there is the storage array. Even on some low-end storage systems, the block size (also called stripe size) can be configured. If possible, again, set the stripe size as close as possible to the expected Veeam block size. It’s important that each layer is aligned with the others, either by using the same value (if possible) or a value that is a division of the bigger one. This limits to a minimum the so called write overhead: with a 128KB block size at the storage layer, a Veeam block requires 4 I/O operations to be written. This is a 2x improvement compared for example with a 64KB stripe size.
Volume Sizes
In general we recommend to not size volumes larger than 200TB.
This helps keeping failure domains small and managable. To go for bigger repositories we recommend using a Scale-Out Backup Repository with multiple extents.
RAID Controller Caching
To get the best out of a synthetic backup and enhance the performance, it is recommended to use a write-back cache. Read and write request processing with write-back cache utilization is shown in the figure below. 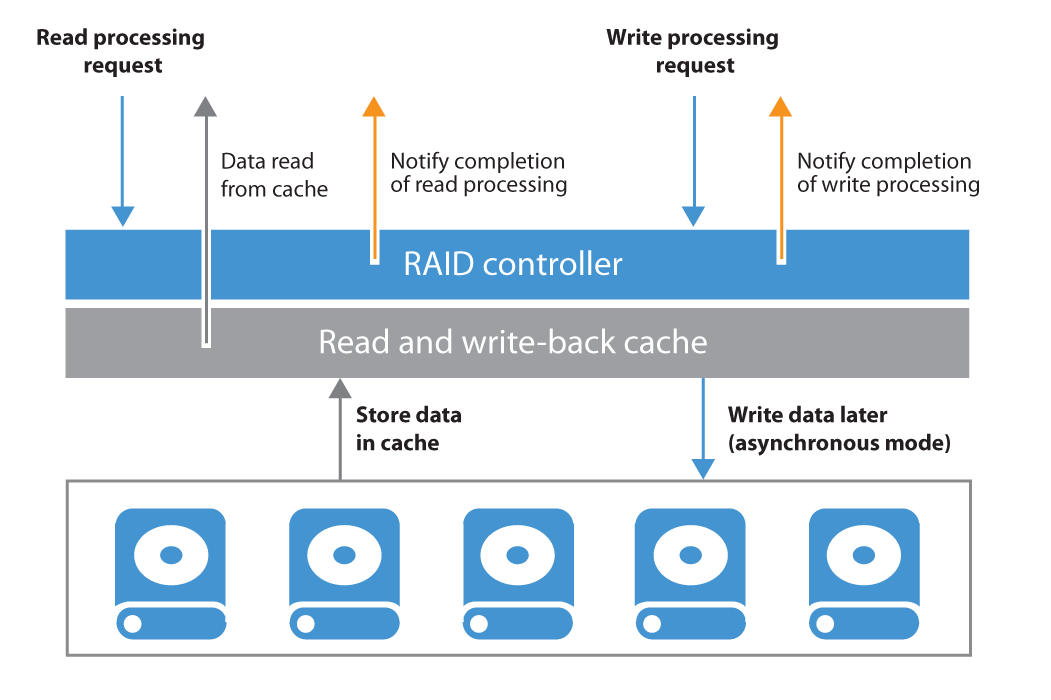
Windows or Linux?
There are only small differences between Linux and Windows which result from using different schedulers for I/O and compute. The main difference for block-based repositories is the choice of available file systems.
NTFS or ReFS?
You can use both Microsoft filesystems for a Veeam Repository. Both have advantages and disadvantages during different backup situations.
ReFS allows to use the Veeam Fast Clone feature which allows very fast synthetic operations for full backups and merges.
On the downside this can result in random I/O, e.g. when reading a synthetic full backup file because the data blocks are distributed over the disk. Random I/O profiles on spinning disks will be much slower than sequential I/O. That way, e.g. a full VM restore from a full backup file might be slower from ReFS than from NTFS when using the same disk layout.
To work around this fragmentation you can schedule regular active full backups, but they will require 100% space on the disk compared to synthethic fulls which just take the additional space of an incremental backup.
NTFS
When using NTFS please make sure that
- the volume is formatted with 64KB block size
- you use the “Large File” switch
/Lto format the volume to avoid file size limits
The following command will quick format volume D accordingly:
format D: /FS:NTFS /L /A:64K /Q
ReFS
ReFS is using linked clone technology. This is perfect for synthetic operations and will save dramatic IOs and throughput during operations like merges or creating synthetic fulls.
Follow these best practices when using ReFS:
- Format the volume with 64KB block size
- Configure 256 KB block size on LUNs (Storage or RAID controller)
- Never bring linked clone space savings into your calculation for required storage space
- “All ReFS supported configurations must use Windows Server Catalog certified hardware” - please contact your hardware vendor
- Never use any shared LUN concept with ReFS and a Veeam Repository
- Check the existing driver version of ReFS. The minimum should be
ReFS.sys 10.0.14393.2097 - ReFS will flush metadata during synthetic processes to the disk very pushy. These meta data flushes are based on 4KB blocks. Your controller and disk system should be able to handle these OS related system behaviours.
Windows Server Deduplication
Deduplication will take away some of the benefits of block storage repositories but provides efficient use of disk resources.
Follow the recommendations provided in the configuration guidelines above; here is the summary:
- Use the latest Windows version or at minimum Windows 2012 R2 and apply all patches (some roll-ups contain improvements to deduplication). Having most up to date system is critical for ensuring data safety.
- Format the disk using the command line
/Loption (for “large size file records”) and 64KB cluster size (use parameters/Q /L /A:64K) - (For Windows Server 2016 and later) the “Virtualized Backup Server” deduplication profile is to be preferred
- Modify garbage collection schedule to run daily rather than weekly.
- Use backup jobs configured to perform Active full with Incrementals.
- If possible, spread active full backups over the entire week.
- For WS2016 deduplication is “fully supported” for files up to 1TB which is not recommended (supported?) for WS2012. In WS2019 dedup is supported for ReFS but will only dedup the first 4TB of a file.
- Large files take a long time to deduplicate and will have to be fully reprocessed if the process is interrupted.
- Where possible, use multiple volumes. Windows deduplication can process multiple volumes using multi-core CPU – one CPU core per volume.
- Configure deduplication process to run once a day, and for as long as possible.