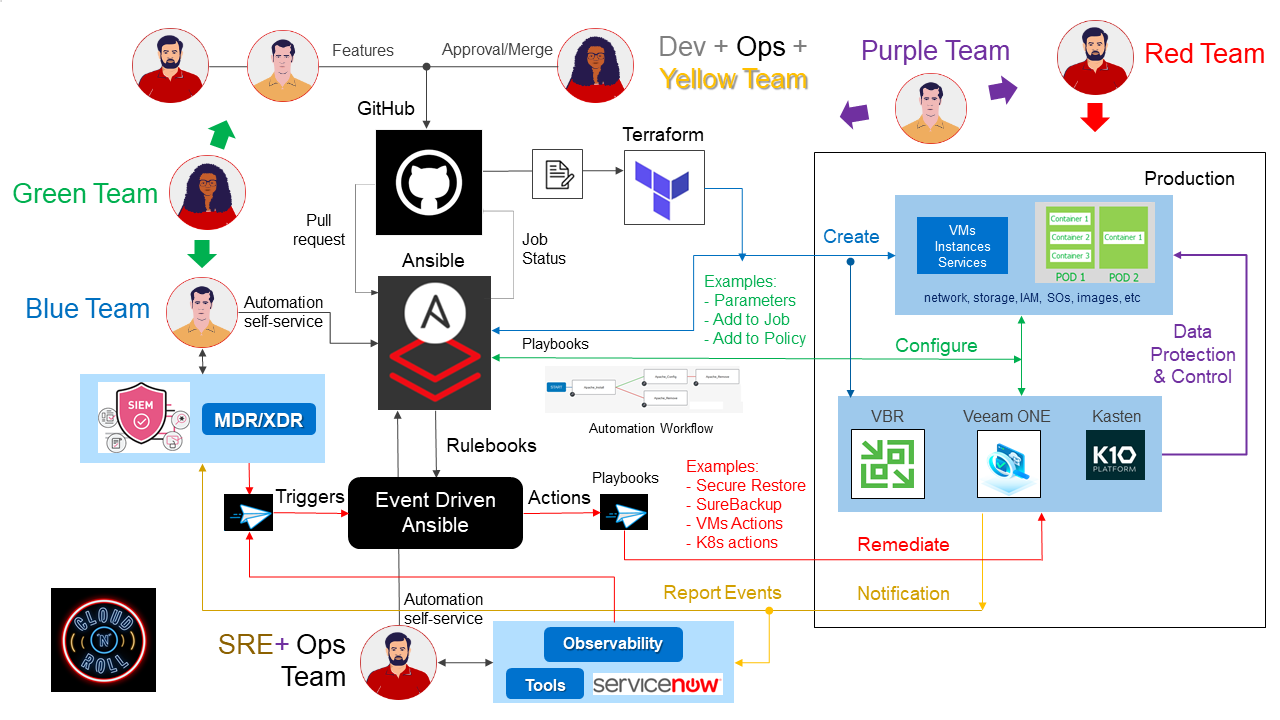
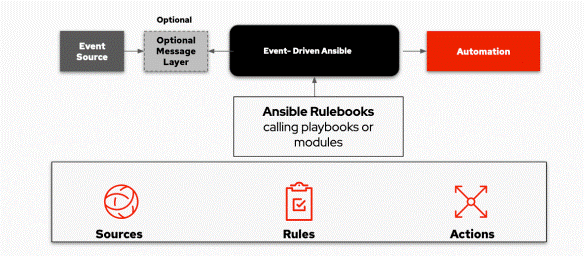
Hello Veeam Community!
As you might know if you’ve seen other topics and articles from me, I am a big proponent of using Infrastructure as Code (IaC) tools to manage resource and application configuration. Several exciting developments in this space have occurred in the past few months, and I thought it would be good to start off this week by asking you:
How are you using Infrastructure as Code tools and principles to manage data protection operations in your organization?
I’m curious to hear what problems you’re solving today using IaC, as well as your own roadmaps, wishlists, and barriers to adopting IaC.
Sound off in the comments, and have a great week!