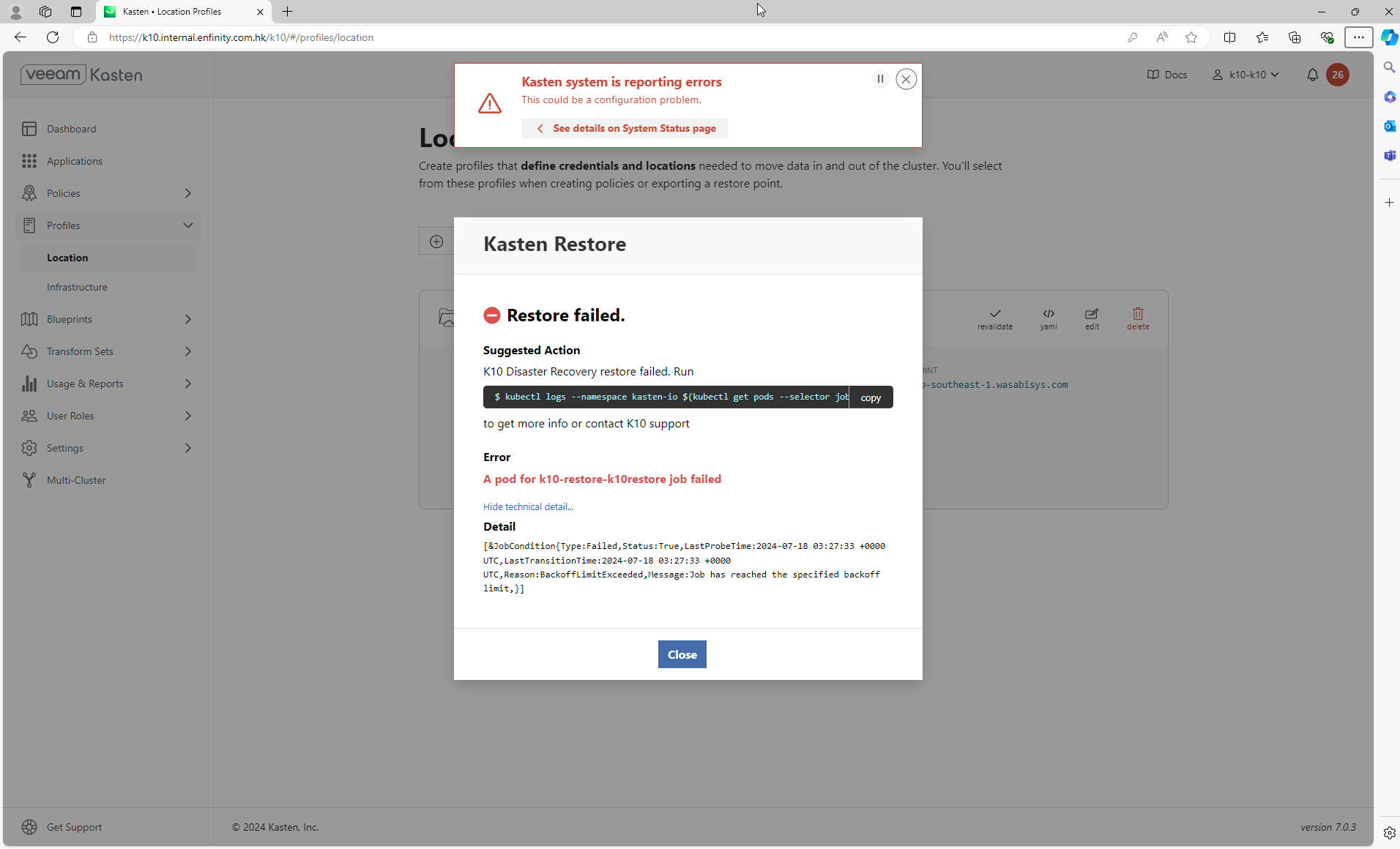
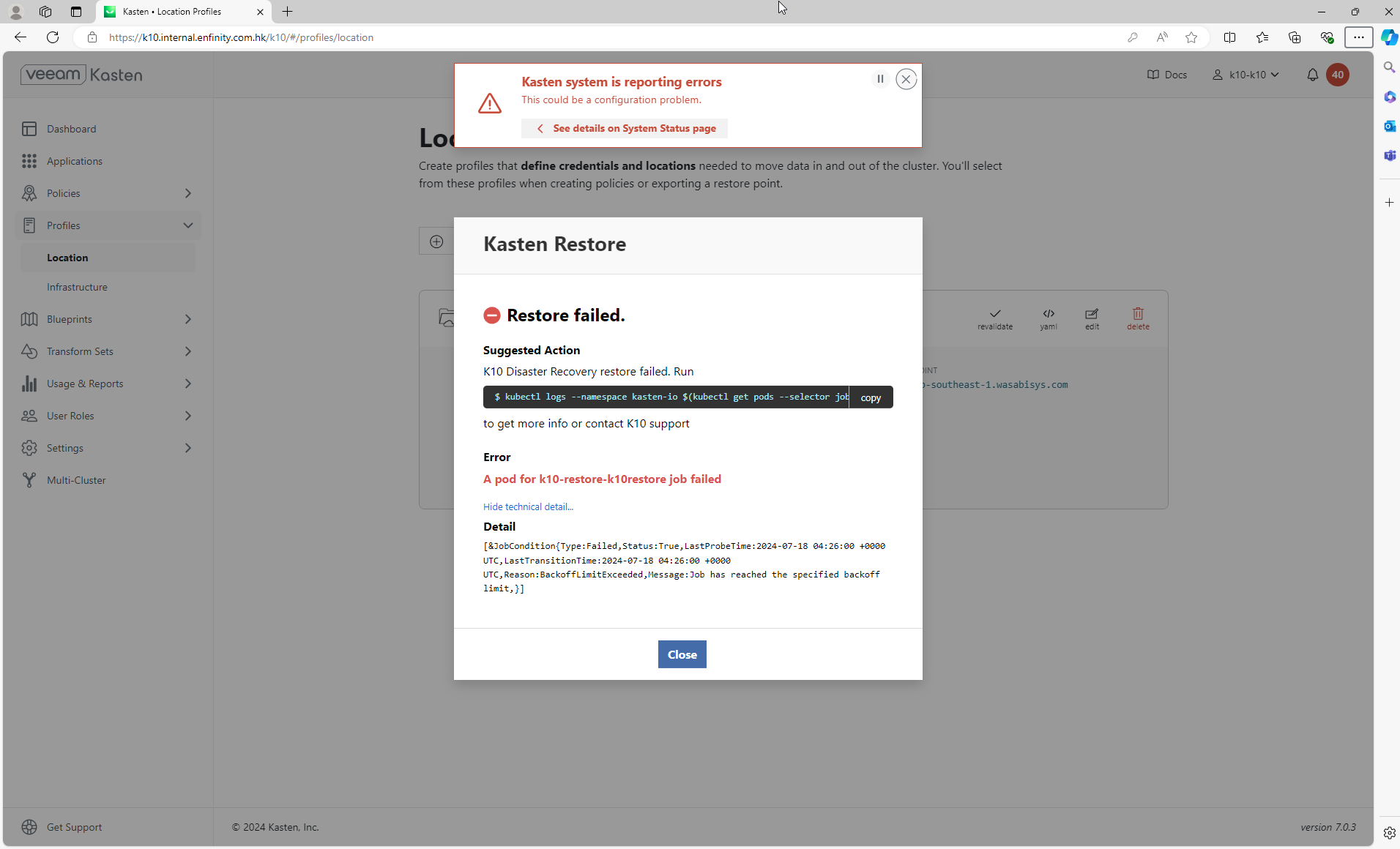
This morning we received an alert that our Kasten backups were failing on our production Rancher RKE2 cluster (version v1.30.2+rke2r1). In particular, when attempting to snapshot application components and configuration, we encountered the error “Could not encrypt data”.
We are using K10 version 7.0.4 which was updated automatically a few days ago via GitOps with Flux v2, though the error only started occurring this morning.
By inspecting the pods in the kasten-io namespace, we noticed that the crypto-svc pod is stuck in CrashLoopBackOff - all other pods are running normally:
NAME READY STATUS RESTARTS AGE
crypto-svc-6f78dcf599-xhrgp 3/4 CrashLoopBackOff 6 (118s ago) 7m57s
Describing the pod revealed that the failed container is bloblifecyclemanager-svc.
8m53s Normal Pulling pod/crypto-svc-6f78dcf599-xhrgp Pulling image "gcr.io/kasten-images/bloblifecyclemanager:7.0.4"
9m15s Normal Pulled pod/crypto-svc-6f78dcf599-xhrgp Successfully pulled image "gcr.io/kasten-images/bloblifecyclemanager:7.0.4" in 307ms (307ms including waiting). Image size: 112468707 bytes.
9m13s Normal Created pod/crypto-svc-6f78dcf599-xhrgp Created container bloblifecyclemanager-svc
9m12s Normal Started pod/crypto-svc-6f78dcf599-xhrgp Started container bloblifecyclemanager-svc
9m13s Normal Pulled pod/crypto-svc-6f78dcf599-xhrgp Successfully pulled image "gcr.io/kasten-images/bloblifecyclemanager:7.0.4" in 242ms (243ms including waiting). Image size: 112468707 bytes.
4m11s Warning BackOff pod/crypto-svc-6f78dcf599-xhrgp Back-off restarting failed container bloblifecyclemanager-svc in pod crypto-svc-6f78dcf599-xhrgp_kasten-io(d9b7bb69-b48d-49ca-996e-374479e7679e)
Inspecting the container logs for bloblifecyclemanager-svc in the crypto-svc pod reveals a program panic due to a nil pointer dereference.
...
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x2c5905f]
goroutine 151 [running]:
kasten.io/k10/kio/bloblifecycle/s3client.(*Store).GetBlobRetention(0xc0000c3808?, {0x54f4a50?, 0xc002724180?}, {0xc002caa710, 0x10}, {0xc0030fc210?, 0xc001755318?}, {0xc002aee980?, 0x53a26d?})
kasten.io/k10/kio/bloblifecycle/s3client/lifecycler.go:108 +0x93f
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).getBlobRetention.func1({0x54f4a50?, 0xc002724180?})
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:932 +0x63
kasten.io/k10/kio/poll.waitWithBackoffWithRetriesHelper({0x54f4a50, 0xc002724180}, {0x0, 0x0, 0x0, 0x0, 0x0}, 0x5, 0x4cba8d8, 0xc000087770)
kasten.io/k10/kio/poll/poll.go:99 +0x210
kasten.io/k10/kio/poll.waitWithBackoffWithRetries({0x54f4a50, 0xc002724180}, {0x0, 0x0, 0x0, 0x0, 0x0}, 0x5, 0x4cba8d8, 0xc000087770)
kasten.io/k10/kio/poll/poll.go:83 +0xde
kasten.io/k10/kio/poll.WaitWithRetries(...)
kasten.io/k10/kio/poll/poll.go:64
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).getBlobRetention(0xc001413200?, {0x54f4a50?, 0xc002724180?}, {0xc002caa710?, 0x70?}, {0xc0030fc210?, 0xc000087850?}, {0xc002aee980?, 0x73bbaffff9f8?})
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:930 +0xe5
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).preserveSingleBlobVersion(0xc001413200, {0x54f4a50, 0xc002724180}, 0xc0035185c0, {0xc002aee980, 0x20})
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:683 +0x6d
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).manageBlobVersions(0xc002caa710?, {0x54f4a50?, 0xc002724180?}, 0xc0035185c0)
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:513 +0x145
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).manageBlobsInRepo(0xc001413200, {0x54f4a50, 0xc002724180})
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:305 +0x2c9
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).initAndManageBlobsInRepo(0xc001413200, {0x54f4a50, 0xc002724180})
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:278 +0x66
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).manageBlobsInRepoCountActive(0xc001413200, {0x54f4a50, 0xc002724180})
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:269 +0xa5
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).manageBlobsInRepoThrottled(0xc001413200, {0x54f4a50, 0xc002724180}, 0xc0000f47e0)
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:247 +0x93
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).manageBlobsInRepoWithDurationCheck(0xc001413200, {0x54f4a50, 0xc002724180}, 0xc0000f47e0)
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:207 +0xc9
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).runRefreshCycle(0xc001413200, {0x54f4a50?, 0xc002724180?}, 0x0?)
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:143 +0x25
kasten.io/k10/kio/bloblifecycle/lifecycle.(*repoBlobExtender).run(0xc001413200, {0x54f4a50, 0xc002724180}, 0xc0000f47e0)
kasten.io/k10/kio/bloblifecycle/lifecycle/repo_extender.go:133 +0xa5
kasten.io/k10/kio/bloblifecycle/lifecycle.(*Manager).runRepoExtender.func1()
kasten.io/k10/kio/bloblifecycle/lifecycle/manager.go:374 +0x7a
created by kasten.io/k10/kio/bloblifecycle/lifecycle.(*Manager).runRepoExtender in goroutine 113
kasten.io/k10/kio/bloblifecycle/lifecycle/manager.go:368 +0x138
The full logs are attached as k10-7.0.4-crypto-svc-bloblifecyclemanager-full-log.txt for reference.
We also tried the following to no avail - the blob lifecycle manager continues to fail due to the same nil pointer dereference:
- Killing the
crypto-svcpod to have it re-created - Downgrading the Helm chart to K10 7.0.3 (logs attached as well)
We haven’t observed the same issue with a (relatively) fresh K10 7.0.3 installation in our other PoC cluster (K3s version v1.29.5+k3s1) but I suppose the program panic is a bug worth investigating?