

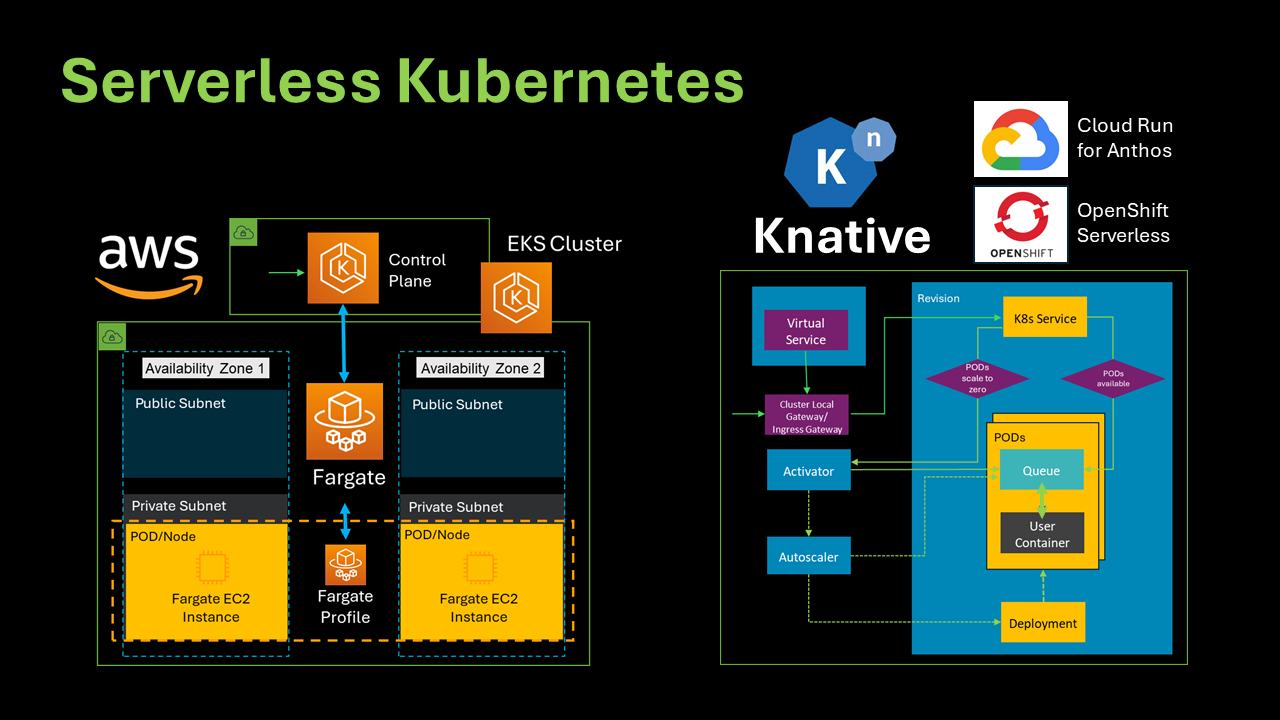
Serverless Kubernetes refers to combining serverless computing principles with Kubernetes orchestration capabilities.
It aims to simplify the deployment and management of containerized applications by leveraging Kubernetes' strengths in container orchestration while abstracting away much of the underlying infrastructure management.
Some of the advantages of Serverless Kubernetes, combining the scalability, flexibility, and operational efficiency of serverless computing with the robust orchestration capabilities of Kubernetes, are:
Simplify container deployment. It enables the easy launch of PODs and often supports deploying applications as functions or services. It is much easier to manage and scale than directly managing individual PODs through Kubernetes.
Improve scalability and elasticity of applications. Applications can automatically scale based on metrics like CPU usage, incoming requests, or custom triggers. This adaptability ensures efficient management of fluctuating workloads, maintains performance during traffic spikes, and reduces operational risks.
Speeds up development cycles and shortens time-to-market for new features. Developers can concentrate on writing application code and business logic, leveraging the serverless framework's automated deployment, scaling, and operational processes.
You only pay for the resources used to run your PODs. Serverless on Kubernetes optimizes cloud spending by allocating resources only when processing requests or events, minimizing idle resource costs. This cost efficiency is especially advantageous for applications with fluctuating or unpredictable workloads.
Serverless Computing
Serverless computing involves building and running applications without direct server management. This deployment model consists of uploading applications to a platform, often packaged as functions or services. These applications are then executed, scaled, and billed based on immediate demand.
Serverless computing doesn't eliminate using servers for hosting and executing code. Contrary to what the name suggests, serverless requires a substrate to run, that is, physical servers in some local or cloud infrastructure.

There are many examples of Serverless services and solutions: Knative, Open FaaS, AWS Lambda, Azure Functions, Google Cloud Run, IBM Cloud Functions, Huawei Function Stage and Function Graph, and others.
According to the most recent "State of Serverless Report" from Data Dog, major cloud providers continue to see significant serverless adoption. Over 70 percent of Data Dog's AWS customers and 60 percent of Google Cloud customers currently use one or more serverless solutions, with Azure following closely at 49 percent.
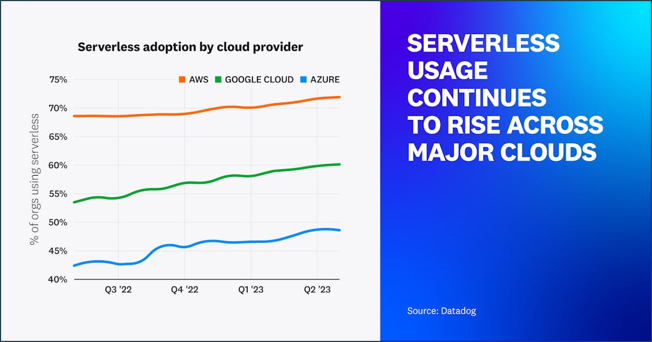
To access this report, refer to the link: https://www.datadoghq.com/state-of-serverless/
For more information about Serverless technology, access the CNCF Serverless Whitepaper:
https://github.com/cncf/wg-serverless/tree/master/whitepapers/serverless-overview
AWS EKS on Fargate
EKS (Elastic Kubernetes Service) is a managed service that eliminates the need to install, operate, and maintain your own Kubernetes control plane on AWS.
Amazon EKS aligns with the general cluster architecture of Kubernetes.
Amazon EKS ensures every cluster has its own unique Kubernetes control plane. This design keeps each cluster's infrastructure separate, with no overlaps between clusters or AWS accounts.
In addition to the control plane, an Amazon EKS cluster has a set of worker machines called nodes. Let's focus on two worker node types:
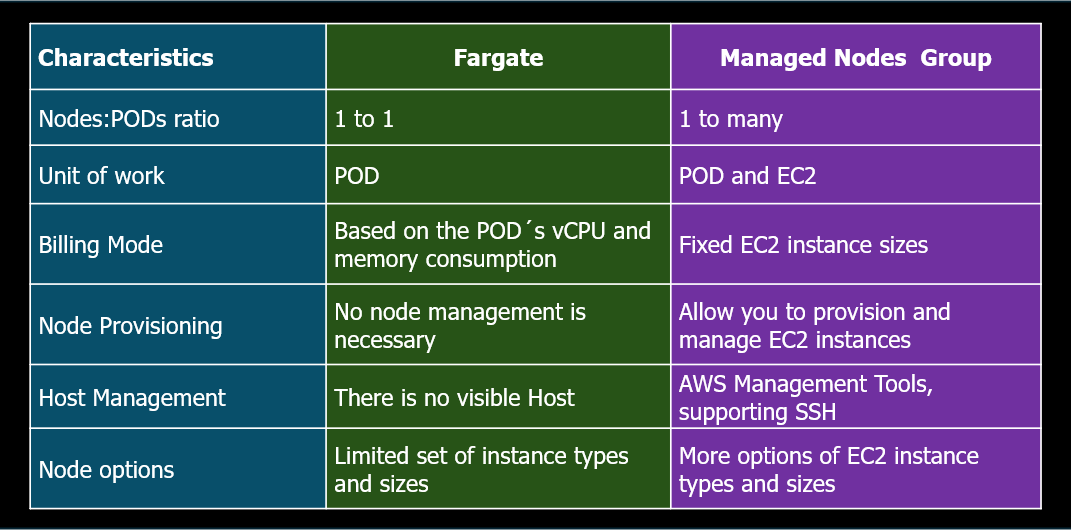
Managed node groups blend automation and customization for managing a collection of Amazon EC2 instances within an Amazon EKS cluster. AWS handles tasks like patching, updating, and scaling nodes, easing operational aspects.
AWS Fargate is a serverless computer engine for containers that eliminates the need to manage the underlying instances, like EC2. With Fargate, you specify your application's resource needs, and AWS automatically provisions, scales, and maintains the infrastructure.
When utilizing Fargate, you specify the CPU and memory resources required by your containerized application, and AWS handles the automatic provisioning and scaling of the underlying infrastructure.
This abstraction ensures you do not interact directly with EC2 instances hosting your Fargate tasks or containers, offering a fully managed, serverless environment.
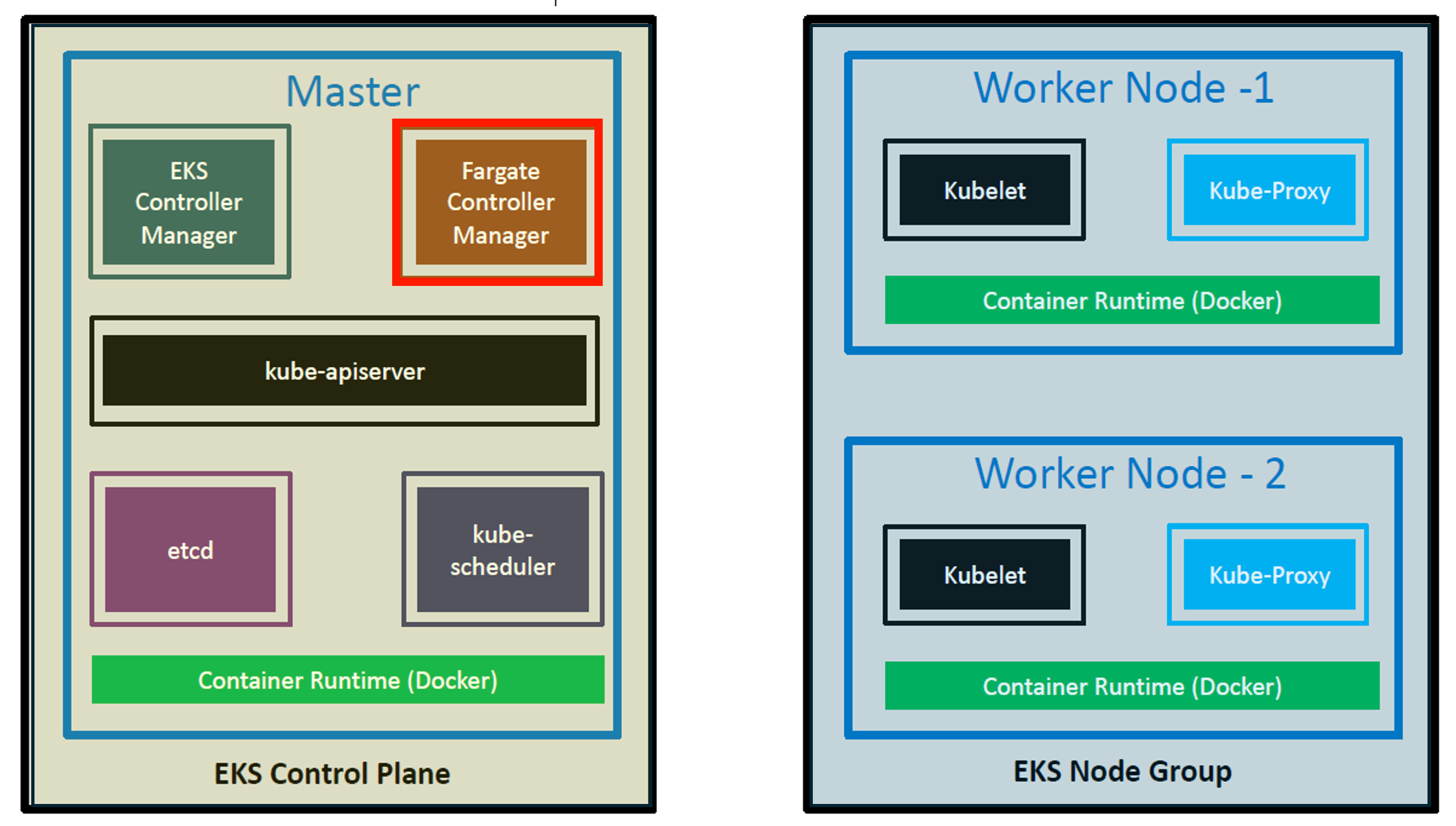
EKS integrates with Fargate using AWS-built controllers within the EKS-managed Kubernetes control plane. These controllers schedule Kubernetes pods directly onto Fargate.
The Fargate Controller Manager includes a new scheduler that runs alongside the default Kubernetes scheduler and several mutating and validating admission controllers.
When we start a POD that meets the criteria for running on Fargate, the Fargate Controller Manager running in the cluster recognizes, updates, and schedules the POD onto Fargate.
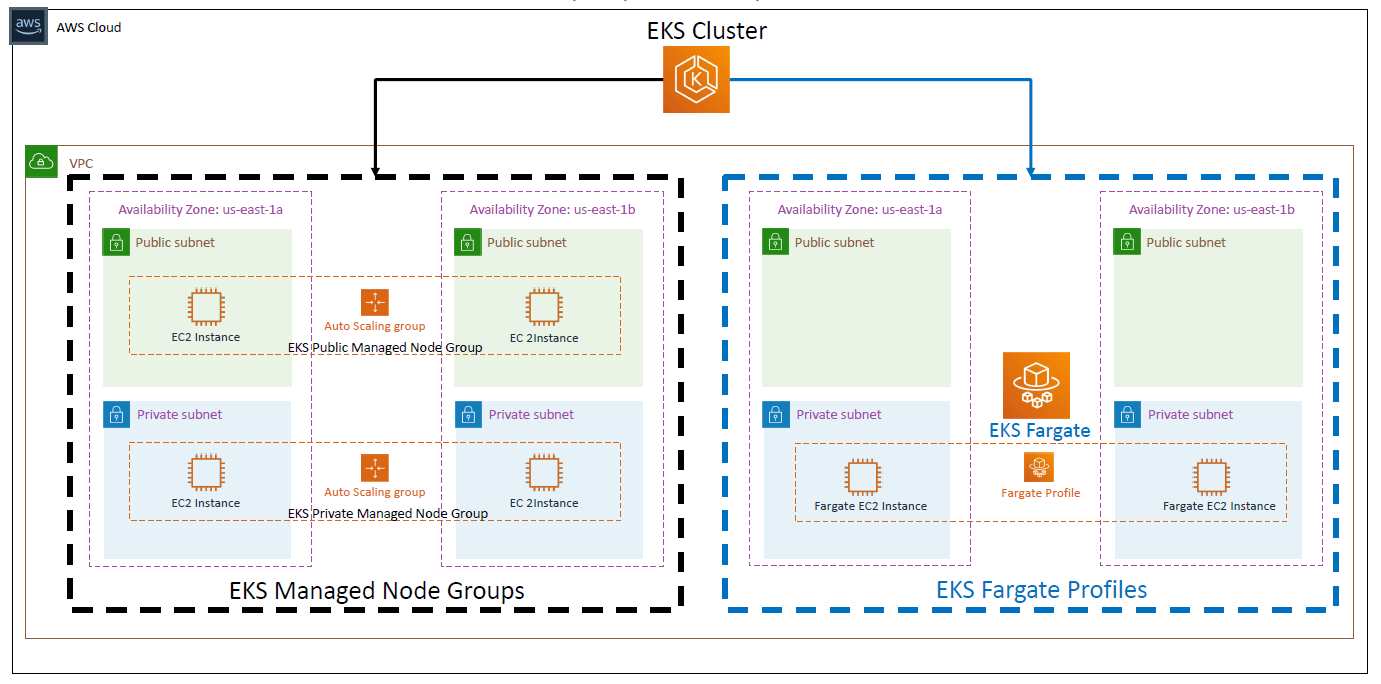
It's possible to deploy EKS clusters:
- Using only Managed EC2 Node Groups.
- In a mixed mode, using Managed EC2 Node Groups and Fargate.
- Using only Fargate.
The figure below shows an EKS cluster deployed in mixed mode:
Before you schedule PODS on Fargate in your cluster, you must define at least one EKS Fargate.
Creating an EKS Fargate profile involves defining how Kubernetes PODs are mapped to run on AWS Fargate instead of traditional EC2 instances (Managed or Unmanaged EC2 Node Groups).
The following components are contained in an EKS Fargate profile:
POD execution role must be specified. This role is added to the cluster's Kubernetes Role-based access control (RBAC) for authorization.
Subnets with no direct route to an Internet Gateway are accepted for this parameter. - only private subnets.
Selectors to match PODs using this Fargate profile. You might specify up to five selectors in a Fargate profile. The selectors have Namespaces and Labels.
Here is an example of an EKS Fargate Profile:

In addition to AWS EKS Fargate running only one POD per Node, there are other differences to the Managed EC2 Node Groups mode:
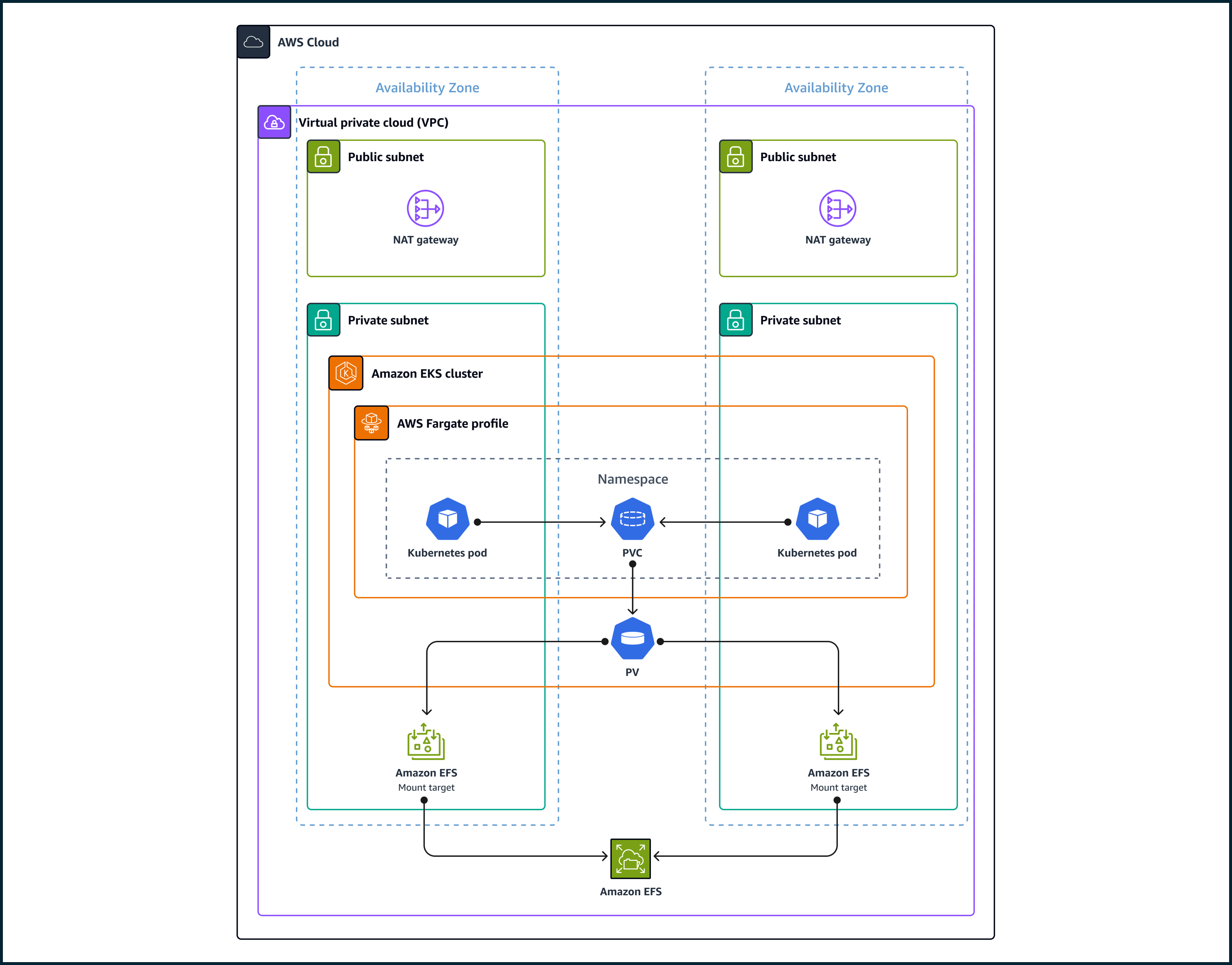
A POD running on Fargate automatically mounts an Amazon EFS file system. When provisioned, each POD running on Fargate receives a default 20 GiB of ephemeral storage, which is deleted after a POD stops.
While AWS Fargate provides ephemeral storage by default for containers, you can achieve persistence by integrating external AWS storage solutions like EBS or EFS.
Prescriptive Guidance provides information on enabling AWS EFS (Elastic File System) to be a storage device for containers running on EKS and using AWS Fargate to provision computing resources.
The target architecture for persistent storage based on EFS is presented below:
Here is the link for this Prescriptive Guide:
Now that the integration between EKS and Fargate is understood, you can access all the configuration details in the AWS EKS user manual:
https://docs.aws.amazon.com/eks/latest/userguide/fargate.html
Knative
Knative is an open-source project and a developer-focused serverless application layer that complements the existing Kubernetes application constructs.
Knative consists of three components:
Knative Serving provides a set of objects as Kubernetes custom resource definitions (CRDs) that define and control the behavior of serverless workloads on a Kubernetes cluster.
Knative Eventing is a collection of APIs that enable you to use an event-driven architecture with your applications. You can use these APIs to create components that route events from event producers (known as sources) to event consumers (known as sinks) that receive events.
Knative Functions provides a simple programming model for using functions on Knative without requiring in-depth knowledge of Knative, Kubernetes, containers, or docker files.
Knative was accepted to CNCF on March 2, 2022, at the Incubating maturity level. For more information regarding Knative, refer to: https://knative.dev/docs/
Knative Serving
Let's focus on the Knative Serving component.
Knative Serving defines a set of objects as Kubernetes Custom Resource Definitions (CRDs). These resources are used to define and control how your serverless workload behaves on the cluster.
Knative Serving resources are:
Service is the top-level custom resource defined by Knative Serving. It is a single application that manages the whole lifecycle of your workload. Your service ensures your app has a route, a configuration, and a new revision for each service update.
Configuration maintains the current settings for your latest revision and records a history of all past revisions. Modifying a configuration creates a new revision.
Revision is a point-in-time, immutable snapshot of the code and configuration.
Route defines an HTTP endpoint and associates the endpoint with one or more revisions to which requests are forwarded.
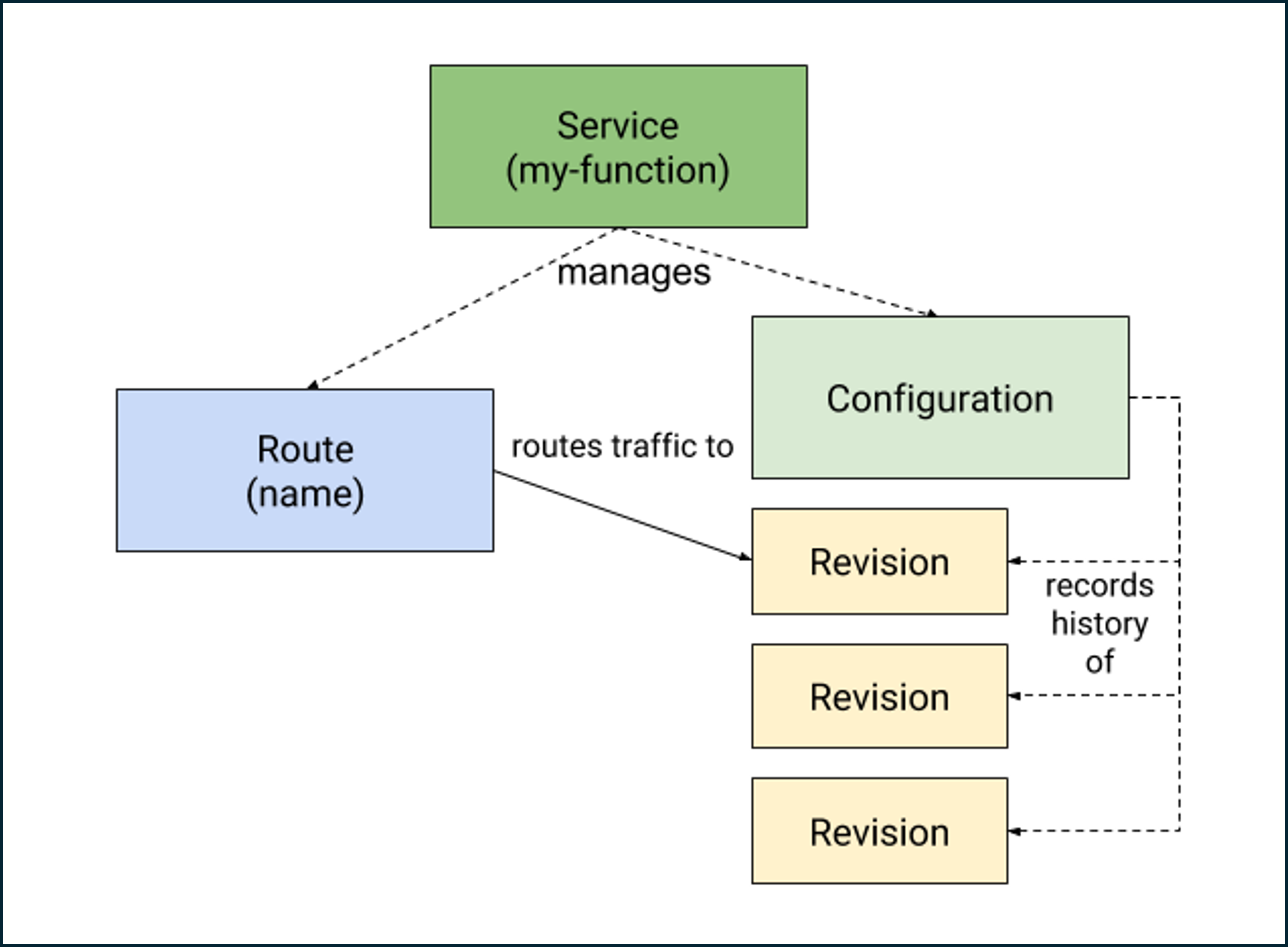
Therefore, Knative Serving allows you to deploy multiple revisions of your services and manage traffic between them.
It provides a robust platform for performing canary testing effectively, enabling developers to confidently deploy and validate new versions of their applications in the Kubernetes environment.
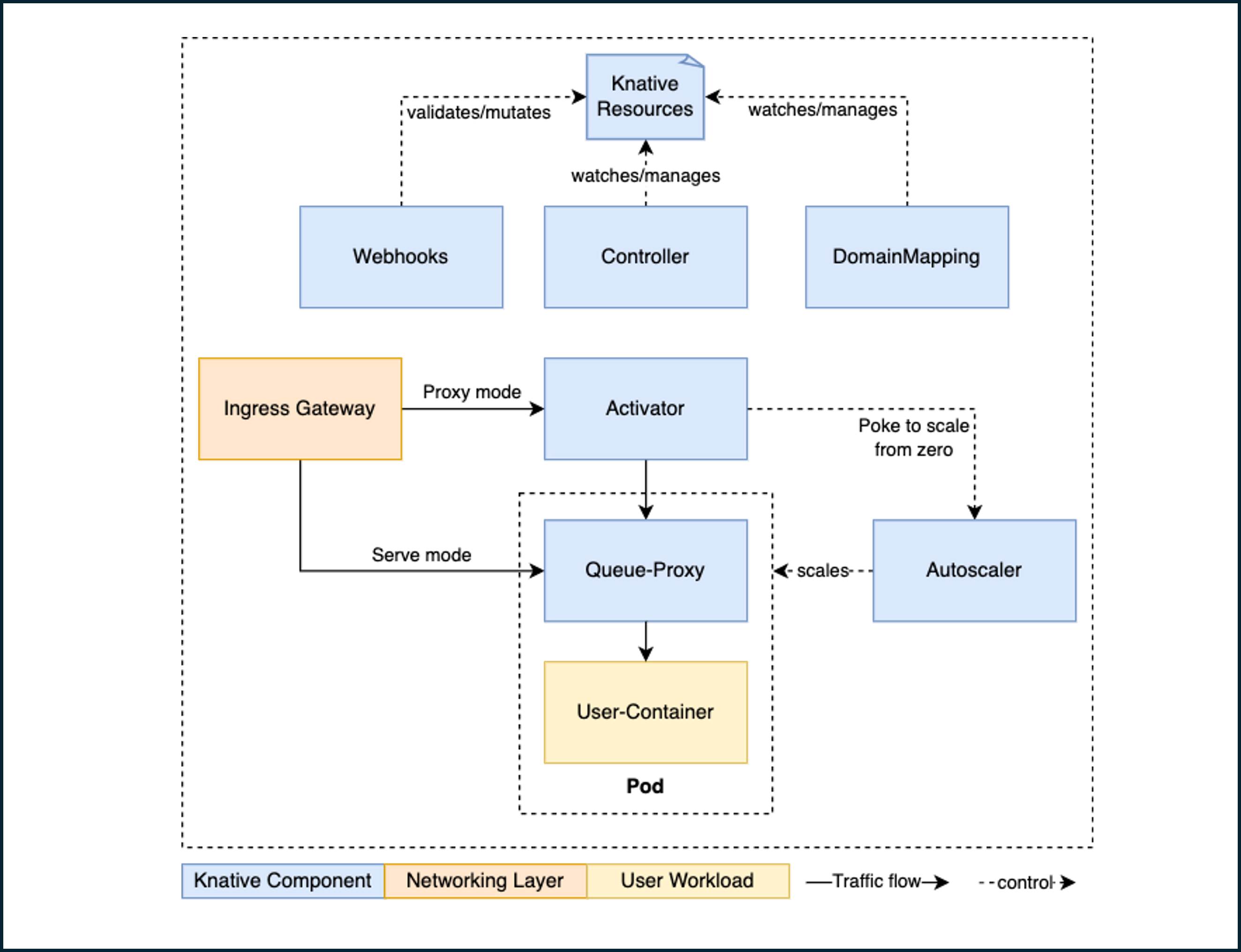
Knative Serving consists of several components forming the backbone of the Serverless Platform. Components installed by Knative serving in the knative-serving namespace are:
Activator is part of the data plane. When PODs are scaled in to zero or become overloaded with requests sent to the revision, Activator temporarily queues the requests. It sends metrics to Autoscaler to spin up more pods. Once Autoscaler scales the revision based on the reported metrics and available pods, Activator forwards queued requests to the revision.
Autoscaler is responsible for scaling the Knative Services based on configuration, metrics, and incoming requests. It aggregates and processes metrics from the Activator and the queue proxy sidecar container, a component in the data plane that enforces request concurrency limits. Autoscaler then calculates the observed concurrency for the revision and adjusts the deployment size based on the desired pod count. When pods are available in the revision, Autoscaler is a control plane component; otherwise, when pods are scaled in to zero, Autoscaler is a data plane component.
Controller manages the state of Knative resources within the cluster. It watches several objects, manages the lifecycle of dependent resources, and updates the resource state.
Queue-Proxy is a sidecar container in the Knative Service's Pod. It collects metrics and enforces the desired concurrency when forwarding requests to the user's container. It can also act as a queue, similar to the Activator.
Webhook sets default values, rejects inconsistent and invalid objects, and validates and mutates Kubernetes API calls against Knative serving resources. Webhook is a control plane component.
Two examples of solutions that use Knative Serving for their Serverless Kubernetes implementations are Google Cloud Run for Anthos and Red Hat OpenShift Serverless.
In Knative Serving, the request path determines how incoming HTTP requests are routed to different services or revisions.
It is a fundamental aspect of managing and directing traffic to different versions or parts of an application.
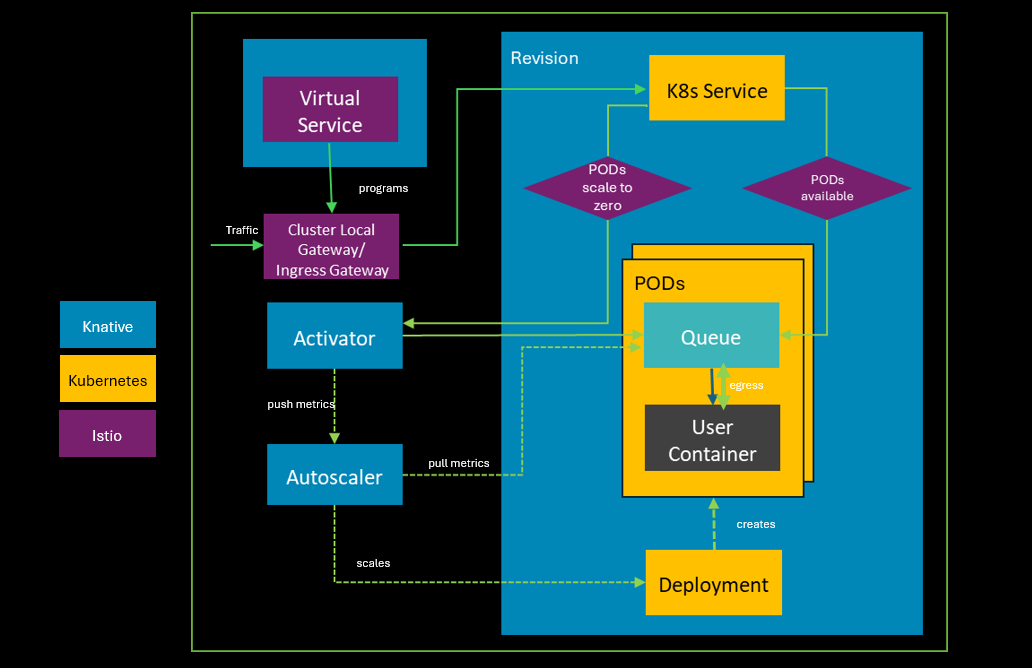
The following actions show a high-level overview of a possible request path for user traffic through the Knative serving data plane components on a sample Google Kubernetes Engine cluster.
For a Knative Serving request path:
- Traffic arrives through the Ingress Gateway for traffic from outside or through the Cluster Local Gateway for traffic within clusters.
- The VirtualService component specifies traffic routing rules and configures the gateways so that user traffic is routed to the correct revision.
- Kubernetes Service is a control plane component and determines the next step in the request path dependent on the availability of pods to handle the traffic:
- If there are no PODs in the revision: Activator temporarily queues the request received and pushes a metric to Autoscaler to scale more PODs; Autoscaler scales to the desired state of PODs in Deployment; Deployment creates more PODs to receive additional requests; Activator retries request to the queue proxy sidecar.
- If the service is scaled out (PODs are available), the Kubernetes Service sends the request to the queue proxy sidecar.
- The queue proxy sidecar enforces request queue parameters, single or multi-threaded requests, that the container can handle at a time.
- If the queue proxy sidecar has more requests than it can handle, Autoscaler creates more PODs to handle additional requests.
- The queue proxy sidecar sends traffic to the user container.
Now that the Knative Serving is understood a bit more, you can access and use the installation guide to deploy your environment:
https://knative.dev/docs/install/
Conclusion
Serverless Kubernetes empowers organizations to prioritize application logic over infrastructure management, enabling faster and more frequent code deployments in response to market demands and customer feedback. This paradigm shift enhances agility and accelerates innovation cycles.
Multiple Serverless Kubernetes solutions are available in the market, each with distinct features and capabilities designed to meet diverse use cases and organizational requirements.
References:
https://docs.aws.amazon.com/pt_br/eks/latest/userguide/fargate.html
https://knative.dev/docs/getting-started/first-traffic-split/#splitting-traffic-between-revisions
https://knative.dev/docs/serving/architecture/
https://cloud.google.com/anthos/run/docs/architecture-overview?hl=pt-br
