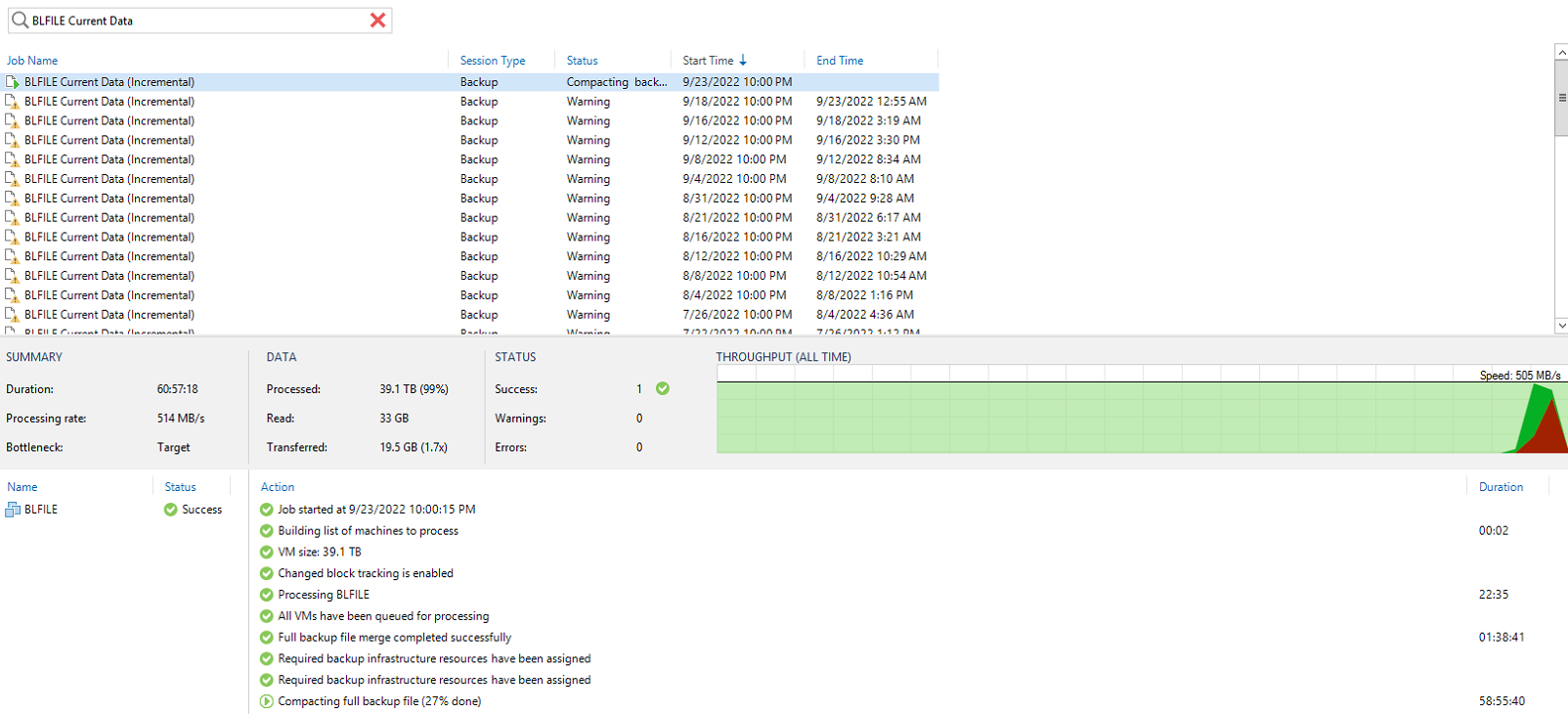
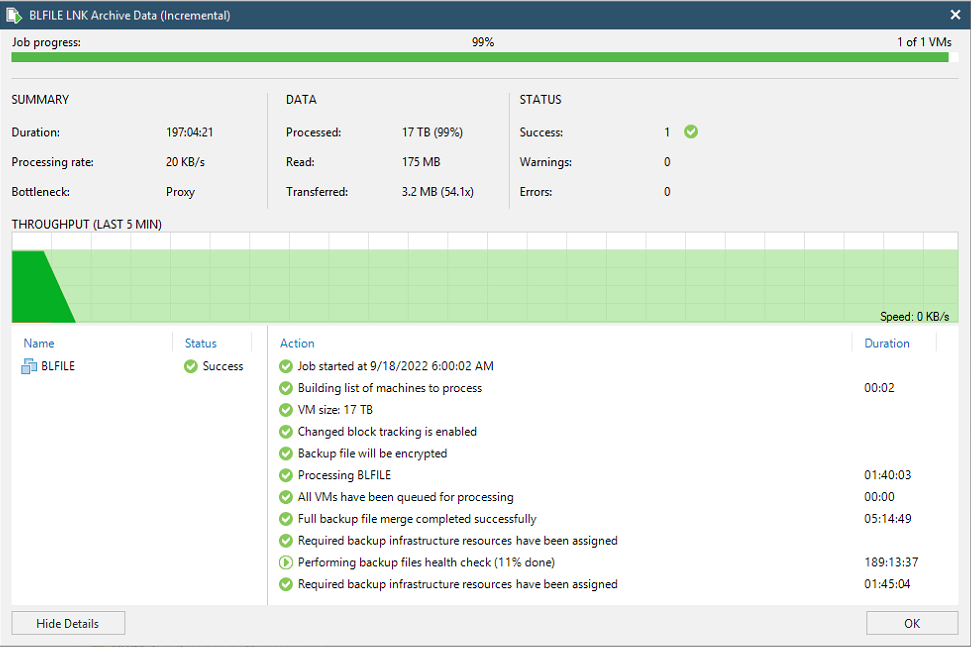
Here’s one to find out who has the largest backup in the forums.
Currently my largest server I backup is 45.1TB.
The largest one I had backing up was 115TB. It took a while but worked fine. I’ve been working on splitting it up in to multiple file servers to allow more concurrent streams to our backup/tape jobs.