Here’s one to find out who has the largest backup in the forums.
Currently my largest server I backup is 45.1TB.
The largest one I had backing up was 115TB. It took a while but worked fine. I’ve been working on splitting it up in to multiple file servers to allow more concurrent streams to our backup/tape jobs.
Page 1 / 3
Something around 45 TB.
At this moment it is a 18 TB SAP Server and a 30 TB Exchange Cluster...
We have one client VM backing up that is 55TB right now I believe. It takes a while too for that one.
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
Daily… And the SAP logs at least every hour…
Backup is not the big problem after the initial full backup, I am afraid of a complete restore…
I have told the VM owner to split their VMDKs into several VMDKs with at most 1 TB size. So we can restore with several sessions and with one for these big VMs….
Wow, nothing as large as that. 5TB is our largest so far
My largest is about a 120TB file server….which is getting ready to grow as the client is starting to put a lot of 4k video on it. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
Daily… And the SAP logs at least every hour…
Backup is not the big problem after the initial full backup, I am afraid of a complete restore…
I have told the VM owner to split their VMDKs into several VMDKs with at most 1 TB size. So we can restore with several sessions and with one for these big VMs….
I have this issue at work with growth, DFS has been a life saver moving stuff but trying to get other people to keep the VMDK’s down. Every time I look someone seems to create 25TB+ VMDK files lol.
My biggest issue is Tape. Even with 50 VMDK’s, its still a single VBK file.
Due to my many file servers I do weekly to tape as it takes a few days going to 8 drives. If I were to din incremental they usually fail during that time. I like having a weekly full incase I lose a tape or something catastrophic happens.
I hope in future versions of Veeam there is the ability to split a VBK file into multiple files for tape backup performance using multiple drives.
My largest is about a 120TB file server. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Out of curiosity, how long do the backups and health checks, etc take?
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
the 115TB took a few days to backup originally. the incremental were minimal, but it always made me nervous if I needed to restore. Portability was bad too if I needed to move to a new repo etc.
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
Daily… And the SAP logs at least every hour…
Backup is not the big problem after the initial full backup, I am afraid of a complete restore…
I have told the VM owner to split their VMDKs into several VMDKs with at most 1 TB size. So we can restore with several sessions and with one for these big VMs….
I have this issue at work with growth, DFS has been a life saver moving stuff but trying to get other people to keep the VMDK’s down. Every time I look someone seems to create 25TB+ VMDK files lol.
My biggest issue is Tape. Even with 50 VMDK’s, its still a single VBK file.
Due to my many file servers I do weekly to tape as it takes a few days going to 8 drives. If I were to din incremental they usually fail during that time. I like having a weekly full incase I lose a tape or something catastrophic happens.
I hope in future versions of Veeam there is the ability to split a VBK file into multiple files for tape backup performance using multiple drives.
Are you using GFS at all?
My largest is about a 120TB file server. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Out of curiosity, how long do the backups and health checks, etc take?
On my 115TB server I had to turn the health checks off completely. To be fair though, the Veeam SAN had no flash disk or SSD’s so it wasn’t a monster of a SAN.
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
Daily… And the SAP logs at least every hour…
Backup is not the big problem after the initial full backup, I am afraid of a complete restore…
I have told the VM owner to split their VMDKs into several VMDKs with at most 1 TB size. So we can restore with several sessions and with one for these big VMs….
I have this issue at work with growth, DFS has been a life saver moving stuff but trying to get other people to keep the VMDK’s down. Every time I look someone seems to create 25TB+ VMDK files lol.
My biggest issue is Tape. Even with 50 VMDK’s, its still a single VBK file.
Due to my many file servers I do weekly to tape as it takes a few days going to 8 drives. If I were to din incremental they usually fail during that time. I like having a weekly full incase I lose a tape or something catastrophic happens.
I hope in future versions of Veeam there is the ability to split a VBK file into multiple files for tape backup performance using multiple drives.
With V12 you get real single VM backup files. This may help with your tape problem...
My largest is about a 120TB file server. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Out of curiosity, how long do the backups and health checks, etc take?
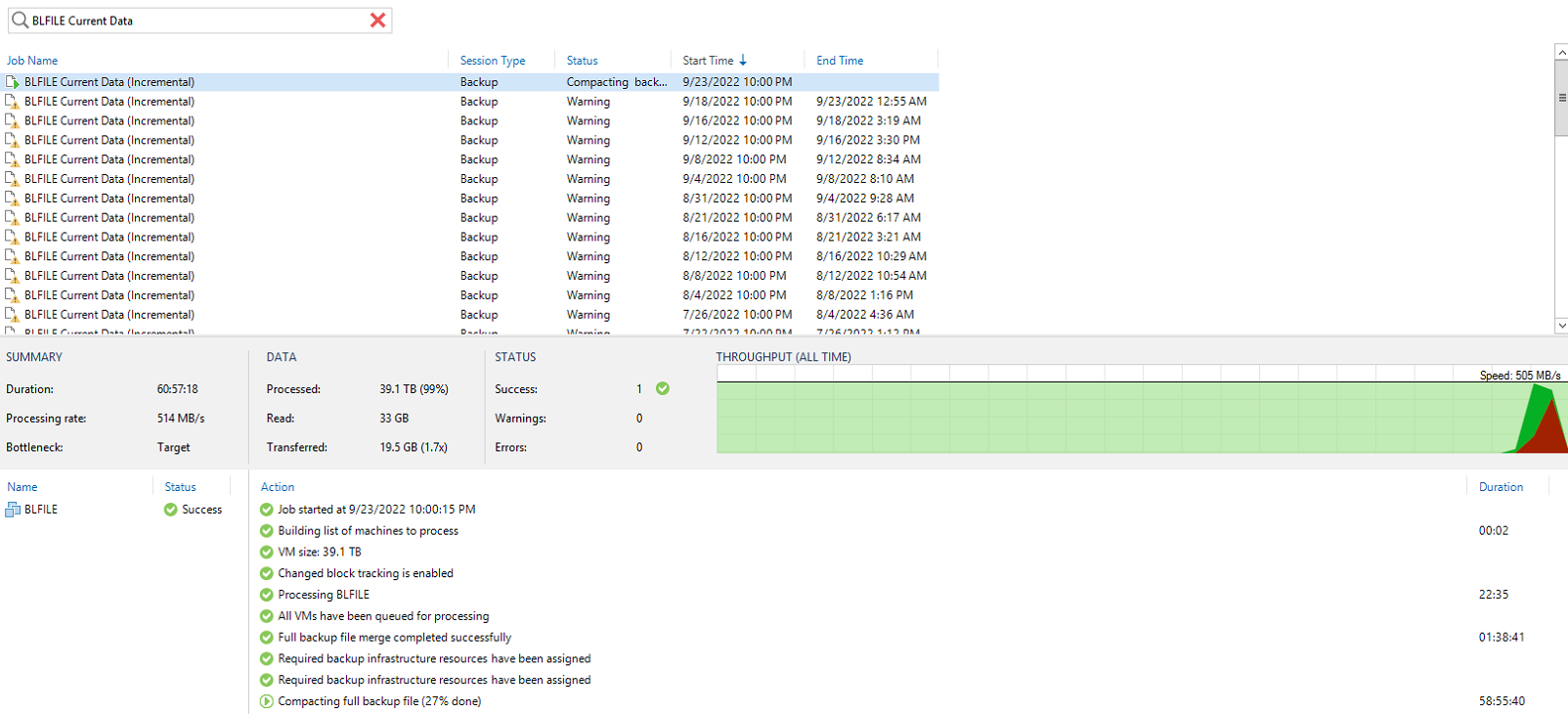
Okay, so I have it split up into three jobs, each with backup up specific disks. Two sets are disks that contain archived data that is rarely accessed. The third is the production data that they are currently working on. The archive disks backup quickly because there’s very little data changing there. The “current” production dataset takes between 3-8 hours to backup depending on how much data changed on the disks. Fortunately (I guess) the users are doing their video editing on their workstations and then upload the final video to the file server, so there isn’t new data every day, but it’s fairly often.
Health checks, compaction, etc is another animal.
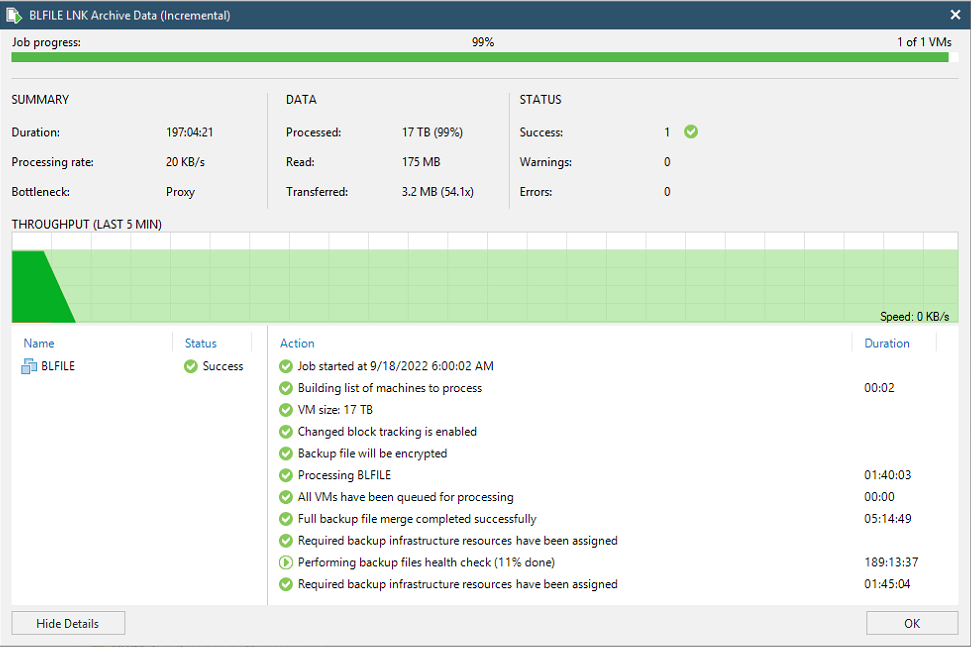
As you can see, the current compaction has been running for 61 hours and is at 27%. Which is not great, but much better than the heath check running on one of the archive jobs that it as 11% after 197 hours. There has got to be a better way, but I haven’t found it yet.
I’m sending a proposal to the client this week for adding an additional 30-40TB of disk to their SAN to allow for more space (primary storage, not backup storage), but on my call with them Friday, we discussed checking into offloading their archive data to a cloud provider such as Wasabi to get it out of their datacenter and off of the production SAN. This would free up space on their repository and allow me space to perform incremental fulls I believe and eliminating the need to running some of the maintenance on the data that is required with Forever Forward Incrementals. But I’ve not used Wasabi in this fashion, so I have some research to do to see if this is possible and work my way up from there.
My largest is about a 120TB file server. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Out of curiosity, how long do the backups and health checks, etc take?
On my 115TB server I had to turn the health checks off completely. To be fair though, the Veeam SAN had no flash disk or SSD’s so it wasn’t a monster of a SAN.
I may just need to disable health checks. I don’t like that idea, but the alternative is running checks/maintenance that takes days or weeks and causes several backups to be missed.
Oh God ! How many time to backup this one ?
For me the max was around 10TB.
Daily… And the SAP logs at least every hour…
Backup is not the big problem after the initial full backup, I am afraid of a complete restore…
I have told the VM owner to split their VMDKs into several VMDKs with at most 1 TB size. So we can restore with several sessions and with one for these big VMs….
I have this issue at work with growth, DFS has been a life saver moving stuff but trying to get other people to keep the VMDK’s down. Every time I look someone seems to create 25TB+ VMDK files lol.
My biggest issue is Tape. Even with 50 VMDK’s, its still a single VBK file.
Due to my many file servers I do weekly to tape as it takes a few days going to 8 drives. If I were to din incremental they usually fail during that time. I like having a weekly full incase I lose a tape or something catastrophic happens.
I hope in future versions of Veeam there is the ability to split a VBK file into multiple files for tape backup performance using multiple drives.
With V12 you get real single VM backup files. This may help with your tape problem...
Pretty sure you should get separate files if you split the VMDK’s into separate jobs. It’s a bit of a pain, but might be helpful.
My largest is about a 120TB file server. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Out of curiosity, how long do the backups and health checks, etc take?
On my 115TB server I had to turn the health checks off completely. To be fair though, the Veeam SAN had no flash disk or SSD’s so it wasn’t a monster of a SAN.
The client here has a large Synology NAS that’s good for something like 90TB of space. No SSD’s as well on this one. I’ve found that SSD’s aren’t as useful in most of our environments for backup performance since it’s a lot of writes and the SSD’s are really better for read caching. If I have to choose between SSD cache or 10Gb connectivity, I’ve found 10Gb to be the better investment.
something around 41TB, used 30TB. Around 3TB with the compression factor 11 (love it).
First Active Full 3h30, daily incremental 30 minutes. VM is on Vsan.
Exchange infra with 400TB was one of my biggest challenges on backup but it’s not a single server/VM.
My largest is about a 120TB file server. It’s been rough getting it through error checking backup defrags. Unfortunately, we don’t have enough space on the repo to setup incremental full’s due to size. It’s a process…..and we’re still trying to find a better way for it.
Out of curiosity, how long do the backups and health checks, etc take?
Good question! @JMeixner raised a concern on restoration. Have you had to deal with this @dloseke?
I’m not sure if my team has ever had to do a restore on this VM…..if so, it would likely have been an individual file or two, but not the whole VM. I actually don’t have a place to drop the VM to test restoring this one.
I’m not sure if my team has ever had to do a restore on this VM…..if so, it would likely have been an individual file or two, but not the whole VM. I actually don’t have a place to drop the VM to test restoring this one.
I’m in a similar situation. I have spun it up in Veeam and pulled files off of a 100TB+ file server, but don’t usually have over 100TB just kicking around to test something. I did test restoring a few 20TB servers from TAPE a few weeks ago to see how long it would take, and it wasn’t great, but it worked at least.
I’m not sure if my team has ever had to do a restore on this VM…..if so, it would likely have been an individual file or two, but not the whole VM. I actually don’t have a place to drop the VM to test restoring this one.
I’m in a similar situation. I have spun it up in Veeam and pulled files off of a 100TB+ file server, but don’t usually have over 100TB just kicking around to test something. I did test restoring a few 20TB servers from TAPE a few weeks ago to see how long it would take, and it wasn’t great, but it worked at least.
I have a client that I installed a Nimble array for last week (HF20 to replace a CS1000 if you care). I will be finishing the VM migration from the old to the new next week and one thing they wanted to try before we tear out the CS1000 is a full restore of all VM’s from the tape server I installed about 6 months ago. I don’t expect blazing fast speeds or anything, but they wanted to make sure it worked which I’m all for testing and I’d love to get a baseline on how long it takes. I think we’re looking at about 40 VM’s for a total of around 6TB or 8TB of data.
I’m not sure if my team has ever had to do a restore on this VM…..if so, it would likely have been an individual file or two, but not the whole VM. I actually don’t have a place to drop the VM to test restoring this one.
I’m in a similar situation. I have spun it up in Veeam and pulled files off of a 100TB+ file server, but don’t usually have over 100TB just kicking around to test something. I did test restoring a few 20TB servers from TAPE a few weeks ago to see how long it would take, and it wasn’t great, but it worked at least.
I have a client that I installed a Nimble array for last week (HF20 to replace a CS1000 if you care). I will be finishing the VM migration from the old to the new next week and one thing they wanted to try before we tear out the CS1000 is a full restore of all VM’s from the tape server I installed about 6 months ago. I don’t expect blazing fast speeds or anything, but they wanted to make sure it worked which I’m all for testing and I’d love to get a baseline on how long it takes. I think we’re looking at about 40 VM’s for a total of around 6TB or 8TB of data.
That shouldn’t be too bad. For my environment i’m sure its around 400TB to test that which is not reasonable. although when it comes to ransomware, they will be more than happy to wait vs the alternative. plus i do have hot backups on production SANS. the tape is a historical/last resort.
Awesome topic @Scott!
Some great conversation here around handling Backup & restoration of these beasts. I’d chime in that unless it’s ransomware I’d generally use quick rollback if I needed to restore a volume. If it was ransomware and the customer didn’t have space for an extra copy I’d ask them to engage their infosec response teams if leaving the OS disk is sufficient and purging the rest. Mileage may vary.
As for largest VM, I had a really interesting one for sizing. Customer was somewhere between 100-150TB of data on a file server. What’s that big you might ask? It was high resolution, lossless, images of the ocean floor and other such ocean-related imagery.
Because it was lossless, the compression algorithm of Veeam had a whale of a time (pun intended ) compressing the data. IIRC the full backup was 20-30TB. The main kicker was that the imagery was updated periodically, so that entire 100-150TB of data was wiped from their production storage, and new data sets were supplied. But again, it was 99.9% uncompressed images. Other system data churn was about 1-2GB per day.
Fast Clone kept the rest of the data requirements in check to avoid unnecessary repository consumption, and the backup repo could handle the data overall easily. Retention was also a saving grace as although they relied on their backups for “oh can we compare this to 2-3 weeks ago”, IIRC they only retained about 6 weeks of imagery. As for restorations, once this wasn’t the live dataset they only wanted to compare specific images, not entire volumes.
Glad I talked them into a physical DAS style repo instead of the 1Gbps SMB Synology design they were going for!
Awesome topic @Scott!
Some great conversation here around handling Backup & restoration of these beasts. I’d chime in that unless it’s ransomware I’d generally use quick rollback if I needed to restore a volume. If it was ransomware and the customer didn’t have space for an extra copy I’d ask them to engage their infosec response teams if leaving the OS disk is sufficient and purging the rest. Mileage may vary.
As for largest VM, I had a really interesting one for sizing. Customer was somewhere between 100-150TB of data on a file server. What’s that big you might ask? It was high resolution, lossless, images of the ocean floor and other such ocean-related imagery.
Because it was lossless, the compression algorithm of Veeam had a whale of a time (pun intended ) compressing the data. IIRC the full backup was 20-30TB. The main kicker was that the imagery was updated periodically, so that entire 100-150TB of data was wiped from their production storage, and new data sets were supplied. But again, it was 99.9% uncompressed images. Other system data churn was about 1-2GB per day.
Fast Clone kept the rest of the data requirements in check to avoid unnecessary repository consumption, and the backup repo could handle the data overall easily. Retention was also a saving grace as although they relied on their backups for “oh can we compare this to 2-3 weeks ago”, IIRC they only retained about 6 weeks of imagery. As for restorations, once this wasn’t the live dataset they only wanted to compare specific images, not entire volumes.
Glad I talked them into a physical DAS style repo instead of the 1Gbps SMB Synology design they were going for!
Very cool.
I didn’t want to ask “What type of data” as I know there are many rules and regulations, but it’s very interesting finding out what people have to store and keep. I have a TON of photos and videos that make up most of my data. I can’t really get into what for, but it doesn’t compress very well. Lucky for me I have a ton of databases that compress really well to make up for it.
It’d be pretty neat looking at those ocean floor images.
Good point with fast clone if you need a quick restore. I find in most cases I’m doing file level restores off these monster file servers as people delete things, or more often accidently copy something and lose track of where it went. We’ve all had a mouse slip. To go one step further, ADAudit is a great tool for finding those. Every time someone requests a restore I do a search to see who, when and where the file was deleted from. half the time someone slipped and dropped the folder another level down. I move it back saving duplicate data.
Another thing I try and do, is keep low churn on the same servers. that way some of the real big archive servers don’t end up growing anymore. I find organizing by year in subfolders is a great way to talk to a department/division and say, “Can we archive everything pre 2015 etc.” or How many years of X do we need to keep for legal purposes.
My biggest vm being backed up was a “Giant” 2TB SQL Server, and a 1.5TB Oracle Server.
they were not so big, but very critical, both running in Mechanic Discs, so the backups took so long to perform, and some times, the machines jammed, so they were backed up at night, out of working ours, and every time we did a change, fingers crossed for not messing the Full backup. .


 !
! 
 ) compressing the data. IIRC the full backup was 20-30TB. The main kicker was that the imagery was updated periodically, so that entire 100-150TB of data was wiped from their production storage, and new data sets were supplied. But again, it was 99.9% uncompressed images. Other system data churn was about 1-2GB per day.
) compressing the data. IIRC the full backup was 20-30TB. The main kicker was that the imagery was updated periodically, so that entire 100-150TB of data was wiped from their production storage, and new data sets were supplied. But again, it was 99.9% uncompressed images. Other system data churn was about 1-2GB per day.