Hello, please give me suggestions to solve this problem.
I have a problem regarding backup recovery which makes me stressed. I want to replicate or restore data from one baremetal to another baremetal in the scheme below without vSphere.
- Baremetal A supermicro, esxi 8.0 host (master node)
- Baremetal B Intel, esxi 8.0 host (node replication)
- Baremetal C Dell R760, esxi 8.0 host (node replication)
I ran some replication and recovery tests
VM test 1
restored from baremetal A to baremetal B, successful without any problems
restored from baremetal A to baremetal C, success, no problems
VM test 2
restored from baremetal A to baremetal B, successful without any problems
restoration from baremetal A to baremetal C, there were many problems (I will attach it below)
VM test 2
restoration from baremetal B to baremetal C, there were many problems (I will attach it below)
I have also done a file copy test for "vm test 2" but it still has problems, for some reason it refuses to run on the baremetal Dell R760.
error message 1, baremetal A to C
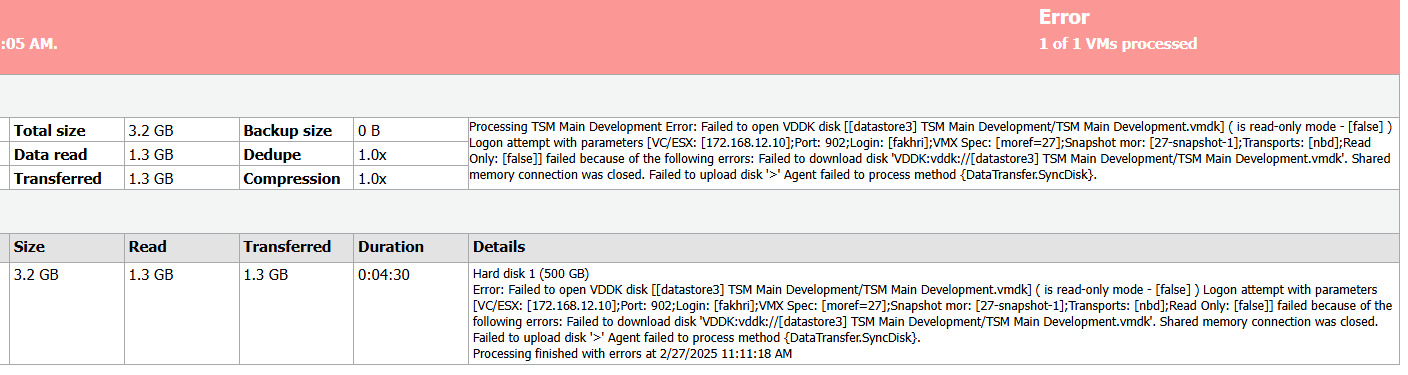
Error Restore job failed Error: Failed to open VDDK disk [[Datastore 3] VM test/VM test.vmdk] ( is read-only mode - [false] )
Error Restore job failed Error: Logon attempt with parameters [VC/ESX: [x.x.x.x];Port: 902;Login: [user];VMX Spec: [moref=14];Snapshot mor: [14-snapshot-1];Transports: [nbd];Read Only: [false]] failed because of the following errors:
AM Error Restore job failed Error: Failed to download disk 'VDDK:vddk://[Datastore 3] VM test/VM test.vmdk'.
error message 2, baremetal A to C (datastore1 baremetal A)
Hard disk 1 (150 GB) Error: VDDK async operation error: 14009. Value: 0x00000000000036b9 Unable to read file block. File: [vddk://[datastore1] VM test/VM test.vmdk]. Offset: [13154385920]. Block granularity: [1048576].
error message 3, baremetal A to C
Failed to copy item 'nfc://conn:x.x.x.x,nfchost:ha-host,stg:670827fb-50c3b636@VM test/VM test-flat.vmdk' Error: NFC server [x.x.x.x] is busy. Delivery of a FILE_PUT message has failed. Processed file: [[datastore3] VM test/VM test-flat.vmdk]. Size of the processed data: [7435657216]. Size of the file: [161061273600]. Unable to receive file. Exception from server: Shared memory connection was closed.
i confirmed that there is no snapshot on the vm