Hi,
I have 2 locations with a Veeam server and a vCenter cluster with 2 hosts.
The configuration is on both servers identical.
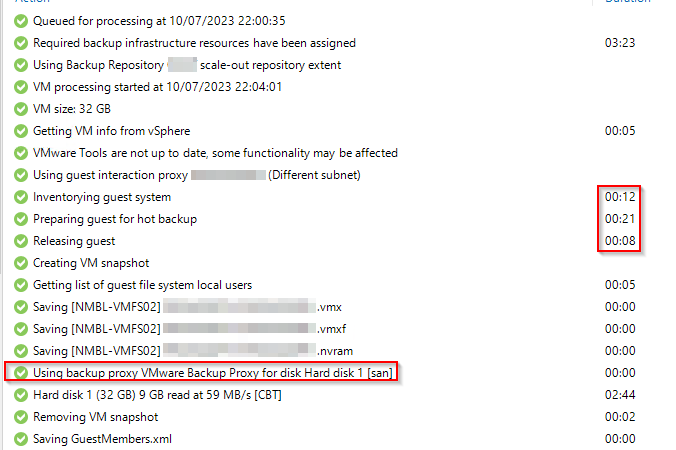
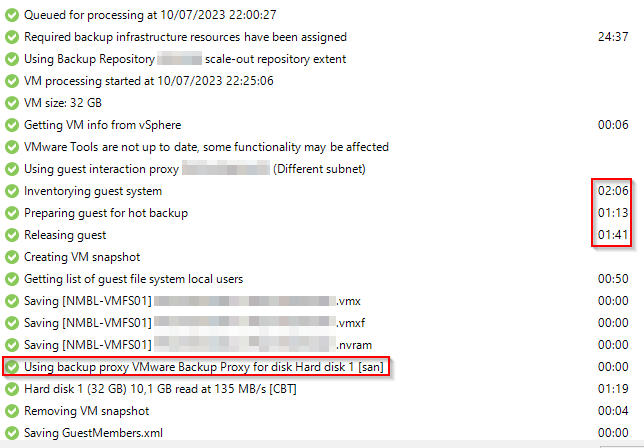
One one location, when running a job with application awareness, the inventorying guest system and the other preparing jobs are taking several seconds, but on the other location, it takes minutes.
It does not fail, but the time of processing is much longer.
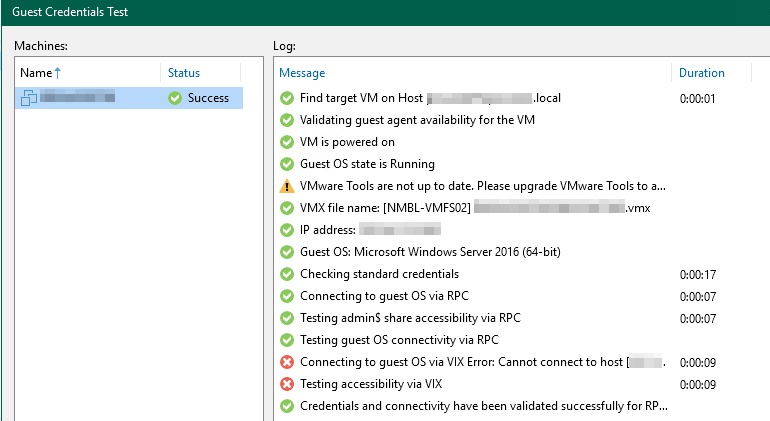
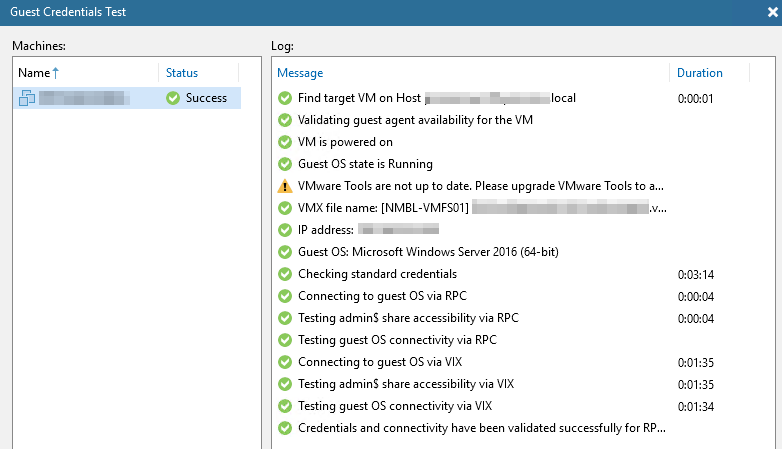
The difference I see, on the ‘slow’ location, all communications running via vCenter. On the fast one, all is going direct from B&R server to the VM.
Firewall rules are identical and I don’t see any blocks, so the slow one does not try to direct connect to the VM.
Any ideas where to look for?
The B&R server is in a seperated VLAN with explicit firewall rules between them, conform the manuals.
Thank you!