

General Recommendations
Platform Memory and CPU Over-commitment
First and foremost, memory over-commitment is not recommended in OpenShift. However, Red Hat recommends overall CPU over-commitment ratio must not exceed 1.8x of the number of physical cores and that memory usage may not exceed 0.9x of the physical memory available in a cluster. This rule is applicable to the ratio of CPU allocation to all of the pods to physical cores available in a cluster.
NOTE: CPU over-commitment leads to throttling, so slowness of all workloads on the impacted node. Thereby workloads can be more or less sensitive to that.
✅More Information about CPU Ready Here
General rules for the vCPU:pCPU ratio ⚙️🧠:
✅ 1:1 to 1:3 → No problem 😌
⚠️ 1:3 to 1:5 → Performance may start to degrade 🐢📉
🚫 1:5 or higher → Likely CPU Ready issues 🔴🧯
Storage and Network Latency
Various kinds of applications are more or less sensitive to latency on network and/or storage. In the context of an OCP instance the etcd as hosted on the control-plane nodes used to store the cluster state from a Kubernetes perspective is usually the component which is most sensitive to latency issues.
For this etcd it is not good enough to have low latency on average, but at any time. That's why Red Hat recommendations on etcd storage and network performance are defined as 99% quantiles.
The most common issues with etcd 🛠️ usually happen due to one (or more) of the following factors:
🐌 Slow storage
🔥 CPU overload
📈 Growth of the etcd database size
Applying a request should normally take less than 50 milliseconds ⏱️.
If the average apply duration exceeds 200 milliseconds, etcd will warn that entries are taking too long to apply (look for “took too long” messages in the logs) ⚠️📋.
So,
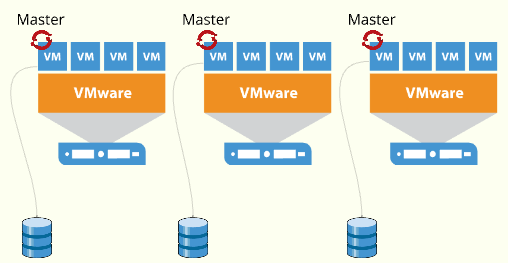
✅ Best Practices for Master Node Placement in VMware
To ensure high availability and optimal performance of the OpenShift control plane:
-
Distribute the 3 virtual master nodes across different VMware hosts
– Prevents a single host failure from affecting quorum and availability. -
Place each master node on a separate datastore
– Enhances resilience by avoiding storage-level single points of failure. -
Avoid hosting master nodes on datastores with high I/O workloads
– Reduces the risk of latency or performance degradation due to contention.
📌 These practices help ensure etcd stability, faster recovery, and overall platform reliability.
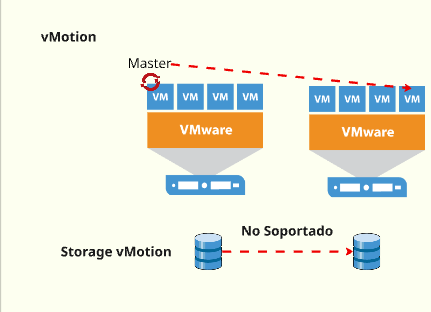
vMotion and DRS
OpenShift Container Platform generally supports compute-only vMotion, provided that all VMware best practices for vMotion are met.
regarding:
- vMotion networking requirements
- VM anti-affinity rules
Important operational considerations:
-
vMotion, like any live migration, introduces a brief period of inaccessibility for the virtual machine being moved. This interruption can negatively affect latency-sensitive workloads, such as those running on OpenShift control-plane nodes.
-
vMotion of master nodes should only be triggered when absolutely necessary. Automated vMotion processes must consider the latency sensitivity of control-plane components, particularly the etcd datastore.
-
It is critical to ensure that only one master node is migrated at a time. Additionally, there must be sufficient time between migrations to allow the etcd cluster to fully synchronize before initiating the next move.
Note:
🚫Storage vMotion is not supported.
Migrating VMs across datastores using Storage vMotion — whether manual or automated — can break internal references in OpenShift Persistent Volume (PV) objects. This can result in data loss, especially when using vSphere volumes within pods.
🎯 DRS Configuration for OpenShift Control Plane Nodes
When running OpenShift on VMware with Distributed Resource Scheduler (DRS) enabled, the following configurations are critical to ensure cluster stability and high availability:
🟥 Exclude master nodes from automatic DRS migrations
Master nodes must be excluded from automatic movements. DRS should not relocate them automatically due to their sensitivity to latency.
✅ However, VMware HA should remain enabled to allow automatic restarts in case of host failures.
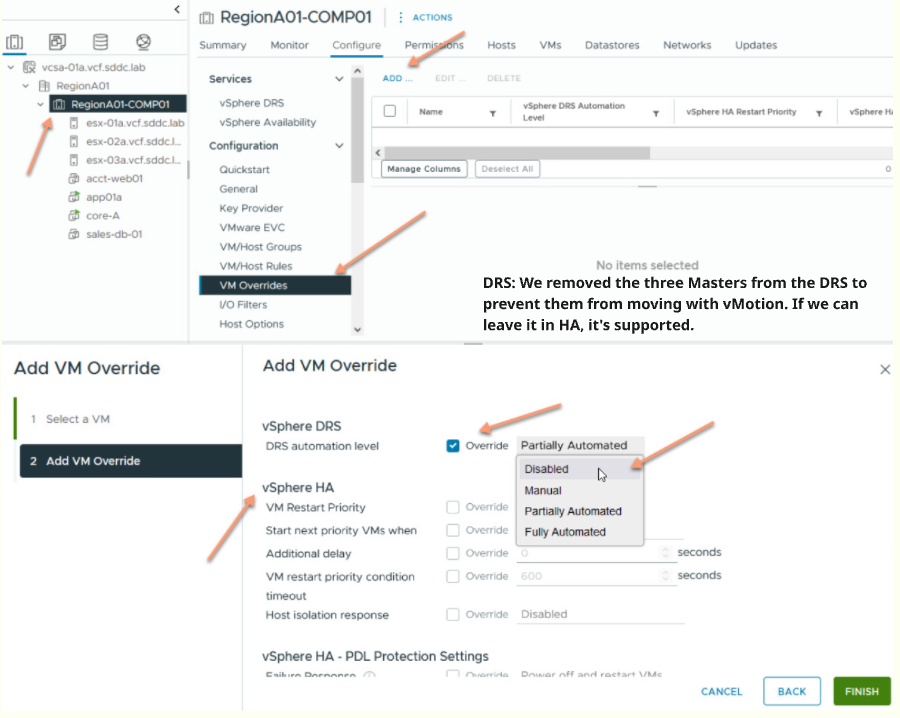
🟩 Enable VM Anti-Affinity Rules
Configure anti-affinity rules to ensure that no two master nodes are placed on the same ESXi host.
This prevents a single point of failure that could disrupt quorum or control-plane availability.
🟨 Use manual control or custom automation
DRS can remain enabled for worker nodes, but master node placement should be manually controlled or restricted via policy-based rules.
🔒 These best practices help maintain etcd consistency, improve fault tolerance, and reduce the risk of control-plane instability during infrastructure-level operations.
Finally
🎯 OpenShift Recommendations – Resource Limits
📦 Set Container Limits & Requests
🔍 Analyze historical usage to define proper pod resource requests and limits.
📕 Memory Limits
- Start with 4x the memory request as a general rule.
- Adjust depending on the application:
- ☕ Java apps may need 2x–4x for a smooth startup.
- ⚡ Node.js apps may need only 1.2x–1.5x.
🔥 Helps pods handle bursts at startup or peak usage.
🧪 Red Hat recommends testing with real workloads to fine-tune the ratios.
🚨 Why Set Limits?
- ✅ Prevents resource abuse.
- 🧯 Detects memory leaks early — pods get throttled and generate alerts.
- 👀 Helps DevOps investigate and remediate quickly.

