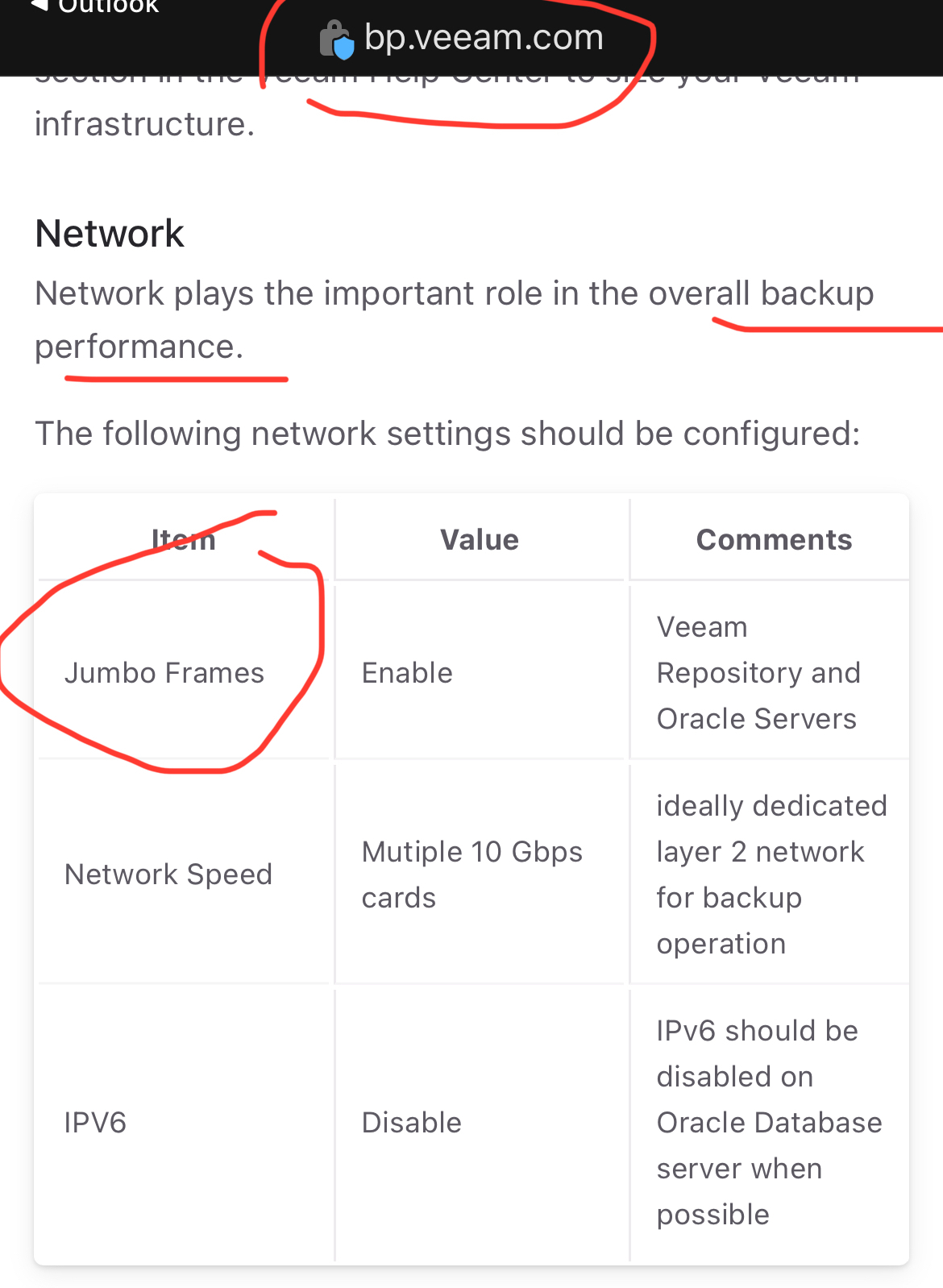
Just to follow up on that. Even with jumbo frames YMMV. I was doing extensive troubleshooting on AIX based RMAN to Windows repositories before. Root cause was a bug but it was useful to get into the deep network settings all the same.
Test environment:
Windows Repositories: 2x 40GbE networking, dual RAID 60’s per SOBR node with independent RAID controllers and 28 SAS disks per RAID controller, two SOBR extents per node (1x per RAID controller), two nodes
AIX RMAN: 2x 10GbE networking per server, all flash source storage via FC
During our testing, we omitted Veeam to focus on pure network throughput and then layered Veeam testing on top as we saw improvements. Jumbo frames provided no increase in throughput at all, (we were measuring in Gbps immediately so if there was some it wasn’t enough to move a decimal point on this…) but the differences in TCP window scaling between the Windows and AIX servers provided to be the single biggest improvement in throughput we could make. AIX by default isn’t well tuned to 10Gbps+ speeds with regards to its TCP window scaling and increasing this to match Windows was a dramatic improvement!