In my environment, all of my switches and all of my virtualization hosts support jumbo frames. as well as the Data Domain that is my storage infrastructure. However, my VBR environment - 3VMs (the VBR server, 1 proxy, and 1 managed server used to mount restores) and the physical server that attaches to the tape library are not currently set to use jumbo frames. I am wondering if setting them to use jumbo frames would help, improve performance, reduce bottlenecks?
I can’t imagine that it would hurt, right?
Anyone using jumbo frames? What is your experience?
Page 1 / 1
It should be set to use Jumbo Frames. Sometimes you can run into various errors when you have misconfiguration of JFs along your ‘end-to-end’ network. In other words, if you don’t have JF set along every network object in the given path, you could have errors. Yes, I have mine set. Have been using it for yrs. And yes, it “should” improve performance, although may be negligible.
It will improve performance, but not much.
I don't think that you will see a significat effect. I did not in the one environment I have tried it.
It will improve performance, but not much.
I don't think that you will see a significat effect. I did not in the one environment I have tried it.
So it can’t hurt, but it may not revolutionize my life. LOL I have jumbo frames enabled all through my environment, so I might as well turn it on.
Thanks!
Nope...doesn't hurt
It will improve performance, but not much.
I don't think that you will see a significat effect. I did not in the one environment I have tried it.
So it can’t hurt, but it may not revolutionize my life. LOL I have jumbo frames enabled all through my environment, so I might as well turn it on.
Thanks!
Exactly
It doesn't hurt, but I won't save the day either.
My experience with Frames is that a mismatch is not good, resulting in fragmentation and re-transmissions.
Scenario 1: all frames set to standard MTU end-to-end the data path including NIC, all switch ports, and storage array, and beware that different switches have different MTUs - performance OK.
Scenario 2: all frames set to Jumbo Frames end-to-end the data path including NIC, all switch ports, and storage array - performance should definitely improve for sequential IO pattern.
Scenario 3: Frame mismatch - likely to be worse that Scenario 1.
The answer I just said I hate. “It depends” :)
If everything it the path is set, and you are moving large files in a sequential transfers, it can help a lot.
If you have a mismatch, it can cause more harm than good.
If you are not sending a ton of data, it won’t make much of a difference.
Where it makes a difference is things like replication, copy jobs, VMotion etc. Sequential moves of large files.
Jumboframes are awesome. Performance may be negligible, but can’t hurt if done right. If you attempt to use Jumboframes but don’t have that set at every hop end to end, you’re likely to end up with packet fragmentation which is going to negatively affect your performance. One way to test is to ping with a set packet size and disallow fragmentation to validate that packets larger than 1500 bytes are allowed.
Windows: ping 192.168.10.1 -l 1500 –f
Linux: ping -s 1500 -M do 192.168.10.1
Cisco (IOS): ping 192.168.10.1 size 1500 df-bit
For instance, if you try to ping with a larger packet that 1500 with jumboframes disabled somewhere along the path, you’ll see something like this. In my case, when creating this capture, I forgot when using a 9000 byte packet the -f switch and was took me a moment to figure out that my pings were successful because the packet was being fragmented - exactly what we are aiming to avoid. (DOH!)
C:\Users\user>ping 10.2.2.10 -l 1400 -f
Pinging 10.2.2.10 with 1400 bytes of data:
Reply from 10.2.2.10: bytes=1400 time=1ms TTL=128
Reply from 10.2.2.10: bytes=1400 time=1ms TTL=128
Reply from 10.2.2.10: bytes=1400 time=1ms TTL=128
Reply from 10.2.2.10: bytes=1400 time=1ms TTL=128
Ping statistics for 10.2.2.10:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 1ms, Maximum = 1ms, Average = 1ms
C:\Users\user>ping 10.2.2.10 -l 9000 -f
Pinging 10.2.2.10 with 9000 bytes of data:
Packet needs to be fragmented but DF set.
Packet needs to be fragmented but DF set.
Packet needs to be fragmented but DF set.
Packet needs to be fragmented but DF set.
As everyone mentioned above - Jumbos can help a bit - but there are a few things I thing you should be aware of.
If there is a jumbo frame setting mismatch anywhere along the route the job could fail as the proxy won’t be able to make a stable connection anywhere along the way (i’ve seen this plenty).
Even if you increase the network transmission speed your bottleneck will still most likely will be the DD target - this will be especially true on restores. The DD will need to be able to injest the data fast enough and then dedupe it and write it faste to keep up with the extra data coming through the network.
On restores the DD will be the bottleneck as it has to support enough red I/O in order to send enough packets across the JF to make a difference.
So like @JMeixner said above - YMMV.
@dloseke - Great post.
I have had to use many of those commands before where my expected result wasn’t correct. Now everything on the “infrastructure” side uses jumbo frames but it’s always good to run a check every once in a while.
The only caution I’d have to using it for Veeam, is the proxy servers. Repos are easy, and changing it on the Proxies is easy however, depending on your backup method things can change.
Is it using the VMware management port? Was that configured?
are you doing file level restores direct to servers?
Is your proxy a VM/physical?
Is your mount server using jumbo frames?
Is your workstation using jumbo frames?
It’s so easy to miss something, but almost everything should support it these days.
When I have a dedicated purpose, like SAN replication it’s easy to configure both sides.
It will improve the performance specially with Oracle Agent backup or Oracle Plugin backup, because it is one of the requirements
It will improve the performance specially with Oracle Agent backup or Oracle Plugin backup, because it is one of the requirements
Interesting comment, do you have any Veeam Doc as source? Or just a feedback from the field or lab?
It will improve the performance specially with Oracle Agent backup or Oracle Plugin backup, because it is one of the requirements
Interesting comment, do you have any Veeam Doc as source? Or just a feedback from the field or lab?
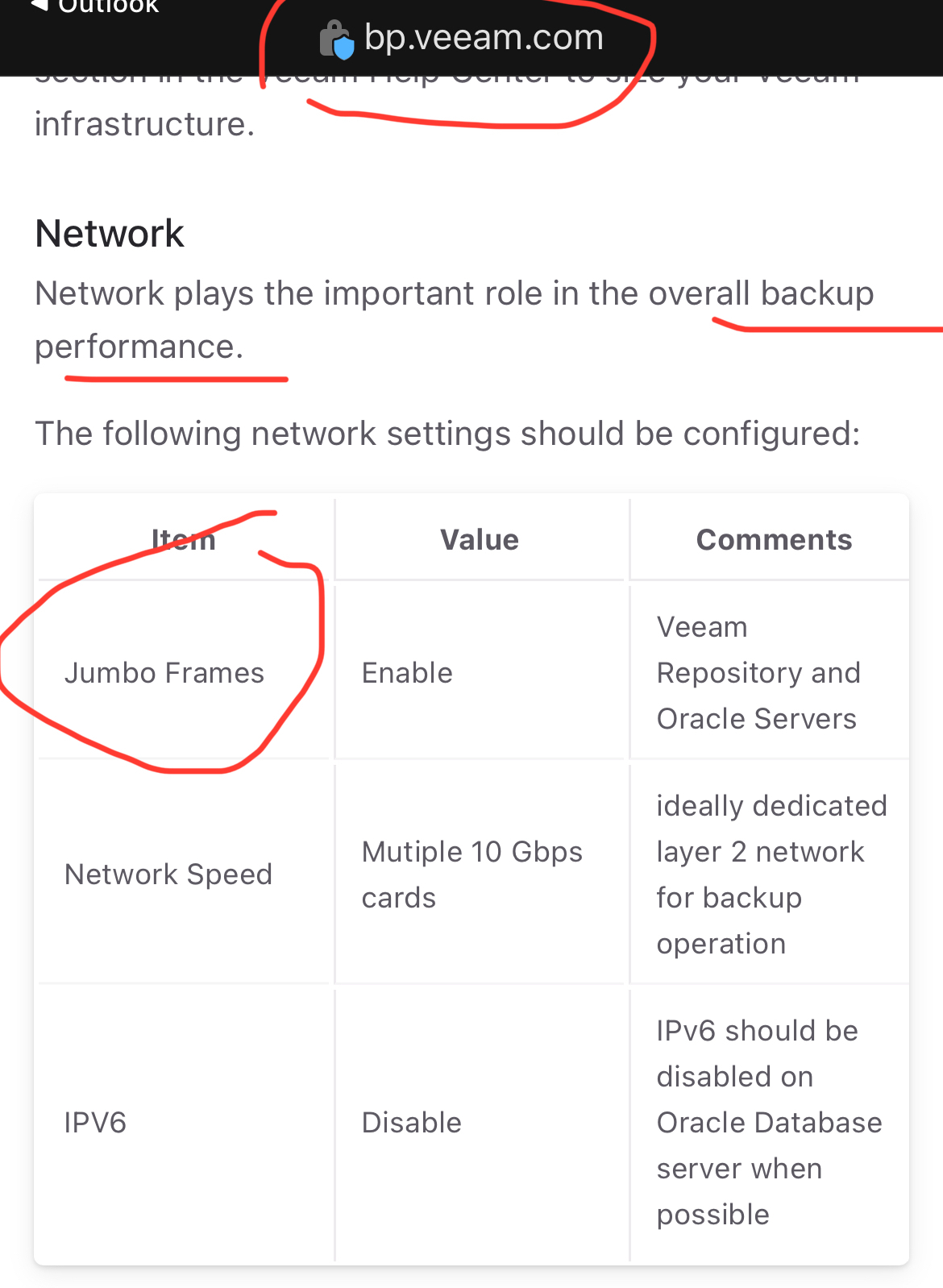
Hello @BertrandFR
Please check below screenshot from Veeam Best Practices doc
Thanks for sharing @Moustafa_Hindawi , it’s general network best practices as discussed in this topic.
Just to follow up on that. Even with jumbo frames YMMV. I was doing extensive troubleshooting on AIX based RMAN to Windows repositories before. Root cause was a bug but it was useful to get into the deep network settings all the same.
Test environment:
Windows Repositories: 2x 40GbE networking, dual RAID 60’s per SOBR node with independent RAID controllers and 28 SAS disks per RAID controller, two SOBR extents per node (1x per RAID controller), two nodes
AIX RMAN: 2x 10GbE networking per server, all flash source storage via FC
During our testing, we omitted Veeam to focus on pure network throughput and then layered Veeam testing on top as we saw improvements. Jumbo frames provided no increase in throughput at all, (we were measuring in Gbps immediately so if there was some it wasn’t enough to move a decimal point on this…) but the differences in TCP window scaling between the Windows and AIX servers provided to be the single biggest improvement in throughput we could make. AIX by default isn’t well tuned to 10Gbps+ speeds with regards to its TCP window scaling and increasing this to match Windows was a dramatic improvement!