Hey Guys,
Sorry for the weekend help, I am just too excited to leave VEEAM alone
I have googled and read other forum discussions to this topic but they all point towards a service not being started and in my case, everything is running, and I have rebooted everything also
coming here for some help
I am in no rush this weekend, this can wait until Monday
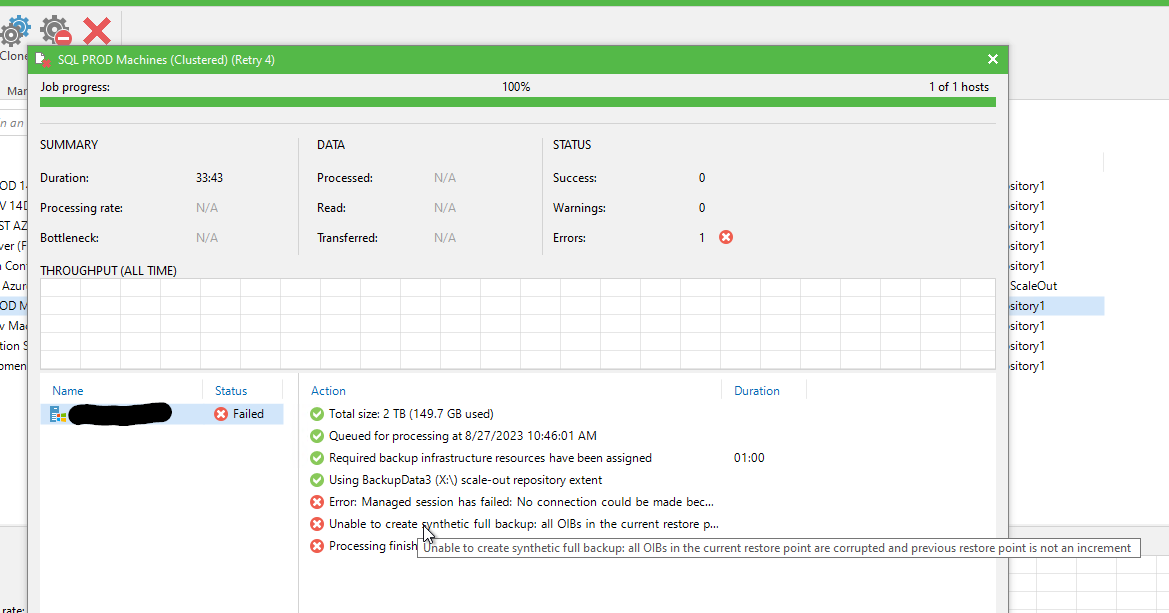
Error message: Error: Managed session has failed: No connection could be made because the target machine actively refused it x.x.x.x:10005
Thanks in advance guys,